RocketMQ 源码分析 08 根据commitLog转发consumequeue和indexFile
RocketMQ 存储机制回顾
本文主要从源码的角度分析 Rocketmq 消费队列 ConsumeQueue 物理文件的构建与存储结构,同时分析 RocketMQ 索引文件IndexFile 文件的存储原理、存储格式以及检索方式。RocketMQ 的存储机制是所有的主题消息都存储在 CommitLog 文件中,也就是消息发送是完全的顺序 IO 操作,加上利用内存文件映射机制,极大的提供的 IO 性能。消息的全量信息存放在 commitlog 文件中,并且每条消息的长度是不一样的,消息的具体存储格式如下: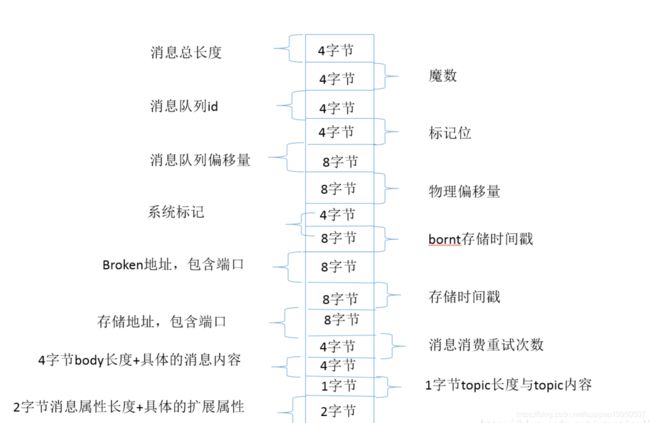
首先我们知道,一个主题,在 broker 上可以分成多个消费队列,默认为4个,也就是消费队列是基于主题+broker。那 ConsumeQueue 中当然不会再存储全量消息了,而是存储为定长(20字节,8字节commitlog 偏移量+4字节消息长度+8字节tag hashcode),消息消费时,首先根据 commitlog offset 去 commitlog 文件组(commitlog每个文件1G,填满了,另外创建一个文件),找到消息的起始位置,然后根据消息长度,读取整条消息。但问题又来了,如果我们需要根据消息ID,来查找消息,consumequeue 中没有存储消息ID,如果不采取其他措施,又得遍历 commitlog文件了,为了解决这个问题,rocketmq 的 index 文件又派上了用场。
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
根据 commitlog 文件生成 consumequeue、index 文件,主要同运作于两种情况:
1、运行中,发送端发送消息到 commitlog文件,此时如何及时传达到 consume文件、Index文件呢?
2、broker 启动时,检测 commitlog 文件与 consumequeue、index 文件中信息是否一致,如果不一致,需要根据 commitlog 文件重新恢复 consumequeue 文件和 index 文件。
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
RocketMQ 采用专门的线程来根据 comitlog offset 来将 commitlog 转发给ConsumeQueue、Index。其线程为DefaultMessageStore$ReputMessageService
每处理一次 doReput 方法,休眠1毫秒,基本上是马不停蹄的在转发 commitlog 中的内容到 consumequeue、index
1. 根据 offset 从 commitlog 找到一条消息,如果找不到,退出此次循环,doReput方法跳出,此处从 commitlog 文件中取出消息的逻辑
2 .如果能根据offset找到消息, 尝试构建转发请求对象 DispatchRequest ,我大概浏览了一下 commitLog.checkMessageAndReturnSize,主要是从Nio ByteBuffer中,根据 commitlog 消息存储格式,解析出消息的核心属性
3.转发DistpachRequest
4.开始根据commitLog获取的消息,重新发到consumeQueue中
4.1 判断 ConsumeQueue 是否可写
4.2 写入 consumequeue文件
5.调用Consumequeue#putMessagePositionInfoWrapper,开始写consumeQueue
5.1 首先将一条 ConsueQueue 条目总共20个字节,写入到 ByteBuffer 中
5.2 计算期望插入 ConsumeQueue 的 consumequeue 文件位置
5.3 如果文件是新建的,需要先填充空格
5.4 写入到 ConsumeQueue 文件中,整个过程都是基于 MappedFile 来操作的
6.调用构建indexFile,调用buildIndex
6.1 创建或获取当前写入的IndexFile.
6.2 如果 indexfile 中的最大偏移量大于该消息的 commitlog offset,忽略本次构建
6.3 将消息中的 keys,uniq_keys 写入 index 文件中。重点看一下putKey方法
7.继续深入构建indexFile
7.1 如果目前 index file 存储的条目数小于允许的条目数,则存入当前文件中,如果超出,则返回 false, 表示存入失败,IndexService 中有重试机制,默认重试3次。
7.2 先获取 key 的 hashcode,然后用 hashcode 和 hashSlotNum 取模,得到该 key 所在的 hashslot 下标,hashSlotNum默认500万个。
7.3 根据 key 所算出来的 hashslot 的下标计算出绝对位置
7.4 读取 key 所在 hashslot 下标处的值(4个字节),如果小于0或超过当前包含的 indexCount
7.5 计算消息的存储时间与当前 IndexFile 存放的最小时间差额
7.6 计算该 key 存放的条目的起始位置
7.7 填充 IndexFile 条目,4字节(hashcode) + 8字节(commitlog offset) + 4字节(commitlog存储时间与indexfile第一个条目的时间差,单位秒) + 4字节(同hashcode的上一个的位置,0表示没有上一个)
7.8 将当前先添加的条目的位置,存入到 key hashcode 对应的 hash槽,也就是该字段里面存放的是该 hashcode 最新的条目
7.9 更新IndexFile头部相关字段,比如最小时间,当前最大时间等

+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
RocketMQ 运行过程中消息发送者发送一条消息,进入到 commitlog 文件,然后是如何被转发到consumequeue、index索引文件中的,本节主要剖析一下,在 RocketMQ 启动过程中,是如何根据 commitlog 重构consumeque,index的,因为毕竟 commitlog 文件中的消息与 consumequeue 中的文件内容并不能确保是一致的
入口:DefaultMessageStore#load
1、首先先加载相关文件到内存(内存映射文件) mappedFile
包含Commitlog文件、ConsumeQueue文件、存储检测点(CheckPoint)文件、索引文件。
2、执行文件恢复
引入临时文件 abort 来区分是否是异常启动。在存储管理启动时(DefaultMessageStore)创建 abort 文件,结束时(shutdown)会删除 abort 文件,也就是如果在启动的时候,如果发现存储在该临时文件,则认为是异常。
恢复顺序:
1、先恢复 consumeque 文件,把不符合的 consueme 文件删除,一个 consume 条目正确的标准(commitlog偏移量 >0 size > 0)[从倒数第三个文件开始恢复]。
2、如果 abort文件存在,此时找到第一个正常的 commitlog 文件,然后对该文件重新进行转发,依次更新 consumeque,index文件。