Galera Cluster for MySQL 详解(三)——管理监控
目录
一、管理
1. 在线DDL
(1)TOI
(2)RSU
(3)pt-online-schema-change
2. 恢复主组件
(1)了解主组件状态
(2)修改保存的主组件状态
3. 重置仲裁
(1)查找最高级的节点
(2)重置仲裁
(3)自动引导
(4)手动引导
4. 管理流控
(1)监控流控
(2)配置流控
5. 自动逐出
(1)配置自动逐出
(2)检查收回状态
6. Galera仲裁员
(1)从shell启动Galera仲裁程序
(2)启动Galera仲裁员服务
(3)脑裂测试
二、监控
1. 使用状态变量
(1)检查集群完整性
(2)检查节点状态
(3)检查复制运行状况
(4)检测网络
2. 使用通知脚本
(1)通知参数
(2)启用通知脚本
3. 使用数据库服务器日志
参考:
一、管理
1. 在线DDL
MySQL上在线执行DDL语句(create table、alter table、create index、grant ...)一直是个令人头疼的操作。一方面大表上的DDL语句需要执行很长时间,这是因为MySQL的实现,它需要复制一遍表的数据。另一方面在高并发访问的表上执行DDL期间会阻塞其上所有DML(insert、update、delete)语句的执行,直到DDL语句执行完。不但如此,高并发大表上的在线DDL还极易产生经典的“Waiting for table metadata lock”等待。
Galera集群也同样如此,来看下面的例子。
-- 创建测试表并装载大量数据
create table t1 as select * from information_schema.tables;
insert into t1 select * from t1;
...
insert into t1 select * from t1;
-- 创建主键
alter table t1 add column id int auto_increment primary key first;
-- 在session 1中执行加字段的DDL
alter table t1 add column c1 int;
-- 在session 1的语句执行期间,在session 2中执行插入记录的DML
insert into t1 (table_catalog,table_schema,table_name,table_type,table_comment) values('a','a','a','a','a');session 2的DML语句会立即返回以下错误,直到session 1的DDL语句完成,insert语句才能执行成功。
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transactionDDL语句更改数据库本身,并且是非事务性的(自动提交)。Galera群集通过两种不同的方法处理DDL:
- 总序隔离(Total Order Isolation,TOI):以相同顺序在所有集群节点上执行DDL,防止在操作期间提交其它事务。
- 滚动升级(Rolling Schema Upgrade,RSU):在本地执行DDL,仅影响运行这些更改的节点,更改不会复制到集群的其余部分。
可以配置wsrep_osu_method参数指定下线DDL方法,缺省设置为TOI。DDL涉及到的是表锁及MDL锁(Meta Data Lock),只要在执行过程中,遇到了MDL锁的冲突,所有情况下都是DDL优先,将所有使用到这个对象的事务统统杀死,被杀的事务都会报出死锁异常,正如前面例子中看到的报错。
(1)TOI
如果并不关心集群处理DDL语句时其它事务将被阻止,可使用TOI方法。DDL作为语句复制到群集中的所有节点,节点等待前面的所有事务同时提交,然后单独执行DDL更改。在DDL处理期间,不能提交其它事务。这种方法的主要优点是它保证了数据的一致性。在使TOI时应考虑以下特性:
- 从事务验证的角度来看,TOI模式永远不会与前面的事务冲突,因为它们只在集群提交所有前面的事务之后执行。因此DDL更改永远不会使验证失败,并且它们的执行是有保证的。
- DDL运行时正在进行的事务以及涉及相同数据库资源的事务将在提交时报出死锁错误,并将回滚。
- 集群在执行DDL之前将其复制为语句,无法知道单个节点是否成功处理该DDL。TOI可防止单个节点的DDL执行出错。
(2)RSU
如果要在DDL期间保持高可用性,并且避免新、旧结构定义之间的冲突,则应该使用RSU方法。可以使用set语句执行此操作:
set global wsrep_osu_method='RSU';RSU仅在本地节点上处理DDL。当节点处理表结构更改时,它将与集群解除同步。处理完表结构更改后,它将应用延迟的复制事件并将自身与群集同步。若要在整个集群范围内更改表结构,必须依次在每个节点上手动执行DDL。在RSU期间,集群将继续运行,其中一些节点使用旧表结构,而另一些节点使用新表结构。RSU的主要优点是一次只阻塞一个节点,主要缺点是可能不安全,如果新结构和旧结构定义在复制事件级别不兼容,则可能会失败。例如:
-- 在节点1执行
set wsrep_osu_method='RSU';
alter table t1 add column c1 int;
insert into t1(c1) select 1;
-- 在节点2执行
alter table t1 add column c1 int;节点1向t1.c1字段插入值时,节点2上并没有t1.c1字段,因此数据复制失败。当在节点2上手动执行DDL添加t1.c1字段后,两节点数据不一致。
(3)pt-online-schema-change
RSU只避免了执行DDL的节点对其它节点的阻塞,但对于同一节点上DDL与DML的相互影响问题却无能为力。在当前阶段,解决非阻塞在线DDL的终极解决方案是使用pt-online-schema-change。
pt-online-schema-change是percona-toolkit中的一个工具,功能是无锁定在线修改表结构,要求被修改表具有主键或唯一索引。percona-toolkit工具包的安装和使用非常简单。例如,从https://www.percona.com/downloads/percona-toolkit/LATEST/下载percona-toolkit,然后执行下面的命令进行安装:
# 安装依赖包
yum install perl-TermReadKey.x86_64
yum install perl-DBI
yum install perl-DBD-MySQL
yum install perl-Time-HiRes
yum install perl-IO-Socket-SSL
# 安装percona-toolkit
rpm -ivh percona-toolkit-3.1.0-2.el7.x86_64.rpm执行类似下面的命令修改表结构:
pt-online-schema-change --alter="add column c1 int;" --execute D=test,t=t1,u=root,p=P@sswo2dalter参数指定修改表结构的语句,execute表示立即执行,D、t、u、p分别指定库名、表名、用户名和密码,执行期间不阻塞其它并行的DML语句。pt-online-schema-change还有许多选项,具体用法可以使用pt-online-schema-change --help查看联机帮助。官方文档链接为:https://www.percona.com/doc/percona-toolkit/LATEST/pt-online-schema-change.html。
pt-online-schema-change工作原理其实很简单:
- 如果存在外键,根据alter-foreign-keys-method参数的值,检测外键相关的表,做相应设置的处理。如果被修改表存在外键定义但没有使用 --alter-foreign-keys-method 指定特定的值,该工具不予执行。
- 创建一个新的表,表结构为修改后的数据表,用于从源数据表向新表中导入数据。
- 创建触发器,用于记录从拷贝数据开始之后,对源数据表继续进行数据修改的操作记录下来,数据拷贝结束后,执行这些操作,保证数据不会丢失。如果表中已经定义了触发器这个工具就不能工作了。
- 拷贝数据,从源数据表中拷贝数据到新表中。
- 修改外键相关的子表,根据修改后的数据,修改外键关联的子表。
- rename源数据表为old表,把新表rename为源表名,并将old表删除。
- 删除触发器。
2. 恢复主组件
群集节点将主组件状态存储到本地磁盘。节点记录主组件的状态以及连接到它的节点的uuid。中断情况下,一旦最后保存状态中的所有节点都实现连接,集群将恢复主组件。如果节点之间的写集位置不同,则恢复过程还需要完整状态快照传输(SST)。关于主组件的概念参见https://wxy0327.blog.csdn.net/article/details/102522268#%E4%B8%83%E3%80%81%E4%BB%B2%E8%A3%81。
(1)了解主组件状态
节点将主组件状态存储到磁盘时,会将其保存在MySQL数据目录下的gvwstate.dat文件中,内容如下所示。
[root@hdp2/var/lib/mysql]#more /var/lib/mysql/gvwstate.dat
my_uuid: 4a6cfe9d-f9de-11e9-9ad4-23840b115384
#vwbeg
view_id: 3 4a6cfe9d-f9de-11e9-9ad4-23840b115384 3
bootstrap: 0
member: 4a6cfe9d-f9de-11e9-9ad4-23840b115384 0
member: 78bdb344-f9de-11e9-bcfa-eb03d339c6d7 0
member: 7d14464b-f9de-11e9-83b3-5b022ee44499 0
#vwend
[root@hdp2/var/lib/mysql]#gvwstate.dat文件分为节点信息和视图信息两部分。节点信息在my_uuid字段中提供节点的uuid。视图信息提供有关节点所属主组件视图的信息,该视图包含在vwbeg和vwend标记之间。view_id 从三个部分构成视图的标识符:view_type 始终为3,表示主视图,view_uuid和view_seq一起构成标识符唯一值;bootstrap 显示节点是否已引导,不影响主组件恢复过程;member 显示此主组件中节点的uuid。
当群集形成或更改主组件时,节点创建并更新此文件,这将确保节点保留其所在的最新主组件状态。如果节点失去连接,则它具有要引用的文件。如果节点正常关闭,则会删除该文件。
(2)修改保存的主组件状态
如果集群处于需要强制特定节点彼此连接的异常情况,可以通过手动更改保存的主组件状态来执行此操作。注意,正常情况下应完全避免编辑或修改gvwstate.dat文件,因为这样做可能会导致意想不到的结果。
当一个节点第一次启动或在正常关机后启动时,它会随机生成一个uuid并将其分配给自己,该uuid用作集群其余部分的标识符。如果节点在数据目录中找到gvwstate.dat文件,它将读取my_uuid字段以找到它应该使用的值。通过手动将任意uuid值分配给每个节点上的相应字段,可以强制它们在开始时相互连接,形成一个新的主组件。下面看一个例子。
首先停止实验环境三节点Galera集群中的所有MySQL实例:
systemctl stop mysqld然后在任意节点启动MySQL实例都会报错:
[root@hdp2/var/lib/mysql]#systemctl start mysqld
Job for mysqld.service failed because the control process exited with error code. See "systemctl status mysqld.service" and "journalctl -xe" for details.
[root@hdp2/var/lib/mysql]#日志中显示如下错误:
2019-10-29T00:19:11.470690Z 0 [ERROR] WSREP: failed to open gcomm backend connection: 110: failed to reach primary view: 110 (Connection timed out)
at gcomm/src/pc.cpp:connect():158
2019-10-29T00:19:11.470710Z 0 [ERROR] WSREP: gcs/src/gcs_core.cpp:gcs_core_open():209: Failed to open backend connection: -110 (Connection timed out)
2019-10-29T00:19:11.470912Z 0 [ERROR] WSREP: gcs/src/gcs.cpp:gcs_open():1458: Failed to open channel 'mysql_galera_cluster' at 'gcomm://172.16.1.125,172.16.1.126,172.16.1.127': -110 (Connection timed out)
2019-10-29T00:19:11.470931Z 0 [ERROR] WSREP: gcs connect failed: Connection timed out
2019-10-29T00:19:11.470941Z 0 [ERROR] WSREP: wsrep::connect(gcomm://172.16.1.125,172.16.1.126,172.16.1.127) failed: 7
2019-10-29T00:19:11.470968Z 0 [ERROR] Aborting很明显实例启动时取不到主组件视图。由于三个节点中至少有两个活跃节点才能构成主组件,但现在一个实例都不存在,而且节点找不到集群主组件信息,致使节点无法启动。
我们希望三个节点一起启动以形成集群的新主组件。此时需要为每个节点提供一个任意唯一的uuid值,例如在其它可用的MySQL上执行select uuid()来获得。下面手工生成三个节点的gvwstate.dat文件。
节点1上的gvwstate.dat文件内容如下:
my_uuid: 9085dadf-f953-11e9-92e9-005056a50f77
#vwbeg
view_id: 3 9085dadf-f953-11e9-92e9-005056a50f77 3
bootstrap: 0
member: 9085dadf-f953-11e9-92e9-005056a50f77 0
member: 8e2de005-f953-11e9-88b4-005056a5497f 0
member: 7dc3eb7e-f953-11e9-ad17-005056a57a4e 0
#vwend然后对节点2重复该过程:
my_uuid: 8e2de005-f953-11e9-88b4-005056a5497f
#vwbeg
view_id: 3 9085dadf-f953-11e9-92e9-005056a50f77 3
bootstrap: 0
member: 9085dadf-f953-11e9-92e9-005056a50f77 0
member: 8e2de005-f953-11e9-88b4-005056a5497f 0
member: 7dc3eb7e-f953-11e9-ad17-005056a57a4e 0
#vwend节点3也一样:
my_uuid: 7dc3eb7e-f953-11e9-ad17-005056a57a4e
#vwbeg
view_id: 3 9085dadf-f953-11e9-92e9-005056a50f77 3
bootstrap: 0
member: 9085dadf-f953-11e9-92e9-005056a50f77 0
member: 8e2de005-f953-11e9-88b4-005056a5497f 0
member: 7dc3eb7e-f953-11e9-ad17-005056a57a4e 0
#vwend下面启动第一个节点:
systemctl start mysqld当节点启动时,Galera集群将读取每个节点的gvwstate.dat文件,从中提取其uuid并使用member字段的uuid来确定它应该连接哪些节点以形成新的主组件。但此时该命令执行的现象是“挂起”。现在集群中还没有主组件,该节点正在等待SST完成,正如日志中所显示的:
2019-10-29T00:41:31.058586Z 0 [Note] WSREP: Received NON-PRIMARY.
2019-10-29T00:41:31.058596Z 0 [Note] WSREP: Waiting for SST to complete.
2019-10-29T00:41:31.058995Z 2 [Note] WSREP: New cluster view: global state: 4a6db23a-f9de-11e9-ba76-93e71f7c9a45:3, view# -1: non-Primary, number of nodes: 1, my index: 0, protocol version -1
2019-10-29T00:41:31.059022Z 2 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2019-10-29T00:41:31.558645Z 0 [Warning] WSREP: last inactive check more than PT1.5S ago (PT3.50285S), skipping check下面启动第二个节点:
systemctl start mysqld依然“挂起”,日志中显示的同节点1一样。
最后启动第三个节点:
systemctl start mysqld此时第三个节点和前面正在启动中的两个节点同时启动成功。只有当主组件包含的所有节点都启动后才能确定SST的方向,继而完成整个集群的启动。
3. 重置仲裁
在网络连接出现问题,或超过一半的集群出现故障,或出现脑裂等情况时,可能会发现节点不再将自己视为主组件的一部分。可以检查wsrep_cluster_status变量是否发生这种情况。在每个节点上运行以下查询:
mysql> show global status like 'wsrep_cluster_status';
+----------------------+---------+
| Variable_name | Value |
+----------------------+---------+
| wsrep_cluster_status | Primary |
+----------------------+---------+
1 row in set (0.00 sec)返回值primary表示节点是主组件的一部分。当查询返回任何其它值时,表示节点是不可操作组件的一部分。这种情况的节点会向所有应用查询返回未知命令的错误。如果没有任何节点返回primary,则意味着需要重置仲裁,这种情况是非常少见的。如果有一个或多个返回primary的节点,则表示是网络连接出现问题,而不是需要重置仲裁。一旦节点重新获得网络连接,它们就会自动与主组件重新同步。
(1)查找最高级的节点
重置仲裁前需要标识群集中最高级的节点。也就是说,必须找到本地数据库提交了最后一个事务的节点。无论重置仲裁时使用何种方法,此节点都将作为新主组件的起点。可以使用wsrep_last_committed状态变量识别集群中最高级的节点。在每个节点上运行以下查询:
mysql> show status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 392 |
+----------------------+-------+
1 row in set (0.00 sec)返回值是该节点提交的最后一个事务的序号,序号最大的节点是集群中最高级的节点,将被用作引导新主组件时的起点。
(2)重置仲裁
重置仲裁所做的是在可用的最高级节点上引导主组件,然后该节点作为新的主组件运行,使集群的其余部分与其状态保持一致。有自动和手动两种方法完成仲裁重置,首选方法是自动方法。自动引导在每个节点上保留写集缓存gcache,这意味着当新主组件启动时,可以使用增量状态转移(IST)而不是速度慢得多的状态快照转移(SST)进行自我配置。
(3)自动引导
重置仲裁将主组件引导到最高级的节点上。在自动方法中,这是通过在wsrep_provider_options参数下动态启用pc.bootstrap来完成的。要执行自动引导,在最高级节点的数据库上执行以下命令:
set global wsrep_provider_options='pc.bootstrap=yes';
该节点现在作为新主组件中的起始节点运行。如果可能,具有网络连接的不可操作组件中的节点将尝试启动增量状态传输,如果不可能,则使用状态快照传输,以使其自己的数据库保持最新。
(4)手动引导
手动引导时中,首先需要关闭群集,然后从最高级的节点开始重新启动群集。手动引导群集需要完成以下步骤:
1. 关闭所有群集节点。
systemctl stop mysqld2. 使用--wsrep-new-cluster选项启动最高级的节点。
/usr/bin/mysqld_bootstrap如果mysqld_bootstrap命令将执行失败,并且日志中显示以下错误信息:
2019-10-29T02:17:41.041493Z 0 [ERROR] WSREP: It may not be safe to bootstrap the cluster from this node. It was not the last one to leave the cluster and may not contain all the updates. To force cluster bootstrap with this node, edit the grastate.dat file manually and set safe_to_bootstrap to 1 .
2019-10-29T02:17:41.041501Z 0 [ERROR] WSREP: wsrep::connect(gcomm://172.16.1.125,172.16.1.126,172.16.1.127) failed: 7
2019-10-29T02:17:41.041511Z 0 [ERROR] Aborting说明该节点可能不是最高级节点。Galera认为这种情况下bootstrap是不安全的,因为可能丢失事务。如果要强制执行引导,可以编辑grastate.dat文件,将safe_to_bootstrap设置为1,然后再执行mysqld_bootstrap命令。
3. 逐次启动群集中的其它节点。
systemctl start mysqld当第一个节点以--wsrep-new-cluster选项开始时,它使用前一个集群中可用的最高级状态的数据初始化一个新集群。当其它节点启动时,它们会连接到此节点并请求状态快照传输,以使自己的数据库保持最新。
4. 管理流控
集群通过全局排序同步复制更改,但从原始节点异步应用这些更改。为了防止任何一个节点落后集群太多,Galera集群实现了一种称为流控的反馈机制。节点将接收到的写集按全局顺序排队,并开始在数据库中应用和提交它们。如果接收到的队列太大,节点将启动流控,此时节点将暂停复制而处理接收队列。一旦接收队列减小到一个阈值,节点就会恢复复制。
(1)监控流控
Galera群集提供全局状态变量用于监视流控,这些变量分为计数流控暂停事件的状态变量和记录暂停复制时长的状态变量。
mysql> show status like 'wsrep_flow_control_%';
+------------------------------+----------+
| Variable_name | Value |
+------------------------------+----------+
| wsrep_flow_control_paused_ns | 0 |
| wsrep_flow_control_paused | 0.000000 |
| wsrep_flow_control_sent | 0 |
| wsrep_flow_control_recv | 0 |
+------------------------------+----------+
4 rows in set (0.01 sec)流控使用fc_pause事件通知群集它正在暂停复制。Galera集群提供了两个状态变量来监视此事件。
- wsrep_flow_control_sent:显示自上次状态查询以来本地节点发送的流控暂停事件数。
- wsrep_flow_control_recv:显示自上次状态查询以来群集上的流控暂停事件数,包括来自其它节点的事件数和本地节点发送的事件数。
除了跟踪流控暂停事件数之外,Galera集群还可以跟踪自上次 FLUSH STATUS 以来由于流控而暂停复制的时长。
- wsrep_flow_control_paused:暂停复制的时长。
- wsrep_flow_control_paused_ns:以纳秒为单位暂停复制的时长。
(2)配置流控
Galera集群提供了两组参数管理节点如何处理复制速率和流控,一组控制写集缓存,另一组涉控制流控的触发或取消条件。以下三个参数控制节点如何响应复制速率的更改。
- gcs.recv_q_hard_limit:设置最大接收队列的大小,单位是字节。参数值取决于内存、交换区大小和性能考虑。在32位系统上,缺省值为ssize_max减2GB。64位系统没有实际限制,缺省值为LLONG_MAX。如果某个节点超过此限制,并且gcs.max_throttle未设置为0.0,则该节点将因内存不足错误而中止。如果gcs.max_throttle设置为0.0,则群集中的复制将停止。
- gcs.max_throttle:限制状态传输期间的复制速率,以避免耗尽内存,缺省值为0.25。如果将参数设置为1.0,则节点不会限制复制速率。如果将参数设置为0.0,则可以完全停止复制。
- gcs.recv_q_soft_limit:缺省值为0.25。当复制速率超过软限制时,节点计算在此期间的平均复制速率(以字节为单位)。之后,节点会随着缓存大小线性降低复制速率,以便在recv_q_hard_limit下达到gcs.max_throttle乘以平均复制速率的值。
以下参数控制节点触发流控的条件以及用于确定何时应断开流控并恢复复制。
- gcs.fc_limit:此参数确定流控触发点。当接收队列中的事务数超过此限制时,节点将暂停复制,缺省值为16。对于多主配置,必须将此限制保持在较低值,以减少验证冲突。如果是主从设置,可以使用更高的值来减少流控干预,减少从库复制延迟。
- gcs.fc_factor:此参数用于确定节点何时可以取消流控,缺省值为1。当节点上的接收队列低于gcs.fc_limit * gcs.fc_factor的值时将恢复复制。
虽然使用尽可能小的接收队列对于多主操作来说非常重要,但接收列长度在主从设置中并不是那么重要。根据应用程序和硬件的不同,节点可能在几秒钟内应用1k个写集。接收队列长度对故障转移没有影响。
集群节点彼此异步处理事务,节点不能以任何方式预期复制数据的数量,因此流控总是被动的。也就是说,流控只有在节点超过某些限制后才会生效,它并不能防止超过这些限制。
5. 自动逐出
当Galera集群发现某个节点出现异常,如很长的响应时间时,可以启动一个进程将该节点从集群中永久删除,此过程称为自动逐出。
(1)配置自动逐出
群集中的每个节点监视群集中所有其它节点的组通信响应时间。当集群从一个节点响应延时,它会向延迟列表中生成一个关于该节点的条目。如果延迟节点在固定时间内再次响应,则该节点的条目将从延迟列表中移除。但如果节点接收到足够多的延迟条目,并且在大多数集群的延迟列表中都可以找到该条目,则会将延迟节点从集群中永久逐出,被逐出的节点重启后才能重新加入群集。
通过wsrep_provider_options设置以下选项,可以配置自动逐出的参数:
- evs.delayed_margin:节点响应时间大于该参数定义的时长,则将条目添加到延迟列表,缺省为1秒。必须将此参数设置为高于节点之间的往返延时(Round-trip time,RTT)的值。
- evs.delayed_keep_period:从被添加到延迟列表,到此参数定义的时间范围内,如果该节点再次响应,则将其从延迟列表条目中删除,缺省为30秒。
- evs.evict:如果设置为某个节点的UUID,则该节点将从集群中逐出。
- evs.auto_evict:定义节点在触发自动逐出协议之前允许的延迟节点条目数,缺省值为0,表示禁用节点上的自动逐出协议,但集群继续监视节点响应时间。
- evs.version:此参数确定节点使用的EVS协议的版本。为了确保向后兼容,缺省值为0。启用自动逐出需要将改参数设置为更高版本,例如在配置文件中添加:
wsrep_provider_options="evs.version=1"
(2)检查收回状态
可以通过Galera状态变量检查其逐出状态。
- wsrep_evs_state:提供evs协议的内部状态。
- wsrep_evs_delayed:提供延迟列表中以逗号分隔的节点列表。列表中使用的格式是uuid:address:count。计数是指给定延迟节点的条目数。
- wsrep_evs_evict_list:列出被逐出节点的uuid。
6. Galera仲裁员
Galera仲裁员是参与投票但不参与实际复制的群集成员。虽然Galera仲裁员不参与复制,也不存储数据,但它接收的数据与所有其它节点相同,因此必须保证它的网络连接。当集群具有偶数个节点时,仲裁员作为奇数节点发挥作用,以避免出现脑裂的情况。具有仲裁员的集群架构如图1所示。
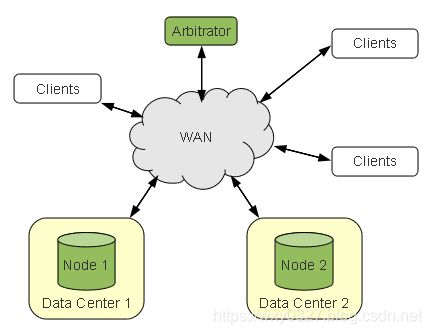 图1 Galera Arbitrator
图1 Galera Arbitrator
Galera仲裁员是Galera集群的一个独立守护进程,名为garbd。这意味着必须从集群单独启动它,并且不能通过my.cnf配置文件配置Galera仲裁员。可以从shell启动仲裁员,或者作为服务运行。如何配置Galera仲裁员取决于如何启动它。
注意,Galera仲裁员启动时,脚本将在进程中以用户nobody身份执行sudo语句。默认的sudo配置将阻止没有tty访问权限的用户操作。要更正此问题,编辑/etc/sudoers文件并注释掉此行:
Defaults requiretty这将防止操作系统阻塞Galera仲裁员。
(1)从shell启动Galera仲裁程序
1. 编辑配置文件arbitrator.config,内容如下:
# arbitrator.config
group = mysql_galera_cluster
address = gcomm://172.16.1.125,172.16.1.126,172.16.1.1272. 启动仲裁员
garbd --cfg /var/lib/mysql/arbitrator.config &(2)启动Galera仲裁员服务
1. 编辑/etc/sysconfig/garb文件,内容如下:
# 已存在的两个节点地址
GALERA_NODES="172.16.1.125:4567 172.16.1.126:4567"
# group名称保持与两节点的wsrep_cluster_name系统变量一致
GALERA_GROUP="mysql_galera_cluster"
# 日志文件
LOG_FILE="/var/log/garb.log"2. 修改日志文件属性
touch /var/log/garb.log
chown nobody:nobody /var/log/garb.log
chmod 644 /var/log/garb.log3. 启动Galera仲裁员服务
systemctl start garb(3)脑裂测试
1. 在节点3停止garb服务。
systemctl stop garb2. 在节点2 drop掉去往第一个节点和仲裁员的数据包。
iptables -A OUTPUT -d 172.16.1.125 -j DROP
iptables -A OUTPUT -d 172.16.1.127 -j DROP3. 检查前节点1、2的状态,都不是Synced,发生了脑裂。
mysql> show status like 'wsrep_local_state_comment';
+---------------------------+-------------+
| Variable_name | Value |
+---------------------------+-------------+
| wsrep_local_state_comment | Initialized |
+---------------------------+-------------+
1 row in set (0.00 sec)4. 清除节点2的数据包过滤规则。
iptables -F5. 启动节点3的garb服务。
systemctl start garb6. 前两个节点查看集群节点数,结果是3,说明包括了仲裁节点。
mysql> show status like 'wsrep_cluster_size';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 3 |
+--------------------+-------+
1 row in set (0.00 sec)7. 在节点2 drop掉去往第一个节点和仲裁员的数据包
iptables -A OUTPUT -d 172.16.1.125 -j DROP
iptables -A OUTPUT -d 172.16.1.127 -j DROP8. 这时检节点1的同步状态,仍然是Synced,没有发生脑裂。
mysql> show status like 'wsrep_local_state_comment';
+---------------------------+--------+
| Variable_name | Value |
+---------------------------+--------+
| wsrep_local_state_comment | Synced |
+---------------------------+--------+
1 row in set (0.00 sec)9. 再在节点1查看集群节点数,结果是2,说明节点1成为集群主组件。
mysql> show status like 'wsrep_cluster_size';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 2 |
+--------------------+-------+
1 row in set (0.00 sec)10. 检查节点2的同步状态和集群节点数,说明它已和集群主组件断开连接。
mysql> show status like 'wsrep_local_state_comment';
+---------------------------+-------------+
| Variable_name | Value |
+---------------------------+-------------+
| wsrep_local_state_comment | Initialized |
+---------------------------+-------------+
1 row in set (0.01 sec)
mysql> show status like 'wsrep_cluster_size';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 1 |
+--------------------+-------+
1 row in set (0.01 sec)二、监控
本节说明监控Galera集群的主要方法,包括查询状态变量、使用脚本监控和检查数据库服务器日志等。
1. 使用状态变量
可以使用标准查询检查整个集群中写集复制的状态:
mysql> show global status like 'wsrep_%';
+------------------------------+----------------------------------------------------------------+
| Variable_name | Value |
+------------------------------+----------------------------------------------------------------+
| wsrep_local_state_uuid | 4a6db23a-f9de-11e9-ba76-93e71f7c9a45 |
| wsrep_protocol_version | 9 |
| ... | ... |
| wsrep_ready | ON |
+------------------------------+----------------------------------------------------------------+
60 rows in set (0.00 sec)下面列举一些需要重点监控的状态变量。
(1)检查集群完整性
可以使用以下状态变量检查群集完整性:
- wsrep_cluster_state_uuid:集群状态uuid,可以使用它确定节点是否属于集群的一部分。群集中的每个节点都应提供相同的值。当一个节点具有不同值时,表示它不再连接到集群。一旦节点重新连接到集群,该状态变量的值变为与集群其它节点一致。
- wsrep_cluster_conf_id:发生群集成员身份更改的总数,可以使用它确定节点是否是主组件的一部分。群集中的每个节点都应提供相同的值。当一个节点具有不同值时,表示集群已经发生网络分区。一旦节点重新连接到集群,该状态变量的值变为与集群其它节点一致。
- wsrep_cluster_size:集群中的节点数量,可以使用它来确定是否缺少节点。当返回值小于集群中的节点数时,表示某些节点已经与集群失去连接。
- wsrep_cluster_status:节点所在的群集主组件状态,可用于确定群集是否处于网络分区状态。节点的返回值只应该为primary,任何其它值都表示该节点是不可操作组件的一部分。这发生在多个成员的变化导致失去法定票数,或脑裂情况下。如果检查群集中的所有节点都不返回Primary,则需要重置仲裁。
当每个节点上的这些状态变量都返回所需结果时,集群具有完整性,这意味着复制可以在每个节点上正常进行。下一步是检查节点状态,以确保它们都处于工作状态并能够接收写集。
(2)检查节点状态
节点状态显示节点是否接收和处理来自群集写集的更新,并可能揭示阻止复制的问题。
- wsrep_ready:节点是否可以接受查询。当节点返回值ON时,它可以接受来自集群的写集。当它返回值OFF时,所有查询都将失败,并出现错误:ERROR 1047 (08501) Unknown Command。
- wsrep_connected:节点是否与任何其它节点连接。当该值为ON时,该节点与构成群集的一个或多个节点连接。当该值为OFF时,该节点没有与任何群集其它节点的连接。连接丢失的原因可能与配置错误有关,例如wsrep_cluster_address或wsrep_cluster_name参数不对。检查错误日志以获得正确的诊断。
- wsrep_local_state_comment:节点状态注释。当节点是主组件的一部分时,典型的返回值是join、waiting on sst、joined、synced或donor。如果节点是不可操作组件的一部分,则返回值为Initialized。如果节点返回除此以外的值,则状态注释是瞬时的,应再次检查状态变量以获取更新。
如果每个状态变量返回所需的值,则节点处于工作状态,这意味着它正在从集群接收写集并将它们复制到本地数据库中的表中。
(3)检查复制运行状况
群集完整性和节点状态相关变量可以反映阻止复制的问题。而以下状态变量将有助于识别性能问题。这些变量是变化的,每次执行FLUSH STATUS后都会重置。
- wsrep_local_recv_queue_avg:自上次FLUSH STATUS以来本地接收队列的平均事务数。当节点返回一个大于0的值时,说明应用写集慢于接收写集,一个较大值可能触发流控。除此状态变量外,还可以使用wsrep_local_recv_queue_max和wsrep_local_recv_queue_min查看节点本地接收队列的最大、最小值。
- wsrep_flow_control_paused:自上次FLUSH STATUS以来节点因流控而暂停的时长。如果flush status和show status之间的时间为1分钟,并且节点返回0.25,则表示该节点在该时间段内总共暂停了15秒。返回0时,表示该节点在此期间没有由于流控而暂停。返回1时,表示该节点在整个时段都处于暂停复制状态。理想情况下,返回值应尽可能接近0,如果发现节点经常暂停,可以调整wsrep_slave_threads参数增加应用写集的线程数,也可以从集群中移除该节点。
- wsrep_cert_deps_distance:节点可能并行应用的事务序号之差,表示节点的并行化程度。可与wsrep_slave_threads参数配合使用,wsrep_slave_threads的值不应该大于此状态变量的值。
(4)检测网络
- wsrep_local_send_queue_avg:自上次FLUSH STATUS以来发送队列中的平均事务数。如果该值远大于0,表示网络吞吐量可能有问题。从服务器的物理组件到操作系统配置,任何层级都可能导致出现此问题。除此状态变量外,还可以使用wsrep_local_send_queue_max和wsrep_local_send_queue_min查看节点本地发送队列的最大、最小值。
2. 使用通知脚本
固然可以通过查询状态变量获得集群状态、节点状态和复制的运行状况,但登录每个节点执行此类查询是何等繁琐。作为更好的替代方法,Galera集群提供了一种叫做通知脚本(notification script)的方法,可以通过定制脚本来自动化集群的监控过程。我们先来看一下Galera自带的示例脚本。
[root@hdp2~]#more /usr/share/mysql/wsrep_notify
#!/bin/sh -eu
# This is a simple example of wsrep notification script (wsrep_notify_cmd).
# It will create 'wsrep' schema and two tables in it: 'membeship' and 'status'
# and fill them on every membership or node status change.
#
# Edit parameters below to specify the address and login to server.
USER=root
PSWD=rootpass
HOST=127.0.0.1
PORT=3306
SCHEMA="wsrep"
MEMB_TABLE="$SCHEMA.membership"
STATUS_TABLE="$SCHEMA.status"
BEGIN="
SET wsrep_on=0;
DROP SCHEMA IF EXISTS $SCHEMA; CREATE SCHEMA $SCHEMA;
CREATE TABLE $MEMB_TABLE (
idx INT UNIQUE PRIMARY KEY,
uuid CHAR(40) UNIQUE, /* node UUID */
name VARCHAR(32), /* node name */
addr VARCHAR(256) /* node address */
) ENGINE=MEMORY;
CREATE TABLE $STATUS_TABLE (
size INT, /* component size */
idx INT, /* this node index */
status CHAR(16), /* this node status */
uuid CHAR(40), /* cluster UUID */
prim BOOLEAN /* if component is primary */
) ENGINE=MEMORY;
BEGIN;
DELETE FROM $MEMB_TABLE;
DELETE FROM $STATUS_TABLE;
"
END="COMMIT;"
configuration_change()
{
echo "$BEGIN;"
local idx=0
for NODE in $(echo $MEMBERS | sed s/,/\ /g)
do
echo "INSERT INTO $MEMB_TABLE VALUES ( $idx, "
# Don't forget to properly quote string values
echo "'$NODE'" | sed s/\\//\',\'/g
echo ");"
idx=$(( $idx + 1 ))
done
echo "INSERT INTO $STATUS_TABLE VALUES($idx, $INDEX, '$STATUS', '$CLUSTER_UUID', $PRIMARY);"
echo "$END"
}
status_update()
{
echo "SET wsrep_on=0; BEGIN; UPDATE $STATUS_TABLE SET status='$STATUS'; COMMIT;"
}
COM=status_update # not a configuration change by default
while [ $# -gt 0 ]
do
case $1 in
--status)
STATUS=$2
shift
;;
--uuid)
CLUSTER_UUID=$2
shift
;;
--primary)
[ "$2" = "yes" ] && PRIMARY="1" || PRIMARY="0"
COM=configuration_change
shift
;;
--index)
INDEX=$2
shift
;;
--members)
MEMBERS=$2
shift
;;
esac
shift
done
# Undefined means node is shutting down
if [ "$STATUS" != "Undefined" ]
then
$COM | mysql -B -u$USER -p$PSWD -h$HOST -P$PORT
fi
exit 0
#
[root@hdp2~]#该脚本先定义了一个创建数据库表语句的字符串,然后定义了两个函数维护表数据,最后给出如何处理通知参数。
(1)通知参数
当节点在自身或集群中注册更改时,它将触发通知脚本执行,并把一些参数传递给通知脚本。下面是参数列表及其基本含义:
--status:节点传递一个指示其当前状态的字符串,值是以下六个值之一。
- Undefined:表示不属于主组件的节点。
- Joiner:表示作为主组件一部分并正在接收状态快照传输(SST)的节点。
- Donor:表示作为主组件一部分并正在发送状态快照传输(SST)的节点。
- Joined:表示作为主组件一部分的节点,该节点处于完成加入集群的状态并正在追赶群集。
- Synced:表示与群集同步的节点。
- Error:表示发生了错误。此状态字符串可能会提供一个错误代码,其中包含有关发生情况的详细信息。
通知脚本必须捕获--status参数的值并执行相应的操作。
--uuid:传一个表示节点UUID的字符串。
--primary:传一个yes或no的字符串,标识它是否认为自己是主组件的一部分。
--members:传当前群集成员列表,格式为
--index:传一个字符串,该字符串指示其在成员资格列表中的索引值。
(2)启用通知脚本
可以通过配置文件中的wsrep_notify_cmd参数启用通知脚本。在每个节点上创建可执行的shell文件/home/mysql/wsrep_notify.sh,然后设置wsrep_notify_cmd参数值为/home/mysql/wsrep_notify.sh。
cp /usr/share/mysql/wsrep_notify /home/mysql/wsrep_notify.sh
chown mysql:mysql /home/mysql/wsrep_notify.sh
chmod 755 /home/mysql/wsrep_notify.sh
sed -i 's/rootpass/P@sswo2d/' /home/mysql/wsrep_notify.sh
mysql -uroot -pP@sswo2d -e "set global wsrep_notify_cmd='/home/mysql/wsrep_notify.sh';"节点将为集群成员资格和节点状态的每次更改调用脚本。下面测试脚本执行情况:
1. 在节点2 drop掉去往第一、三个节点的数据包。
iptables -A OUTPUT -d 172.16.1.125 -j DROP
iptables -A OUTPUT -d 172.16.1.127 -j DROP2. 去掉数据包过滤
iptables -F3. 在节点2上查询wsrep库表
[root@hdp3/var/lib/mysql]#mysql -uroot -pP@sswo2d -e "select * from wsrep.membership;select * from wsrep.status;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+-----+--------------------------------------+-------+-------------------+
| idx | uuid | name | addr |
+-----+--------------------------------------+-------+-------------------+
| 0 | 605dc61c-fa2e-11e9-8b01-9f8f00127724 | node3 | 172.16.1.127:3306 |
| 1 | 6c468740-fa1a-11e9-8214-62a1abb74da6 | node2 | 172.16.1.126:3306 |
| 2 | ac8e4a3f-fadb-11e9-ad70-0a894466f015 | node1 | 172.16.1.125:3306 |
+-----+--------------------------------------+-------+-------------------+
+------+------+--------+--------------------------------------+------+
| size | idx | status | uuid | prim |
+------+------+--------+--------------------------------------+------+
| 3 | 1 | Synced | 4a6db23a-f9de-11e9-ba76-93e71f7c9a45 | 1 |
+------+------+--------+--------------------------------------+------+
[root@hdp3/var/lib/mysql]#利用iptables数据包过滤,使节点2的状态发生变化,此时触发执行了通知脚本。这里只使用了Galera自带的示例脚本,可以将它作为编写自定义通知脚本的起点,如加入响应群集更改的警报等。
3. 使用数据库服务器日志
log_error系统变量指定MySQL服务器错误日志文件名,缺省将写入错误日志数据目录中的
- wsrep_log_conflicts: 此参数启用错误日志的冲突日志记录,例如两个节点试图同时写入同一表的同一行,缺省为OFF。
- cert.log_conflicts: 此wsrep_provider_options选项允许在复制期间记录有关验证失败的信息,缺省为no。
- wsrep_debug: 此参数启用数据库服务器日志的调试信息,缺省为OFF。
可以通过my.cnf配置文件启用这些功能:
wsrep_log_conflicts=ON
wsrep_provider_options="cert.log_conflicts=ON"
wsrep_debug=ON注意,wsrep_debug参数会将数据库服务器的连接密码记录到错误日志中。这是一个安全漏洞,因此不要在生产环境中启用它。
除MySQL服务器日志外,如果wsrep_sst_method指定为xtrabackup,Galera还会将SST信息记录到数据目录下的innobackup.backup.log文件中。当一个节点无法应用事务时,MySQL服务器就在数据目录中创建该事件的特殊二进制日志文件,文件命名为GRA_*.log。该文件的读取参见https://community.pivotal.io/s/article/How-to-decode-Galera-GRA-logs-for-MySQL-for-PCF-v1-10
参考:
- MariaDB Galera Cluster部署实战