Elasticsearch7.4.2批量导入数据,语法使用demo
1、导入批量数据
通过此链接的数据拷贝出(https://github.com/elastic/elasticsearch/blob/master/docs/src/test/resources/accounts.json)
将json数据复制到kibana,使用kibana控制台执行保存到es。
#批量导入测试数据
POST /bank/account/_bulk
2、SerrchAPI查询
es支持两种基本方式检索:
- 一个是通过REST request URI 发送搜索参数(uri + 检索参数)
- 另一个是通过使用 REST request body 来发送它们(uri + 请求体)
1)uri + 检索参数
q=* 查询所有,sort=account_number:ase 根据account_number排序
GET bank/_search?q=*&sort=account_number:ase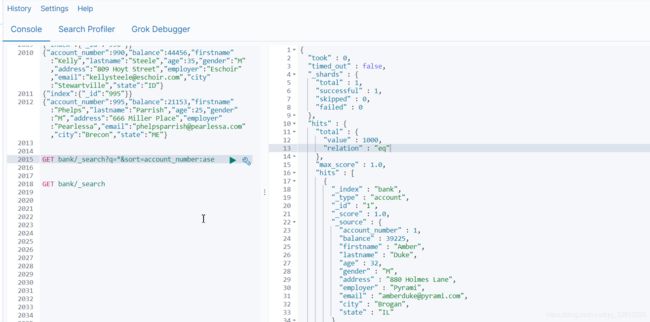
2)uri + 请求体
GET bank/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"account_number": {
"order": "desc"
}
}
]
}

响应结果解释:
- took- Elasticsearch执行搜索的时间(臺秒)
- time_out-告诉我们搜索是否超时
- _shards-告诉我们多少个分片被搜索了,以及统计了成功失败的搜索分片
- hits-搜索结果
- hits. total-搜索结果
- hits.hits-实际的搜索结果数组(默认为前10的文档)
- sort结果的排序key(键)(没有则按scoe排序)
- score和 max score-相关性得分和最高得分(全文检索用)
3、match相关查询
- match匹配查询,基本类型(非字符串),精确匹配
#全文检索按照评分进行评分,会对检索条件进行分词匹配
#根据account_number查询
GET bank/_search
{
"query": {
"match": {
"account_number": 20
}
}
}
#根据balance查询
GET bank/_search
{
"query": {
"match": {
"balance": 16418
}
}
}
- match_phrase短语匹配,将需要匹配的值当成一个整体单词(不分词)进行检索
#查出address中包含 mill road 的所有记录,并给出相关性得分
GET bank/_search
{
"query": {
"match_phrase": {
"address": "mill road"
}
}
}

- multi_match多字段匹配
#address或者state 包含 mill
GET bank/_search
{
"query": {
"multi_match": {
"query": "mill",
"fields": ["address","state"]
}
}
}

- bool复合查询
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"gender": "M"
}
},
{
"match": {
"address": "mill"
}
}
],
"must_not": [
{"match": {
"age": "28"
}}
],
"should": [
{"match": {
"lastname": "Wallace"
}}
]
}
}
}
| 事件 | 描述 |
| must | 文档必须完全匹配条件,并将有助于得分 |
| should | should下面会带一个以上的条件,至少满足一个条件,这个文档就符合should |
| must_not | 文档必须不匹配条件 |
| filter | 子句必须出现在匹配的文档中,然而不像must此查询的分数将被忽略 |

- filter结果过滤
#filter和must大致相同,唯一区别是must有评分,而filter只是作为过滤,所以filter性能优于must
GET bank/_search
{
"query": {
"bool": {
"filter": {
"range": {
"age": {
"gte": 18,
"lte": 30
}
}
}
}
}
}
- term查询
#和 match一样。匹配某个属性的值。全文检索字段用 match,其他非text字段匹配用term
#为了更好地搜索text字段,match查询还将在执行搜索之前分析您提供的搜索词。这意味着match查询可以在text字段中搜索 分析的标记,而不是确切的词。
#该term查询并没有分析搜索词。该term查询仅搜索您提供的确切术语。这意味着term搜索text字段时查询可能返回差的结果或没有结果。
GET bank/_search
{
"query": {
"term": {
"age": "28"
}
}
}
GET bank/_search
{
"query": {
"term": {
"address": "789 Madison Street"
}
}
}
GET bank/_search
{
"query": {
"match": {
"address.keyword": "789 Madison Street" #精确匹配
}
}
}

- aggregations(执行聚合)
聚合提供了从数据中分组和提取数据的能力。最简单的聚合方法大致等于 SQL GROUPBY和saL聚合函数。在Elasticsearch中,您有执行搜索返回hits(命中结果),并且同时返回聚合结果,把一个响应中的所有hits(命中结果)分隔开的能力。这是非常强大且有效的,您可以执行查询和多个聚合,并且在一次使用中得到各自的(任何一个的)返回结果,使用次简洁和简化的A이来避免网络往返。
#搜索 address中包含mil的所有人的年龄分布以及平均年龄,但不显示这些人的详情。
GET bank/_search
{
"query": {
"match": {
"address": "mill"
}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 10
}
},
"ageAvg":{
"avg": {
"field": "age"
}
},
"balanceAvg":{
"avg": {
"field": "balance"
}
}
},
"size": 0 size=0是不显示搜索数据
}

#按照年龄聚合,并且请求这些年龄段的这些人的平均薪资
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 100
},
"aggs": {
"ageAvg": {
"avg": {
"field": "balance"
}
}
}
}
}
}
#查出所有年龄分布,并且这些年龄段中M的平均薪资和F的平均薪资以及这个年龄段的总体平均资
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 100
},
"aggs": {
"genderAgg":{
"terms": {
"field": "gender.keyword",
"size": 10
},
"aggs": {
"balanceAvg": {
"avg": {
"field": "balance"
}
}
}
},
"ageBalanceAvg":{
"avg": {
"field": "balance"
}
}
}
}
}
}
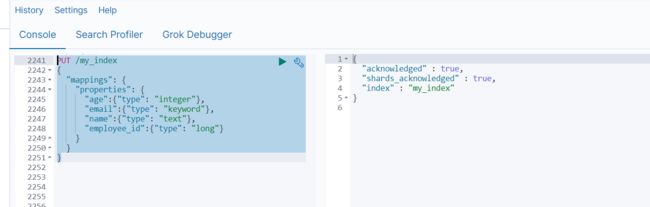
- 添加映射
PUT /my_index
{
"mappings": {
"properties": {
"age":{"type": "integer"},
"email":{"type": "keyword"},
"name":{"type": "text"},
"employee_id":{"type": "long"}
}
}
}
- 添加新的字段映射
PUT /my_index/_mapping
{
"properties": {
"firstname":{"type": "keyword","index": false}
}
}
- 修改映射&数据迁移
对于已经存在的映射字段,我们不能更新,更新必须创建新的索引进行数据迁移。
1) 查询bank的映射
GET /bank/_mapping
2) 添加新的映射
PUT /newbank
{
"mappings": {
"properties": {
"account_number": {
"type": "long"
},
"address": {
"type": "text"
},
"age": {
"type": "integer"
},
"balance": {
"type": "long"
},
"city": {
"type": "keyword"
},
"email": {
"type": "keyword"
},
"employer": {
"type": "keyword"
},
"firstname": {
"type": "text"
},
"gender": {
"type": "keyword"
},
"lastname": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"state": {
"type": "keyword",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
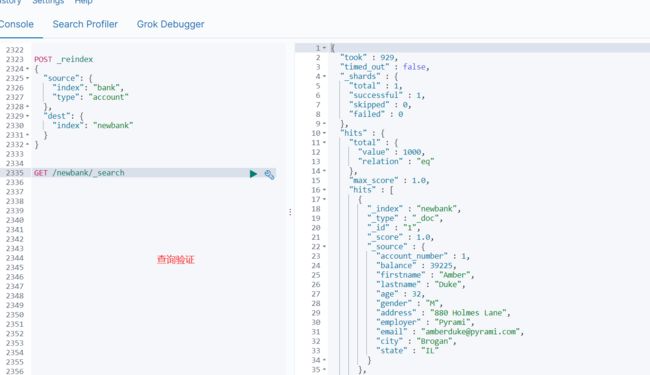
3) 数据迁移
POST _reindex #固定写法
{
"source": {
"index": "bank",
"type": "account"
},
"dest": {
"index": "newbank"
}
}
4、主要类型
- 字符串类型:string,text,keyword
- 整数类型:integer,long,short,byte
- 浮点类型:double,float,half_float,scaled_float
- 逻辑类型:boolean
- 日期类型:date
- 范围类型:range
- 二进制类型:binary
- 数组类型:array
- 对象类型:object
- 嵌套类型:nested
- 地理坐标类型:geo_point
- 地理地图:geo_shape
- IP类型:ip
- 范围类型:completion
- 令牌计数类型:token_count
5、索引的一些基本操作
- 查看集群健康:GET http://localhost:9200/_cluster/health
- 创建索引:PUT http://localhost:9200/index_test
- 查看索引:GET http://localhost:9200/_cat/indices?v
- 删除索引:DELETE http://localhost:9200/index_test
6、文档的乐观锁
当查询、插入、更新一条数据的时候都能看到有一个_version属性,这个属性标识当前数据的版本号,老版本中通过这个属性实现乐观锁,只需要在请求最后加上版本号就可以了
老版本
使用post请求访问 127.0.0.1:9200/索引名/_doc/id/_update?version={数值}
新版本
使用post请求访问 127.0.0.1:9200/索引名/_doc/id/_update?if_seq_no={数值}&if_primary_term={数值}
_seq_no:文档版本号,作用同_version(文档所有位置内部的编号,效率更加高效,管理起来更方便)
_primary_term:文档所在位置