Python学习 | Pandas入门
pandas是基于NumPy数组构建的,特别是基于数组的函数和不使用for循环的数据处理。
pandas和NumPy最大的不同是pandas是专门为处理表格和混杂数据设计的,而NumPy更适合处理统一的数值数组数据。
pandas经常和其它工具一同使用,如数值计算工具NumPy和SciPy,分析库statsmodels和scikit-learn,和数据可视化matplotlib。
1 pandas的数据结构介绍
两个主要数据结构:Series和DataFrame*
1.1 Series
Series由一组数据(各种NumPy数据类型) 以及一组与之相关的数据标签(即索引) 组成
- 创建series


如果数据被存放在一个Python字典中,也可以直接通过这个字典来创建Series: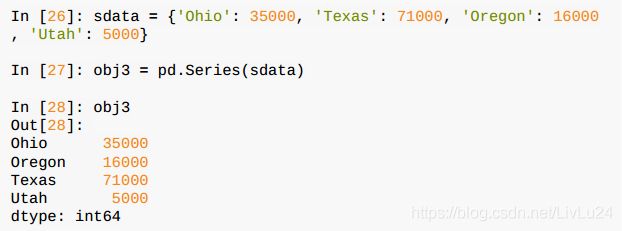
1.2 DataFrame
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等),可以被
看做由Series组成的字典(共用同一个索引) 。
创建DataFrame
- 直接传入一个由等长列表或NumPy数组组成的字典:


- 如果传入的列在数据中找不到,就会在结果中产生缺失值:
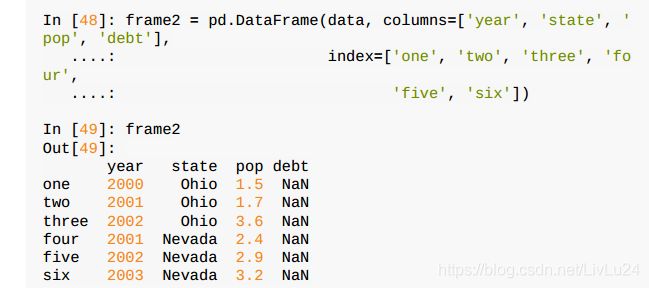
- 创建新列

- 删除列

1.3 索引对象
构建Series或DataFrame时,所用到的任何数组或其他序列的标签都会被转换成一个Index:
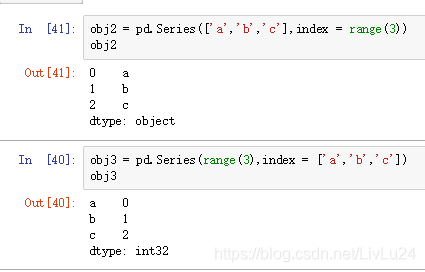

注:与python的集合不同,pandas的Index可以包含重复的标签:
index对象不可修改;
2.基本功能
2.1重新索引
reindex()
重新索引可以做一些插值处理。采用method选项的ffill/bfill可以实现前向值填充:
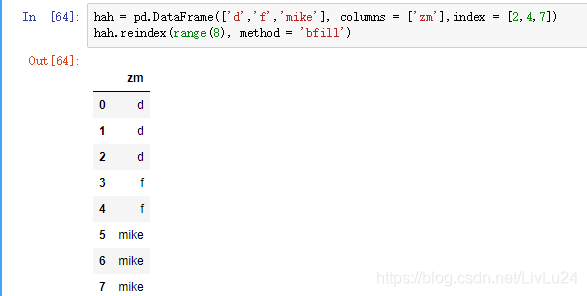

2.2 丢弃指定轴上的项
drop方法
drop是从行标签删除值,通过传递axis=1或axis='columns'可以删除列的值:![]()
注意:drop方法得到的新对象是改变后的数据,但它不会修改原对象的数据,除非在使用drop方法时加上inplace = True
![]()
2.3 索引、选取和过滤
Series索引(obj[...]) 的工作方式类似于NumPy数组的索引,只不过Series的索引值不只是整数。
选取列:
data['w'] #选择表格中的'w'列,使用类字典属性,返回的是Series类型
data.w #选择表格中的'w'列,使用点属性,返回的是Series类型
data[['w']] #选择表格中的'w'列,返回的是DataFrame属性
选取行:和Numpy有不同
1)当用整数作为索引值时,直接采用 如data[1]会报错,应采用以下方式:
data[0:2] #返回第1行到第2行的所有行,前闭后开,包括前不包括后
data[1:2] #返回第2行,从0计,返回的是单行,通过有前后值的索引形式
2)用loc和iloc进行选取(直接用index值或者整数索引,返回的是Series,采用:形式选取返回的是DataFrame)
data['a':'b'] #利用index值选取行,返回的是前闭后闭的DataFrame
data.iloc[0] #取data的第一行,返回的是Series
data.loc['w'] #用列标签取data的第一行,返回的是Series
data.iloc[-1:] #选取DataFrame最后一行,返回的是DataFrame
data.loc['a', 'w'] #取data的a行w列的单一值
data.loc['a',['w']] #取data的a行w列,返回的是Series
data.loc[: , 'w'] #取data的w列,返回的是DataFrame
data.head() #返回data的前几行数据,默认为前五行,需要前十行则dta.head(10)
data.tail() #返回data的后几行数据,默认为后五行,需要后十行则data.tail(10)
2.4 算术运算和数据对齐
两个DataFrame相加或相减,得出的是原来两个DataFrame的并集,没有重合的地方以NaN显示。
如果不想显示NaN值,可以传入一个fill_value参数:
![]()
除法:1/dif 和dif.rdiv(1)相等
2.5 DataFrame和Series之间的运算
广播:当arr减去arr[0],每一行都会执行这个操作。这就叫做广播(broadcasting)
在行上广播:
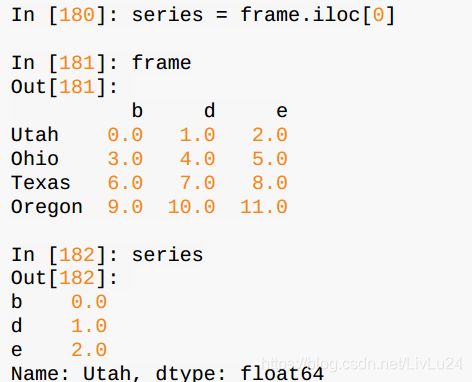

在列上广播:
![]()
2.6 函数应用和映射
使用函数获取每列的最大值减去最小值

获取每行的最大值减去最小值
![]()

格式化浮点值字符串,使用applymap

2.7 排序和排名
排序:
可使用sort_index方法,它将返回一个已排序的新对象,对于DataFrame,可以根据任意一个轴排序。
升序:![]()
倒序:
![]()
![]() ,在排序时,任何缺失值默认都会被放到Series的末尾。
,在排序时,任何缺失值默认都会被放到Series的末尾。
根据一个或多个列中的值进行排序,将一个或多个列的名字传递给sort_values的by选项![]()
排名:
rank方法
rank会对重复重现的数值分配一个平均排名
根据值在原数据中出现的顺序给出排名: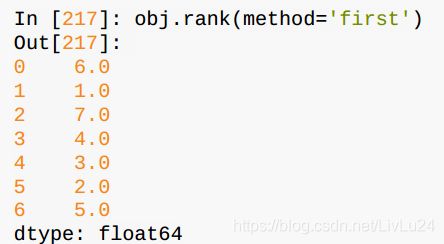 \
\
其他方法如下:

3 汇总和计算描述统计
3.1 汇总统计方法
sum()、mean()函数分别进行求和、求平均运算
sum()返回一个含有列的和的series
sum(axis=1)返回一个含有行的和的series
在进行运算时,NA值会自动被排除,除非整个切片(这里指的是行或列) 都是NA。通过skipna选项可以禁用该功能: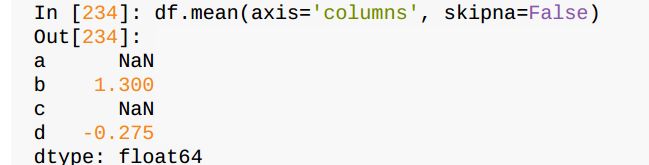

cumsum()累计求和
描述统计方法:describe()
数值型:

非数值型:



3.2 唯一值、值计数以及成员资格
unique()得到Series中的唯一值数组,uniques.sort()返回排序后的数组
value_counts()计算Series中各值出现的频率