总结4月13日密室逃脱后至今复习的内容(夯实基础,构建知识脉络)
- 脏读,不可重复读,幻读 :
https://blog.csdn.net/yuxin6866/article/details/52649048
一定要举例,脏读就是事务1未提交的内容事务2能看到,不可重复读是事务1的更新,事务2查第一次看不到,查第二次能看到。幻读是事务1的增删,事务2第一次看不到,第二次能看到。
事务ACID特性:原子性,一致性,独立性,持久性
事务4级别:Read Uncommitted, Read commited, Repeatable read, Serializable
Mysql默认隔离级别:可重复读(RR)
原因是RC不支持语句级 Binlog &
RC隔离级别下,会话2执行时序在会话1事务的语句之间,并且会话2的操作影响了会话1的结果,这会对Binlog结果造成影响。
在RR中,由于保证可重复读,会话2的delete语句会被会话1阻塞,直到会话1提交
http://www.cnblogs.com/vinchen/archive/2012/11/19/2777919.html
其他数据库多默认级别:RC
2.IOC是个啥 https://blog.csdn.net/weixin_40423553/article/details/80061881
https://blog.csdn.net/y1962475006/article/details/81290499
https://blog.csdn.net/sinat_21843047/article/details/80297951
传统应用程序都是由我们在类内部主动创建依赖对象,从而导致类与类之间高耦合,难于测试;有了IoC容器后,把创建和查找依赖对象的控制权交给了容器,由容器进行注入组合对象,所以对象与对象之间是 松散耦合,这样也方便测试,利于功能复用,
IoC对编程带来的最大改变不是从代码上,而是从思想上,发生了“主从换位”的变化。应用程序原本是老大,要获取什么资源都是主动出击,但是在IoC/DI思想中,应用程序就变成被动的了,被动的等待IoC容器来创建并注入它所需要的资源了。
控制反转(IoC),及上层控制下层,而不是下层控制着上层。我们用依赖注入(Dependency Injection)这种方式来实现控制反转。每次修改只改底层类就好了。
实现DI:构造器,setter注入,接口注入
控制反转容器:new car()的那段代码就是容器
最次的写法是比如造车,有个参数size,所有部件的类相互耦合于一个参数size,最后直接new car();再者同样是所有部件的类相互耦合,每new一个部件,将它作为参数传入上层实例中。这种不耦合于一个参数size上,但要写大量的new()
ioc的两种实现思路:反射(Spring的IOC方式)和new对象(Dagger的IOC方式)
反射需要类信息,用xml文件表示
3.Spring Boot的利弊:
项目依赖复杂的情况下,由于依赖方的依赖组织不够严格,可能引入了一些实际我们不需要的依赖,从而导致我们的项目满足一些特定的自动化配置。
传统Spring项目转换为Spring Boot项目的过程中,由于不同的组织方式问题,引发自动化配置加载的错误,比如:通过xml手工组织的多数据源配置等。
通过外部依赖的修改来解决:通过与依赖方沟通,在对方提供的API依赖中去掉不必要的依赖
通过禁用指定的自动化配置来避免加载不必要的自动化配置,下面列举了禁用的方法:@EnableAutoConfiguration(exculde={})
4.BeanFactory和FactoryBean:
BeanFactory是个Factory,也就是IOC容器或对象工厂,FactoryBean是个Bean。在Spring中,所有的Bean都是由BeanFactory(也就是IOC容器)来进行管理的。但对FactoryBean而言,这个Bean不是简单的Bean,而是一个能生产或者修饰对象生成的工厂Bean,它的实现与设计模式中的工厂模式和修饰器模式类似
BeanFactory定义了IOC容器的最基本形式,并提供了IOC容器应遵守的的最基本的接口,也就是Spring IOC所遵守的最底层和最基本的编程规范。在Spring代码中,BeanFactory只是个接口,并不是IOC容器的具体实现,但是Spring容器给出了很多种实现,如 DefaultListableBeanFactory、XmlBeanFactory、ApplicationContext等,都是附加了某种功能的实现。
由getObject类创建实例,然后XML文件(含Bean标签,Property标签)赋值
5.Spring全家桶
https://zhuanlan.zhihu.com/p/59327709?utm_source=wechat_timeline&utm_medium=social&utm_oi=629279107721072640&from=timeline
主要复习bean生命周期
创建bean setter接口注入 赋name,赋beanFactory,应用上下文,前置处理器,afterPropertySet init方法
6.start和run区别
start只是开辟新线程进等待队列,主线程的时间片用完才会用新线程跑。否则你run的还是主线程在执行
7.指定线程执行顺序,你真的懂notify,wait(Object类中)吗
以及signal和await(Condition接口中)
https://www.jianshu.com/p/b8073a6ce1c0
为啥写到同步块中
在API中,只有六种状态,new ,terminated,两种等待,runnable,blocked
https://zhuanlan.zhihu.com/p/59370428?utm_source=wechat_timeline&utm_medium=social&utm_oi=629279107721072640&from=timeline
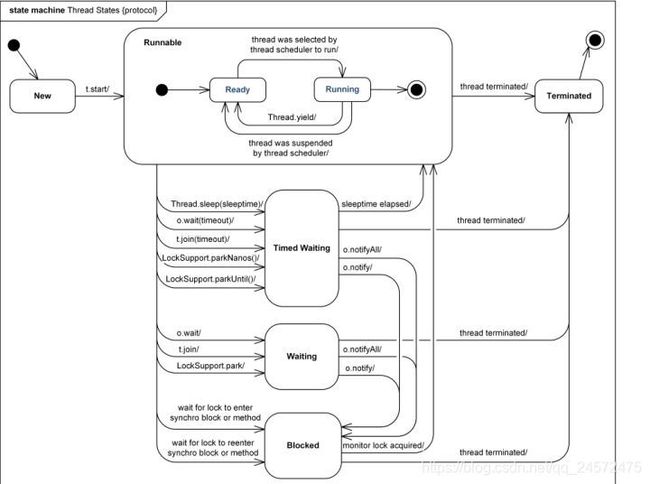
线程是啥:有自己的栈(Stack)、寄存器(Register)、本地存储(Thread
Local)等,但是会和进程内其他线程共享文件描述符、虚拟地址空间等
协程与线程:协程的切换只在用户态,线程切换需要在内核空间完成。协程切换只设计CPU上下文,线程还有他本身的栈等其他一些资源。每秒可被调度百万次,协程切换只要几十ns(纳秒)。
现在的模型是一对一映射到操作系统内核线程,Thread源码都是JNI方法
ThreadLocal给每个线程分配单独的变量副本,原理是ThreadLocalMap。不要与线程池共用,因为它废弃条目需要显示的触发,否则就要等线程结束,这是很多OOM的原因。
https://www.jianshu.com/p/25e243850bd2?appinstall=0
WAIT是当前线程进入wait set并且线程状态为waitting,且释放对象锁的过程
为啥wait要放到for而不能放到if里,如果是if,某线程第一次被wait后,被notify后就直接开始执行,不会再条件判断了。
为何不只notify一个:如果消费者和生产者都在等待队列,叫醒消费者,会wait,消费者和生产者互相等待。
public void produce() {
synchronized (this) {
while (mBuf.isFull()) {
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
mBuf.add();
notifyAll();
}
}
public void consume() {
synchronized (this) {
while (mBuf.isEmpty()) {
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
mBuf.remove();
notifyAll();
}
}
通过共享对象锁,通过Join()
8.String.valueOf()和toString()不同,自带判空
9.synchronized对象锁(方法锁)和类锁
synchronized 代码块是由一对儿
monitorenter/monitorexit 指令实现的
从用户态切换到内核态
代码量少,不需主动释放锁
reentrantLock 带超时的获取锁尝试,可响应中断请求
代码量稍多,主动释放锁
默认会使用偏斜锁。JVM 会利用 CAS 操作(compare and swap),在对
象头上的 Mark Word 部分设置线程 ID,以表示这个对象偏向于当前线程,所以并不涉及真正的互斥锁。
如果有另外的线程试图锁定某个已经被偏斜过的对象,JVM 就需要撤销(revoke)偏斜锁,并切换到轻量级锁实现
轻量级锁依赖 CAS 操作 Mark Word 来试图获取锁,如果重试成功,就
使用普通的轻量级锁;否则,进一步升级为重量级锁
自旋锁:竞争锁的失败的线程,并不会真实的在操作系统层面挂起等待,而是JVM会让线程做
几个空循环(基于预测在不久的将来就能获得),在经过若干次循环后,如果可以获得锁,那么进入临界区,如果还不能获得锁,才会真实的将线程在操作系统层面进行挂起。
适用场景:自旋锁可以减少线程的阻塞,这对于锁竞争不激烈,且占用锁时间非常短的代码块
来说,有较大的性能提升,因为自旋的消耗会小于线程阻塞挂起操作的消耗。
如果锁的竞争激烈,或者持有锁的线程需要长时间占用锁执行同步块,就不适合使用自旋锁
了,因为自旋锁在获取锁前一直都是占用cpu做无用功,线程自旋的消耗大于线程阻塞挂起操作的消耗,造成cpu的浪费
10.CountDownLatch、CyclicBarrier和 Semaphore
public void await() throws InterruptedException { }; //调用await()方法的线程会被挂起,它会等待直到count值为0才继续执行
public boolean await(long timeout, TimeUnit unit) throws InterruptedException { }; //和await()类似,只不过等待一定的时间后count值还没变为0的话就会继续执行
public void countDown() { }; //将count值减1
public int await() throws InterruptedException, BrokenBarrierException { };
public int await(long timeout, TimeUnit unit)throws InterruptedException,BrokenBarrierException,TimeoutException { };
第一个版本比较常用,用来挂起当前线程,直至所有线程都到达barrier状态再同时执行后续任务;
第二个版本是让这些线程等待至一定的时间,如果还有线程没有到达barrier状态就直接让到达barrier的线程执行后续任务。
如果说想在所有线程写入操作完之后,进行额外的其他操作可以为CyclicBarrier提供Runnable参数,再重写run方法就好了
两者区别主要在可重用
public Semaphore(int permits) { //参数permits表示许可数目,即同时可以允许多少线程进行访问
sync = new NonfairSync(permits);
}
public Semaphore(int permits, boolean fair) { //这个多了一个参数fair表示是否是公平的,即等待时间越久的越先获取许可
sync = (fair)? new FairSync(permits) : new NonfairSync(permits);
信号量控制同时访问的线程个数。acquire获得许可,release释放许可。
1)CountDownLatch和CyclicBarrier都能够实现线程之间的等待,只不过它们侧重点不同:
CountDownLatch一般用于某个线程A等待若干个其他线程执行完任务之后,它才执行;
而CyclicBarrier一般用于一组线程互相等待至某个状态,然后这一组线程再同时执行;
另外,CountDownLatch是不能够重用的,而CyclicBarrier是可以重用的。
2)Semaphore其实和锁有点类似,它一般用于控制对某组资源的访问权限。
11.CAS 无锁
应用 原子操作类atomic
CAS产生ABA问题
AtomicStampedReference和 AtomicMarkableReference来解决
volatile保证可见性:读时从主内存获取到工作内存,写时从工作内存刷到主内存
为什么不保证原子性:
Java中只有对基本类型变量的赋值和读取是原子操作,两个线程都实现+1,第一个线程读到了10,被阻塞,后来变成11.第二个正常工作得到11。最后没有变成12
12.ThreadLocal
ThreadLocal为每个使用该变量的线程提供独立的变量副本,所以每一个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本
在ThreadLocal类中有一个static声明的Map,用于存储每一个线程的变量副本,Map中元素的键为线程对象,而值对应线程的变量副本
场景:数据库链接,session管理
13.LocakSupport
1.wait和notify都是Object中的方法,在调用这两个方法前必须先获得锁对象,这限制了其使用场合:只能在同步代码块中。
2.当对象的等待队列中有多个线程时,notify只能随机选择一个线程唤醒,无法唤醒指定的线程。
而使用LockSupport的话,我们可以在任何场合使线程阻塞,同时也可以指定要唤醒的线程,相当的方便
当调用park()方法时,会将_counter置为0,同时判断前值,小于1说明前面被unpark过,则直接退出,否则将使该线程阻塞。
当调用unpark()方法时,会将_counter置为1,同时判断前值,小于1会进行线程唤醒,否则直接退出。
形象的理解,线程阻塞需要消耗凭证(permit),这个凭证最多只有1个。当调用park方法时,如果有凭证,则会直接消耗掉这个凭证然后正常退出;但是如果没有凭证,就必须阻塞等待凭证可用;而unpark则相反,它会增加一个凭证,但凭证最多只能有1个。
14 BlockQueue由ReetrantLock实现,主要用于实现生产者-消费者模型。
15.关于锁:https://juejin.im/post/5bee576fe51d45710c6a51e0
美团技术团队讲得太好了吧
16.POJO和JavaBean:前者是非常纯净的类或接口,只有属性和GETTER,SETTER。后者在此基础上继承了Serializable接口,有无参构造器,也可以有简单逻辑方法。
17.关于索引
https://www.cnblogs.com/zyy1688/p/9983122.html
索引分为 主键 唯一索引 普通索引 聚簇索引 非聚簇索引
设计模式