pytorch —— nn网络层 - 卷积层
目录
- 1、1d/2d/3d卷积
- 2、卷积-nn.Conv1d()
- 2.1 Conv1d的参数说明
- 2.2 例子说明
- 3、卷积-nn.Conv2d()
- 3.1 深入了解卷积层的参数
- 4、转置卷积-nn.ConvTranspose
- 4.1 nn.ConvTranspose2d
1、1d/2d/3d卷积
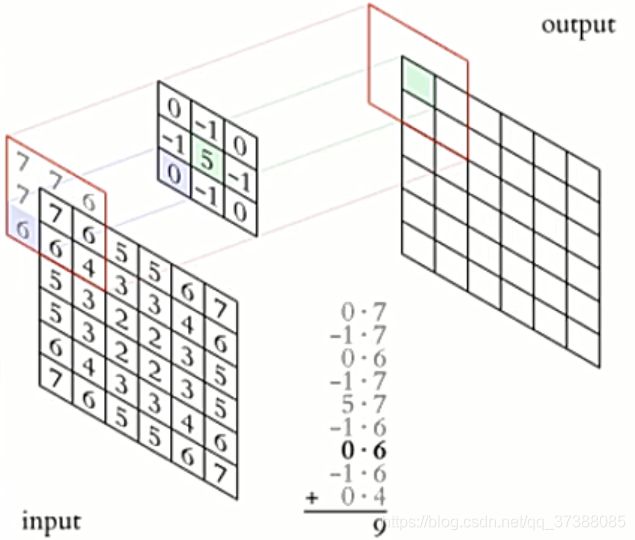
卷积运算: 卷积核在输入信号(图像)上滑动,相应位置上进行乘加;
卷积核: 又称为滤波器,过滤器,可认为是某种模式,某种特征;
卷积过程类似于用一个模板去图像上寻找与它相似的区域,与卷积核模式越相似,激活值越高,从而实现特征提取;
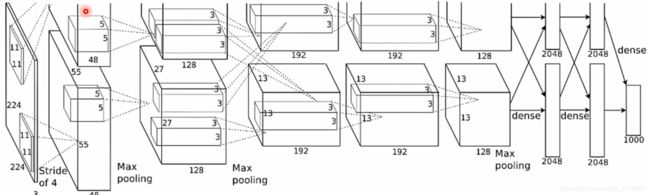
AlexNet卷积核可视化,发现卷积核学习到的是边缘,条纹,色彩这一些细节模式;

卷积维度: 一般情况下,卷积核在几个维度上滑动就是几维卷积。
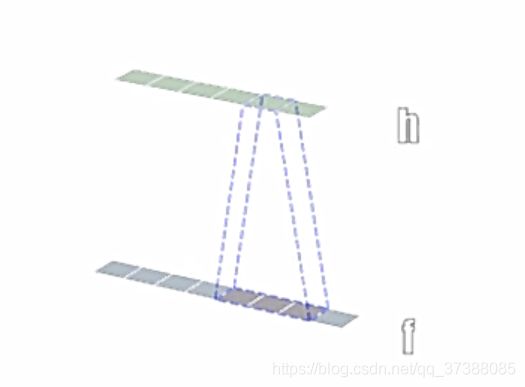
一 维 卷 积 一维卷积 一维卷积
二 维 卷 积 二维卷积 二维卷积
三 维 卷 积 三维卷积 三维卷积
2、卷积-nn.Conv1d()
一维卷积可以应用在对文本中,将一段文字通过word_embedding之后连接成一段一维长向量,然后以一个字或者几个字的词嵌入长度为卷积核进行卷积。
torch.nn.Conv1d(in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True)
一维卷积层,输入的尺度为 ( N , C i n , L ) (N,C_{in},L) (N,Cin,L),输出尺度为 ( N , C o u t , L o u t ) (N,C_{out},L_{out}) (N,Cout,Lout)。N代表批数量大小, C i n C_{in} Cin代表输入数据的通道数,L代表输入数据的长度。 C o u t C_{out} Cout代表输出数据的通道数, L o u t L_{out} Lout表示输入数据长度经过卷积后的长度。
2.1 Conv1d的参数说明
- in_channels(int):输入信号通道;
- out_channels(int):卷积产生的通道;
- kerner_size(int or tuple):卷积核的尺寸;
- stride(int or tuple,optional):卷积步长;
- padding(int or tuple,optional):是否对输入数据填充0。Padding可以将输入数据的区域改造成是卷积大小的整数倍,这样对不满足卷积核大小的部分数据就不会忽略了。通过Padding参数指定填充区域的高度何宽度;
- dilation(int or tuple,‘optional’):卷积核之间的空格;
- groups(int,optional):将输入数据分成组,in_channels应该被组数整除;
- bias(bool,optional):如果bias=True,添加偏置。
2.2 例子说明
m = nn.Conv1d(16, 33, 3, stride=2)
inputs = autograd.Variable(torch.randn(20, 16, 50))
output = m(inputs)
- 上述例子中的一维卷积核的输入通道设置为16,输出通道设置为33,卷积核大小为3,步进为2;
- 输入数据的批大小为20,通道数为16,每个通道的长度为50;
- 通过卷积,16通道对应的卷积核运算后进行累加得到输出的一个通道,重复这个步骤得到33个输出通道。
- 每个通道的长度为50,卷积核大小为3,步进为2,得到的输出通道数据的长度为24。
3、卷积-nn.Conv2d()
功能:对多个二维信号进行二维卷积;
nn.Conv2d(in_channels,
out_channels,
kernel_size,
stride=1.
padding=0,
dilation=1,
groups=1,
bias=True,
padding_mode='zeros')
主要参数:
- in_channels:输入通道数
- out_channels:输出通道数,等价于卷积核个数
- kernel_size:卷积核尺寸
- stride:步长
- padding:填充个数
- dilation:空洞卷积大小
- groups:分组卷积设置
- bias:偏置,在卷积求和之后加上偏置的值
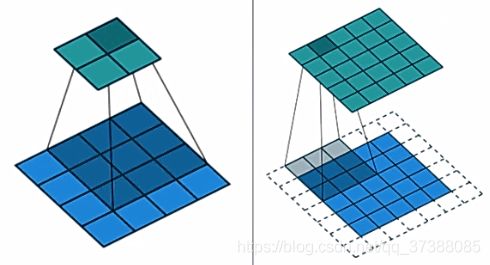
p a d d i n g 的 作 用 padding的作用 padding的作用
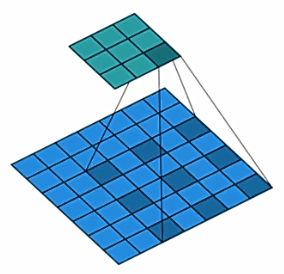
空 洞 卷 积 的 作 用 空洞卷积的作用 空洞卷积的作用
分 层 卷 积 的 描 述 分层卷积的描述 分层卷积的描述
尺寸计算:
简化版: o u t s i z e = I N s i z e − k e r n e l s i z e s t r i d e + 1 out_{size}=\frac{IN_{size}-kernel_{size}}{stride}+1 outsize=strideINsize−kernelsize+1
完整版: H o u t = ⌊ H i n + 2 ∗ p a d d i n g [ 0 ] − d i l a t i o n [ 0 ] ∗ ( k e r n e l [ 0 ] − 1 ) − 1 s t r i d e [ 0 ] + 1 ⌋ H_{out}=\left \lfloor \frac{H_{in}+2*padding[0]-dilation[0]*(kernel[0]-1)-1}{stride[0]}+1 \right \rfloor Hout=⌊stride[0]Hin+2∗padding[0]−dilation[0]∗(kernel[0]−1)−1+1⌋
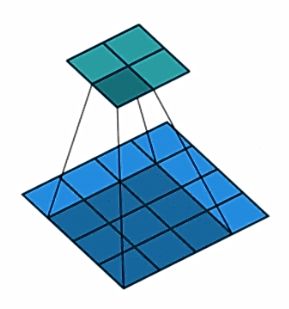
如上图中的卷积之后的尺寸为: 4 − 3 1 + 1 = 2 \frac{4-3}{1}+1=2 14−3+1=2
通过代码看一下卷积层的具体作用:
"""
代码来源于深度之眼pytorch课程-余老师
"""
import os
import torch.nn as nn
from PIL import Image
from torchvision import transforms
from matplotlib import pyplot as plt
from common_tools import transform_invert, set_seed
set_seed(1) # 设置随机种子,不同的随机种子会给卷积层权重不一样,这会导致提取到的特征不同
# ================================= load img ==================================
path_img = os.path.join(os.path.dirname(os.path.abspath(__file__)), "E:/pytorch深度学习/lenaa.png")
img = Image.open(path_img).convert('RGB') # 0~255
# convert to tensor
img_transform = transforms.Compose([transforms.ToTensor()]) # RGB图像转换成张量的形式
img_tensor = img_transform(img)
img_tensor.unsqueeze_(dim=0) # C*H*W to B*C*H*W,拓展到四维的张量,增加batch_size的维度
# ================================= create convolution layer ==================================
# ================ 2d
flag = 1
# flag = 0
if flag:
conv_layer = nn.Conv2d(3, 1, 3) # input:(i, o, size) weights:(o, i , h, w),输入为三个通道,卷积核个数1个,输出通道为1
nn.init.xavier_normal_(conv_layer.weight.data) # 卷积层初始化
# calculation
img_conv = conv_layer(img_tensor) # 图片进入卷积层
# ================ transposed
# flag = 1
flag = 0
if flag:
conv_layer = nn.ConvTranspose2d(3, 1, 3, stride=2) # input:(i, o, size)
nn.init.xavier_normal_(conv_layer.weight.data)
# calculation
img_conv = conv_layer(img_tensor)
# ================================= visualization ==================================
print("卷积前尺寸:{}\n卷积后尺寸:{}".format(img_tensor.shape, img_conv.shape))
img_conv = transform_invert(img_conv[0, 0:1, ...], img_transform) # 对transform进行逆操作,将张量转换成PIL的图像
img_raw = transform_invert(img_tensor.squeeze(), img_transform)
plt.subplot(122).imshow(img_conv, cmap='gray') # 图像可视化
plt.subplot(121).imshow(img_raw)
plt.show()
设置不同的随机种子,Xavier初始化权重不同,输出的结果不同:
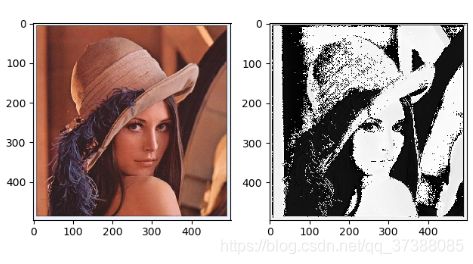
随 机 种 子 为 1 随机种子为1 随机种子为1
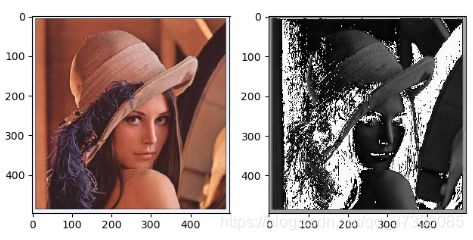
随 机 种 子 为 2 随机种子为2 随机种子为2
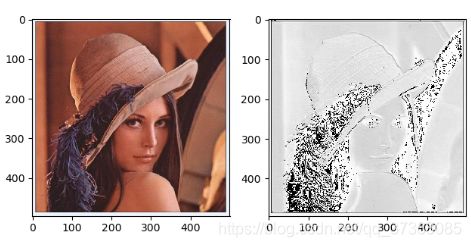
随 机 种 子 为 3 随机种子为3 随机种子为3
3.1 深入了解卷积层的参数
对代码设置断点,进行单步调试:
flag = 1
# flag = 0
if flag:
(设置断点)conv_layer = nn.Conv2d(3, 1, 3) # input:(i, o, size) weights:(o, i , h, w),输入为三个通道,卷积核个数1个,输出通道为1
nn.init.xavier_normal_(conv_layer.weight.data)
代码进入conv.py文件中的Conv2d()类,如下所示,Conv2d是继承于ConvNd类的,而ConvNd又继承于module基本类,所以Conv2d也是一个nn.module,这样就创建好了一个卷积层:
class Conv2d(_ConvNd):
def __init__(self, in_channels, out_channels, kernel_size, stride=1,
padding=0, dilation=1, groups=1,
bias=True, padding_mode='zeros'):
kernel_size = _pair(kernel_size)
stride = _pair(stride)
padding = _pair(padding)
dilation = _pair(dilation)
super(Conv2d, self).__init__(
in_channels, out_channels, kernel_size, stride, padding, dilation,
False, _pair(0), groups, bias, padding_mode)
创建好一个卷积层后,可以查看这个卷积层的8个字典参数,如下:

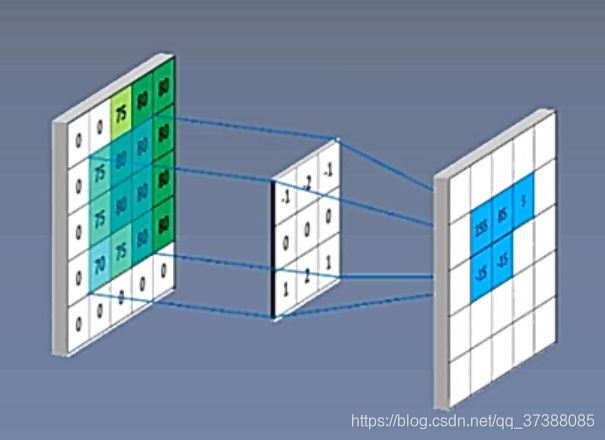
这些属性中,权值属性是最重要的属性,从下图中可以看到权值是一个4维的张量[1,3,3,3]。怎么理解四维的张量去进行二维的卷积呢?[1,3,3,3]中1表示输出通道数,也就是卷积核个数;第二个3表示输入的通道数;最后的两个3是二维的卷积核的尺寸。
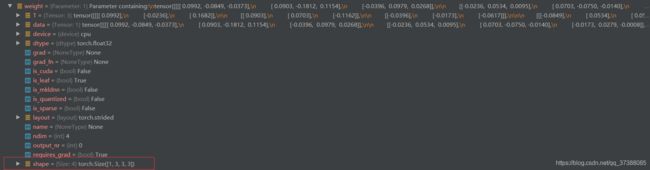
下面通过一个图看看上面提到的[1,3,3,3]是怎么工作的。
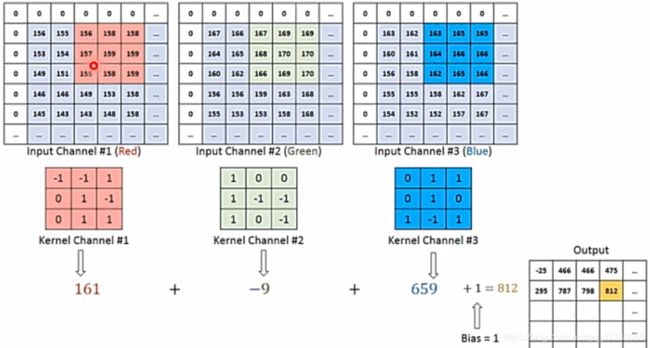
输入的图片是一个三维的RGB图像,创建三个二维的卷积核,三个二维的卷积核分别对应每个通道进行卷积,然后三个卷积核卷积得到的值进行相加。一个卷积核只在其中的一个二维图像上移动,所以这是二维的卷积。虽然卷积核是三维的卷积核,但是我们并不能认为这是一个三维卷积。
4、转置卷积-nn.ConvTranspose
转置卷积又称为反卷积(Deconvolution)和部分跨越卷积(Fractionally-strided Convolution),用于对图像上进行上采样(UpSample),在图像分割任务中经常使用。
为什么称为转置卷积?
假设图片尺寸为44,卷积核为33,padding=0,stride=1,如下所示。
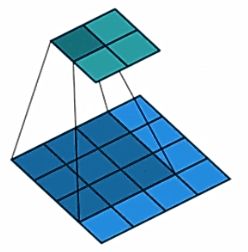
现在看看代码是怎么实现正常卷积操作的,首先将图像拉成一个向量的形式,4*4的图像会变成 I 16 ∗ 1 I_{16*1} I16∗1的二维矩阵,16是图像的所有像素,1是一张图片。
33的卷积核会变成 K 4 ∗ 16 K_{4*16} K4∗16的矩阵,16是通过9个卷积核权值进行补零得到的16个数,4是输出像素值的总的个数。得到这两个矩阵之后,通过矩阵运算得到输出的特征图。 O 4 ∗ 1 = K 4 ∗ 16 ∗ I 16 ∗ 1 O_{4*1}=K_{4*16}*{I_{16*1}} O4∗1=K4∗16∗I16∗1
得到的输出 O 4 ∗ 1 O_{4*1} O4∗1进行resize就可以得到2*2的输出。
下面看一下转置卷积的具体操作:
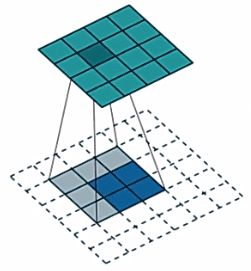
转置卷积实现的是上采样,就是输入的尺寸小于输出的尺寸,现在看看怎样通过矩阵乘法实现转置卷积。
假设图像尺寸为22,卷积核大小为 33,padding=0,stride=1。把输入的尺寸拉成一个矩阵 I 4 ∗ 1 I_{4*1} I4∗1,卷积核变成一个 K 16 ∗ 4 K_{16*4} K16∗4的矩阵,16是输出的像素个数,而4是卷积核中9个值的某些值,这里和正常卷积不同,正常卷积是补零,这里是剔除一些卷积核权值。可以看一下上面的示意图,卷积核有9个权值,但是能与图像相乘的最多只能有4个,所以会采取剔除的方法,从九个权值中挑选出来对应的四个权值与图像进行相乘。
得到两个矩阵后,通过矩阵相乘的方法就可以实现一个转置卷积,得到 O 16 ∗ 1 O_{16*1} O16∗1的数据: O 16 ∗ 1 = K 16 ∗ 4 ∗ I 4 ∗ 1 O_{16*1}=K_{16*4}*{I_{4*1}} O16∗1=K16∗4∗I4∗1然后进行resize就可以得到4*4的输出值。
我们现在看一下正常卷积和转置卷积的区别,如下图:
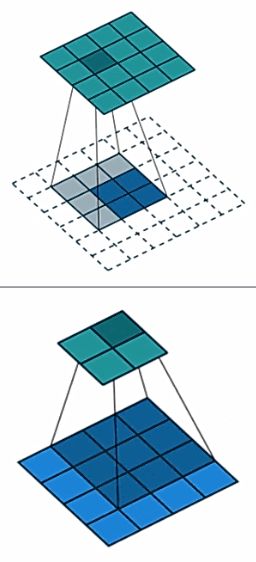
正常卷积的卷积矩阵是 K 4 ∗ 16 K_{4*16} K4∗16,而转置卷积是 K 16 ∗ 4 K_{16*4} K16∗4,这两个卷积核矩阵是转置的关系,这就是转置卷积名字的由来。但是需要注意,这两个矩阵只是形状上的转置,这两者的权值是完全不相同的。由于权值完全不同,所以正常卷积和转置卷积是不可逆的。也就是16个像素经过正常卷积,然后反卷积得到的16个像素是完全不相等的,这也是不建议称为逆卷积或者反卷积的原因,因为这两个是不可逆的。
4.1 nn.ConvTranspose2d
功能:转置卷积实现上采样
nn.ConvTranspose2d(in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
output_padding=0,
groups=1,
bias=True,
dilation=1,
padding_mode='zores')
主要参数:
- in_channels:输入通道数
- out_channels:输出通道数
- kernel_size:卷积核尺寸
- stride:步长
- padding:填充个数
- dilation:空洞卷积大小
- groups:分组卷积设置
- bias:偏置
尺寸计算:
简化版: o u t s i z e = ( i n s i z e − 1 ) ∗ s t r i d e + k e r n e l s i z e out_{size}=(in_{size}-1)*stride+kernel_{size} outsize=(insize−1)∗stride+kernelsize
完整版: H o u t = ( H i n − 1 ) ∗ s t r i d e [ 0 ] − 2 ∗ p a d d i n g [ 0 ] + d i l a t i o n [ 0 ] ∗ ( k e r n e l _ s i z e [ 0 ] − 1 ) + o u t p u t _ p a d d i n g [ 0 ] + 1 H_{out}=(H_{in}-1)*stride[0]-2*padding[0]+dilation[0]*(kernel\_size[0]-1)+output\_padding[0]+1 Hout=(Hin−1)∗stride[0]−2∗padding[0]+dilation[0]∗(kernel_size[0]−1)+output_padding[0]+1
下面看一下代码中ConvTranspose2d的具体使用过程:
conv_layer = nn.ConvTranspose2d(3, 1, 3, stride=2) # input:(i, o, size)
nn.init.xavier_normal_(conv_layer.weight.data)
# calculation
img_conv = conv_layer(img_tensor)
运算之后得到的图片结果如下所示:
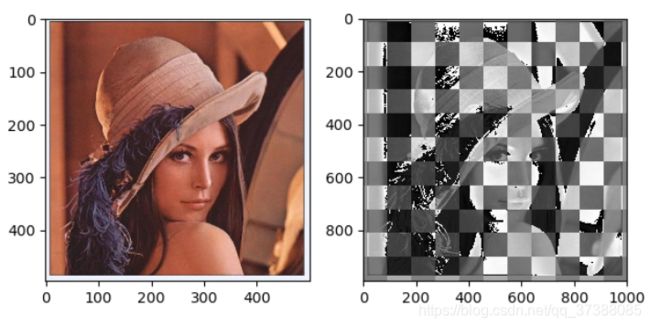
通过图片可以发现,经过转置卷积上采样之后,图像有一个奇怪的现象,有一格一格的方块,像一个棋盘,这是转置卷积的通病,称为棋盘效应,它是由于不均匀重叠导致的,关于棋盘效应的解释以及解决方法可以看《Deconvolution and Checkerboard Artifacts》