scrapy实现布隆过滤器对接
Bloom Filter
Bloom Filter,中文名称叫作布隆过滤器,是1970年由Bloom提出的,它可以被用来检测一个元素是否在一个集合中。Bloom Filter的空间利用效率很高,使用它可以大大节省存储空间。Bloom Filter使用位数组表示一个待检测集合,并可以快速地通过概率算法判断一个元素是否存在于这个集合中。利用这个算法我们可以实现去重效果。
Bloom Filter的算法
在Bloom Filter中使用位数组来辅助实现检测判断。在初始状态下,我们声明一个包含m位的位数组,它的所有位都是0,如下图所示。
![]()
现在我们有了一个待检测集合,其表示为S={x1, x2, …, xn}。接下来需要做的就是检测一个x是否已经存在于集合S中。在Bloom Filter算法中,首先使用k个相互独立、随机的散列函数来将集合S中的每个元素x1, x2, …, xn映射到长度为m的位数组上,散列函数得到的结果记作位置索引,然后将位数组该位置索引的位置1。例如,我们取k为3,表示有三个散列函数,x1经过三个散列函数映射得到的结果分别为1、4、8,x2经过三个散列函数映射得到的结果分别为4、6、10,那么位数组的1、4、6、8、10这五位就会置为1,如下图所示。
如果有一个新的元素x,我们要判断x是否属于S集合,我们仍然用k个散列函数对x求映射结果。如果所有结果对应的位数组位置均为1,那么x属于S这个集合;如果有一个不为1,则x不属于S集合。
例如,新元素x经过三个散列函数映射的结果为4、6、8,对应的位置均为1,则x属于S集合。如果结果为4、6、7,而7对应的位置为0,则x不属于S集合。
注意,这里m、n、k满足的关系是m>nk,也就是说位数组的长度m要比集合元素n和散列函数k的乘积还要大。
这样的判定方法很高效,但是也是有代价的,它可能把不属于这个集合的元素误认为属于这个集合。我们来估计一下这种方法的错误率。当集合S={x1, x2,…, xn} 的所有元素都被k个散列函数映射到m位的位数组中时,这个位数组中某一位还是0的概率是:
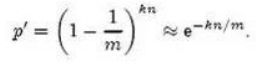
散列函数是随机的,则任意一个散列函数选中这一位的概率为1/m,那么1-1/m就代表散列函数从未没有选中这一位的概率,要把S完全映射到m位数组中,需要做kn次散列运算,最后的概率就是1-1/m的kn次方。
一个不属于S的元素x如果误判定为在S中,那么这个概率就是k次散列运算得到的结果对应的位数组位置都为1,则误判概率为:
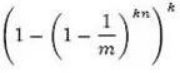
根据:
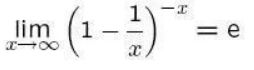
可以将误判概率转化为:
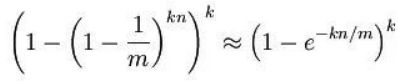
在给定m、n时,可以求出使得f最小化的k值为:
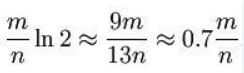
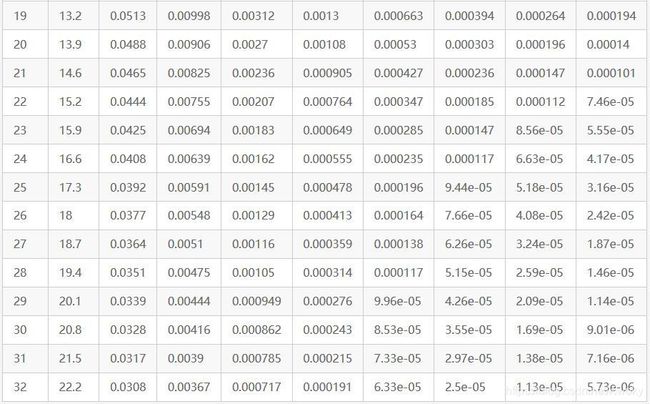
这里将误判概率归纳如下:

scrapy可以使用ScrapyRedisBloomFilter实现对接布隆过滤器
安装:
pip install scrapy-redis-bloomfilter
项目地址代码:
https://github.com/Python3WebSpider/ScrapyRedisBloomFilter
用法
settings.py中添加如下设置:
# Ensure use this Scheduler
SCHEDULER = "scrapy_redis_bloomfilter.scheduler.Scheduler"
# Ensure all spiders share same duplicates filter through redis
DUPEFILTER_CLASS = "scrapy_redis_bloomfilter.dupefilter.RFPDupeFilter"
# Redis URL
REDIS_URL = 'redis://user:pass@localhost:6379'
# Number of Hash Functions to use, defaults to 6
BLOOMFILTER_HASH_NUMBER = 6
# Redis Memory Bit of Bloomfilter Usage, 30 means 2^30 = 128MB, defaults to 30
# Bloom Filter的bit参数,默认30,占用128MB空间,去重量级1亿
BLOOMFILTER_BIT = 30
# Persist
SCHEDULER_PERSIST = True
Spider部分类似如下:
from scrapy import Request, Spider class TestSpider(Spider): name = 'test' base_url = 'https://www.baidu.com/s?wd=' def start_requests(self): for i in range(10): url = self.base_url + str(i) yield Request(url, callback=self.parse) # Here contains 10 duplicated Requests for i in range(100): url = self.base_url + str(i) yield Request(url, callback=self.parse) def parse(self, response): self.logger.debug('Response of ' + response.url)