必能读懂的 交叉熵详解,pytorch中交叉熵的使用
目录
1. 交叉熵详解
1.1 信息量
1.2 熵
1.3 相对熵(KL散度)
1.4 交叉熵
1.5 小结
2. 交叉熵的应用(pytorch中)
2.1 交叉熵在分类任务中的计算过程
2.2 log_softmax()函数
2.3 nll_loss()函数
2.4 cross_entropy()函数
2.5 函数的其他调用方式
1. 交叉熵详解
1.1 信息量
简答的举个例子,假设分别发生了以下事件
1. 摇骰子六次,出现了点数 6
2. 摇骰子六次,全都是点数6
显然事件2出现的概率就很小,所以我们就说,事件2的信息量更大,信息学中使用下面的公式表示信息量:
![]()
这里我们画出该图像,
显然,某事件发生的概率在0-1之间,根据图像,事件发生的概率越小,那么事件发生的信息量就越大。

于是就引出了接下来的概念
1.2 熵
这里的熵指的是信息熵,它是指对于某事件所有可能性的信息量的期望,即:

这里我们可以进行一些简单的测试:

显然,事件各个情况发生的概率越平均,熵的值就越大,或者换一种说法,事件各种可能的混杂程度越大,熵的值越小。
1.3 相对熵(KL散度)
相对熵的数学公式如下:
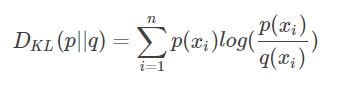
这里设计到对于同一事件的两个分布p和q,这里我们可以将q看成神经网络多分类任务中的预测值,p看成训练的目标值。如果p和q的分布越接近,那么KL散度的值就越小。
这里有一点值得注意,一般情况下,对于分类任务,例如有三种分类x1, x2, x3,神经网络预测的概率q是 [0.1, 0.2, 0.7],这里假设它实际上属于x2类,那么p的分布其实是[0, 1, 0],也就是对于q分布,只有x2的概率是1,其他都是0。
这里附上连续性KL散度的推导过程:
https://blog.csdn.net/Defiler_Lee/article/details/105454724
1.4 交叉熵
根据KL散度的值,我们可以确定两个分布是否相似,因此我们可以使用KL散度作为学习任务的损失函数,但是KL散度的公式具有化简的空间,我们对其进行以下化简:
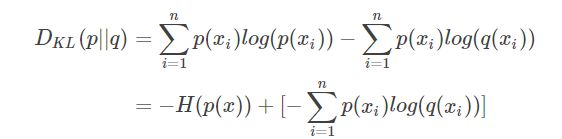
显然式子的前半部分是p的熵,对于确定的p,它的熵也是固定的,那么我们只需要计算后半部分就可以确定两个分布的相似程度,作为训练任务的loss,这后半部分,就是交叉熵。

1.5 小结
我们知道交叉熵的值可以表示两个概率分布的相似程度,它可以作为多分类训练的损失函数,并且就像刚刚举的例子,神经网络所预测的概率往往是例如 [0, 1, 0]的,而且目标值往往是如同 [0, 1, 0] 的分布,接下来我们讲解这样的分布在深度学习中的应用。
2. 交叉熵的应用(pytorch中)
2.1 交叉熵在分类任务中的计算过程
这里我们按照之前举的例子:
| x1 | x2 | x3 | |
| q (Pred) | 0.1 | 0.2 | 0.7 |
| p (Label) | 0 | 1 | 0 |
那么我们按照交叉熵,进行计算,
loss = - ( 0 * log(0.1) + 1 * log(0.2) + 0 * log(0.7) )
= - log( 0.2 )
也就是说,我们只需要计算label是1的那部分,这里假设目标分类结果是xi类,那么我们只需要计算 -log(p(xi)) 即可。
2.2 log_softmax()函数
首先我们需要了解什么是softmax函数,这里可以查看我的这篇博客:softmax 简单讲解
我们通过softmax(),可以得出总和为1的概率分布,经过log运算,我们其实就得出了log(p(xi)),取反即可得出交叉熵。
举个例子:

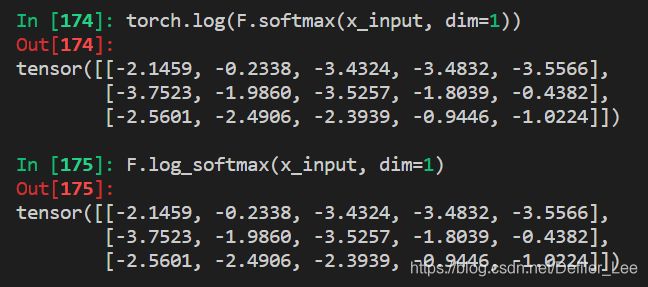
2.3 nll_loss()函数
由之前我们推出的,我们只需要计算分类xi概率,进行log运算,所得的值就可以表示交叉熵并作为loss值(有点绕。。),
(总之就是 如果预测值Pred是 [0.1, 0.2, 0.7] ,然后实际上的分类是第二类,那么我们只需要计算第二个的概率的log值
即 log(0.2) )
实际上,我们往往会同时对多个样本进行训练,这样得出的Pred往往是二维的,例如我们进行图片分类,假设 x_input 是最后一层的输出,其中(3,5)表示每次有 3 张图片需要进行分类,分类总共有五种,比如分别是ABCDE五个字母,然后我们使用softmax将输出的数值,转化为总和为1的概率分布(每行的和为1):

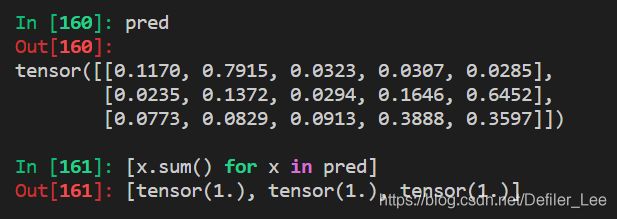
每行都是对图片分类的预测,三行表示有三张图片。
当使用交叉熵均值作为loss函数时,假设这次的lable是 [1, 3, 4,](注意下标从0开始)首先需要计算log_softmax():
交叉熵均值计算过程为(只取label对应的值,参考本文章 2.1)
-(-0.2338 -1.8039 -1.0224 ) / 3 (这里由于数值是直接复制的,所以有些许误差。)

回归正题,可见nll_loss函数,其实就是将x_input每行中与Label对应的值取出来,去掉负号求均值。
2.4 cross_entropy()函数
这里附上cross_entropy函数源码,在我们已经明白了 log_softmax 函数和 nll_loss 函数的基础上,秒懂!!:

所以,cross_entropy函数,其实就是干了log_softmax和nll_loss两件事情,因此我们使用cross_entropy函数时,只需要直接将x_input(最后一层的输出)与 target(label)作为函数的参数调用即可

其中pred_log 是 log_softmax(x_input, dim=1) 的结果
2.5 函数的其他调用方式
| torch.nn | torch.nn.functional (F) |
| CrossEntropyLoss | cross_entropy |
| LogSoftmax | log_softmax |
| NLLLoss | nll_loss |
其中,torch.nn 提供的是类,使用时候需要先实例化。
torch.nn.functional 提供函数,直接使用即可。
参考:
- https://blog.csdn.net/tsyccnh/article/details/79163834
- https://www.cnblogs.com/marsggbo/p/10401215.html
- https://blog.csdn.net/qq_22210253/article/details/85229988