强化学习笔记(一)基于openAI gym CartPole-V0实现
强化学习笔记(一)基于openAI gym CartPole-V0实现
- 一、基础定义
- 一、基于openAI gym CartPole-V0实例学习
- 1、游戏背景
- 2、代码实现
- 2.1 测试CartPole环境中随机action的表现,作为baseline
- 2.2 构建策略网络
- 2.3 运行结果
- 2.4 总结
一、基础定义
强化学习是机器学习的一个分支,主要用来解决时序决策问题。他可以在复杂的、不确定的环境中学习如何实现我们设定的目标。一个强化学习模型主要包括四个部分, 环境状态(environment state), 智能体(agent),行动(action),奖励函数(reward)。
环境状态(environment state)集合可以是一个有限集合,状态是其中的特征,环境中除了包含状态信息,还需要定义智能体和环境交互所带来的环境的改变。
智能体(agent)是强化学习的载体,它负责执行模型给出的行动(action)。环境是agent无法控制的,但是环境可以被观察,然后根据观察的结果,给出进一步的行动。
行动(action)是agent的可行域,通常为连续或离散的有限集合(不知道这一理解对不对),行动由agent根据目标函数的优化给出,当行动给出后,一方面环境状态会发生改变,另一方面agent会得到由奖励函数给出的奖励。
奖励函数(reward):对应于一个特定的环境状态,我们并不知道最好的行动是什么,我们只知道当前行动的奖励,以及行动后获得的未来的奖励。(agent在执行行动时不仅要考虑当前奖励,还会考虑到该行动对未来的影响,所以会得到未来奖励的一个折现。)强化学习模型的目标是让模型通过实验样本自己学习到什么才是某个环境下比较好的行动,而不是预先告诉模型什么是最好的行动,因为我们也不知道什么是最好的策略。
一、基于openAI gym CartPole-V0实例学习
1、游戏背景
游戏背景:环境中有一辆小车,在一维无阻力的轨道上运动,车上连接一根活动杆,杆会左右摇摆。

游戏规则很简单,我们要操纵我们的小车左右移动,使它上面的木棒能够保持平衡。当小车偏离中心4.8个单位,或杆的倾斜超过24度,任务失败。
智能体的目标是坚持尽量长的时间,对于任意一个action,只要不导致任务失败,reward +1。要求智能体必须有远见,对于每一个action除了考虑当前reward,还要考虑未来利益。
游戏的全过程可以理解为AI智能体和环境之间的互动,我们把其中复杂的因素抽象为三个变量——报酬、行动、状态。
以下是openAI gym 中关于CartPole-V0游戏的描述
"""
Description:
A pole is attached by an un-actuated joint to a cart, which moves along a frictionless track. The pendulum starts upright, and the goal is to prevent it from falling over by increasing and reducing the cart's velocity.
Source:
This environment corresponds to the version of the cart-pole problem described by Barto, Sutton, and Anderson
Observation:
Type: Box(4)
Num Observation Min Max
0 Cart Position -4.8 4.8
1 Cart Velocity -Inf Inf
2 Pole Angle -24 deg 24 deg
3 Pole Velocity At Tip -Inf Inf
Actions:
Type: Discrete(2)
Num Action
0 Push cart to the left
1 Push cart to the right
Note: The amount the velocity that is reduced or increased is not fixed; it depends on the angle the pole is pointing. This is because the center of gravity of the pole increases the amount of energy needed to move the cart underneath it
Reward:
Reward is 1 for every step taken, including the termination step
Starting State:
All observations are assigned a uniform random value in [-0.05..0.05]
Episode Termination:
Pole Angle is more than 12 degrees
Cart Position is more than 2.4 (center of the cart reaches the edge of the display)
Episode length is greater than 200
Solved Requirements
Considered solved when the average reward is greater than or equal to 195.0 over 100 consecutive trials.
"""
2、代码实现
2.1 测试CartPole环境中随机action的表现,作为baseline
# -*- coding: utf-8 -*-
"""
Created on Fri Apr 5 20:12:03 2019
@author: zhangfan
"""
#导入openAI gym 以及 TensorFlow
import gym
import numpy as np
import tensorflow as tf
#用gym.make('CartPole-v0')导入gym定义好的环境,对于更复杂的问题则需要自定义环境
env = gym.make('CartPole-v0')
#第一步不用agent,采用随机策略进行对比
env.reset() #初始化环境
random_episodes = 0
reward_sum = 0
while random_episodes < 10:
env.render()
obsevation, reward, done, _ = env.step(np.random.randint(0, 2))
#np.random.randint创建随机action,env.step执行action
reward_sum += reward
#最后一个action也获得奖励
if done:
random_episodes += 1
print("Reward for this episodes was:", reward_sum)
reward_sum = 0 #重置reward
env.reset()
2.2 构建策略网络
我们在策略网络使用一个带有一层隐藏层的ANN,各种超参数为:nodes = 50, batch_size = 25, learning_rate = 0.1, discout_rate = 0.99。定义策略网络将agent对环境的observation作为输入,最后输入概率值选择action。
#PART2:AGENT. Agent是一个简单的ANN with one hidden layer.
#可以使用更复杂的深度神经网络
H = 50 #50个neure
batch_size = 25
learning_rate = 0.1
D = 4 #observation维度为4
gamma = 0.99 #discount rate
#定义策略网络具体结构:输入observation,输出选择action的概率
observations = tf.placeholder(tf.float32, [None, D], name = "input_x")
W1 = tf.get_variable("W1", shape = [D, H], initializer=tf.contrib.layers.xavier_initializer())
layer1 = tf.nn.relu(tf.matmul(observations, W1))
#隐藏层使用ReLu激活
W2 = tf.get_variable("W2", shape = [H, 1], initializer=tf.contrib.layers.xavier_initializer())
score = tf.matmul(layer1, W2)
probability = tf.nn.sigmoid(score)
#输出层使用Sigmoid将输出转化为概率
#定义优化器,梯度占位符,采用batch training更新参数
adam = tf.train.AdamOptimizer(learning_rate = learning_rate)
W1_grad = tf.placeholder(tf.float32,name = "batch_grad1")
W2_grad = tf.placeholder(tf.float32,name = "batch_grad2")
batchGrad = [W1_grad, W2_grad]
tvars = tf.trainable_variables()
updateGrads = adam.apply_gradients(zip(batchGrad, tvars))
#计算每一个action的折现后的总价值
def discount_rewards(r):
discounted_r = np.zeros_like(r)
running_add = 0
for t in reversed(range(r.size)):
running_add = running_add * gamma + r[t]
discounted_r[t] = running_add
return discounted_r
#计算损失函数
input_y = tf.placeholder(tf.float32, [None, 1], name = "input_y")
advantages = tf.placeholder(tf.float32, name = "reward_signal")
#action的潜在价值
loglik = tf.log(input_y*(input_y - probability) + (1-input_y)*(input_y + probability))
#loglik为action的对数概率,P(act=1) = probablility,P(act=0) = 1-probablility
#action=1,loglik = tf.log(probability)
#action=0,loglik = tf.log(1-probability)
loss = -tf.reduce_mean(loglik * advantages)
newGrads = tf.gradients(loss, tvars)
#tvars用于获取全部可训练参数,tf.gradients求解参数关于loss的梯度
xs = [] #observation的列表
ys = [] #label的列表, label = 1 - action
drs = [] #每个action的reward
reward_sum = 0 #累计reward
episode_num = 1 #每次实验index
total_episodes = 10000 #总实验次数
#创建会话
with tf.Session() as sess:
rendering = False
init = tf.global_variables_initializer()
sess.run(init) #初始化状态
observation = env.reset() #重置环境
gradBuffer = sess.run(tvars)
#创建存储参数梯度的缓冲器,执行tvars获取所有参数
for ix,grad in enumerate(gradBuffer):
gradBuffer[ix] = grad * 0 #将所有参数全部初始化为零
#进入实验循环
while episode_num <= total_episodes:
#当某batch平均reward>100时,对环境进行展示
if reward_sum/batch_size > 100 or rendering == True:
env.render()
rendering = True
#将observation变形为网络输入格式
x = np.reshape(observation, [1, D])
#计算action=1的概率tfprob
tfprob = sess.run(probability, feed_dict={observations: x})
#(0,1)随机抽样,若随机值小于tfprob,action=1
action = 1 if np.random.uniform() < tfprob else 0
xs.append(x) #将observation加入列表xs
y = 1 - action
ys.append(y) #将label加入列表ys
observation, reward, done, info = env.step(action)
#env.step执行action,获取observation,reward,done,info
reward_sum += reward
drs.append(reward) #将reward加入列表drs
# done=True 即实验结束
if done:
episode_num += 1 #一次实验结束,index+1
epx = np.vstack(xs)
epy = np.vstack(ys)
epr = np.vstack(drs)
xs, ys, drs = [], [], []
#计算每一步的总价值,并标准化为均值为0标准差为1的分布
discounted_epr = discount_rewards(epr)
discounted_epr -= np.mean(discounted_epr)
discounted_epr /= np.std(discounted_epr)
#将epx epy epr 输入神经网络,newGrads求梯度
tGrad = sess.run(newGrads, feed_dict={observations: epx, input_y: epy, advantages: discounted_epr})
for ix,grad in enumerate(tGrad):
gradBuffer[ix] += grad
#将梯度叠加进gradBuffer
#当试验次数达到batch_size整数倍时
if episode_num % batch_size == 0:
sess.run(updateGrads, feed_dict={W1_grad: gradBuffer[0], W2_grad: gradBuffer[1]})
#updateGrads将gradBuffer梯度更新到模型参数中
for ix, grad in enumerate(gradBuffer):
gradBuffer[ix] = grad * 0
#清空gradBuffer,为下一个batch做准备
print('Average reward for episode %d : %f.' %(episode_num, reward_sum/batch_size))
if reward_sum/batch_size > 200:
print("Task solved in", episode_num, 'episodes!')
break
reward_sum = 0
observation = env.reset()
#每次实验结束,重置任务环境
2.3 运行结果
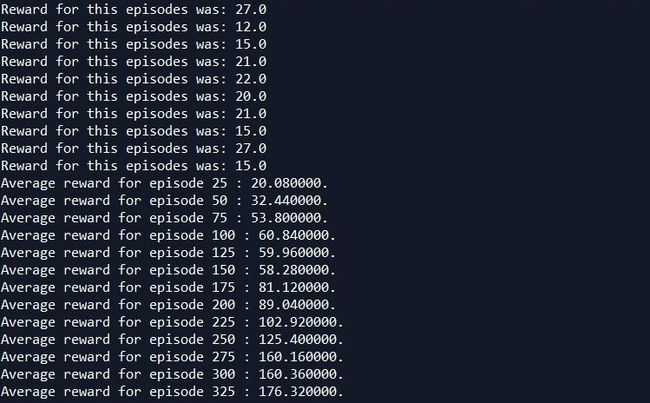
2.4 总结
结果看来ANN作agent效果不是很好,那也就是说增强学习模型的性能在很大程度上会依赖于agent的选择,而通常智能体会采用机器学习或深度学习的算法来做,也就是说增强学习是个框架,机器学习或深度学习会嵌入这个框架中,并且会在很大程度上影响其性能。
不知道这么理解对不对