当下流行的激光点云目标检测算法(SECOND、PointPillars、SA-SSD)原理分析对比。
一、SECOND(2018)(单阶段,point-based)
论文:https://www.mdpi.com/1424-8220/18/10/3337
Github:https://github.com/traveller59/second.pytorch
A、网络结构
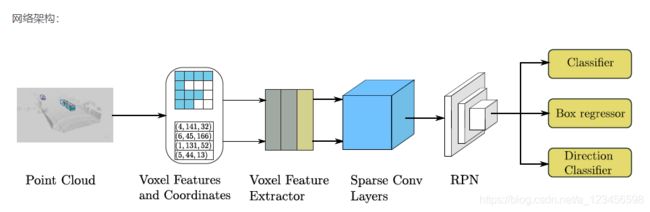
1、Point Cloud Grouping
在这里,我们遵循[14]中描述的简单过程来获得点云数据的体素表示。 我们首先根据体素数的指定限制预先分配缓冲区;然后,w 迭代点云并将点分配给它们相关的体素,并保存体素坐标和每个体素的点数。 我们检查基于h的体素的存在 迭代过程中的灰分表。 如果与点相关的体素还不存在,我们在哈希表中设置相应的值;否则,我们将体素数增加一个。 我的 一旦体素数目达到指定的极限,迭代过程将停止。 最后,我们得到了所有体素,它们的坐标和每个体素的点数,用于实际的体素数。 f 或者在相关类中检测汽车和其他物体,我们根据[[3,1]×[0,70.4]m沿z×y×x轴的地面真相分布来裁剪点云。 为了上帝 在[[3,1]×[[20,20]×m处使用作物点。对于我们的较小模型,我们只使用[[3,1]×[0,52.8]m范围内的点来增加干扰 NCE速度。 裁剪区域需要根据体素大小进行轻微调整,以确保生成的特征映射的大小可以在后续网络中正确地下采样。 为了艾尔 任务,我们使用体素大小为vD=0.4×vH=0.2,vW=0.2m。每个空体素中用于汽车检测的最大点数设置为T=35,这是根据TH的分布选择的 在KITT I数据集中,每个体素的点数;行人和骑自行车者检测的相应最大值设置为T=45,因为行人和骑自行车者相对较小,因此 对于体素特征提取,需要更多的点。
2、Voxelwise Feature Extractor
我们使用体素特征编码(V FE)层,如[14]所述,提取体素特征。 一个VFE层将相同体素中的所有点作为输入,并使用一个完全连接的网络(FCN)cons 采用线性层、批归一化(批规范)层和校正线性单元(ReLU)层提取点特征。 然后,它使用element wise max池来获得本地ag 每个体素的灰色特征。 最后,它将获得的特征平铺并将这些平铺特征和点状特征连接在一起。 我们使用VFE(cout)来表示一个VFE层,它被转换 均方根将输入特征转化为cout维数输出特征。 类似地,FCN(Cout)表示一个线性匹配规范-ReLU层,它将输入特征转换为cout维输出特征。 作为一个 整个体素特征提取器由几个VFE层和一个FCN层组成。
3、Sparse Convolutional Middle Extractor
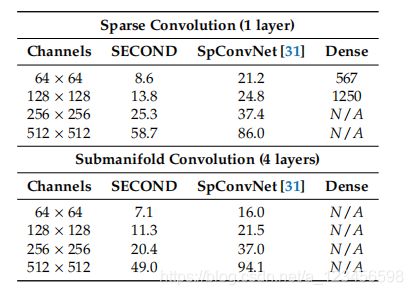
Review of Sparse Convolutional Networks
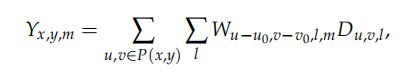
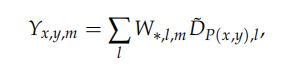






4、Region Proposal Network
RPN[1]最近开始在许多检测框架中使用。 在本工作中,我们使用单镜头多盒检测器(SSD)样[32]体系结构来构建RPN体系结构。 输入到 RPN由稀疏卷积中间提取器的特征映射组成。 RPN体系结构由三个阶段组成。 每个阶段从一个下采样的卷积层开始,即I 其次是几个卷积层。 在每个卷积层之后,应用批规范和ReLU层。 然后,我们将每个阶段的输出采样到相同大小和COCA的特征映射 将这些特征映射表示为一个特征映射。 最后,将三个1×1卷积应用于类、回归偏移和方向的预测。
5、Anchors and Targets
由于要检测的对象是近似固定大小的,我们使用基于KITTI训练中所有地面真相的大小和中心位置的方法确定的固定大小的锚 旋转为0度和90度。 对于汽车,我们使用尺寸为w=1.6×l=3.9h=1.56m的锚,以z=1.0m为中心。对于行人,我们使用尺寸为w的锚 =0.6×l=0.8×h=1.73m,对于骑自行车的人来说,锚的尺寸为w=0.6,l=1.76,h=1.73m;两者都以z为中心=0.6m。
每个锚被分配一个分类目标的一个热向量,一个盒子回归目标的7向量和一个方向分类目标的一个热向量。 不同的班级有不同的thr 用于匹配和非匹配的Eshold。 对于汽车,锚被分配到地面真相对象使用交叉过度联合(IoU)阈值0.6,并被分配到背景(负)I 如果他们的爱我们小于0.45。 在训练过程中,IoUs在0.45到0.6之间的锚被忽略。 对于行人和骑自行车的人,我们使用不匹配阈值为0.35,m值为0.5 初始阈值。
对于回归目标,我们使用以下框编码函数:

其中x、y和z分别是中心坐标;w、l和h分别是宽度、长度和高度;θ是围绕z轴的偏航旋转;下标t、a和g表示编码的val 分别是UE、锚和地面真相;da=p(La)2(WA)2是锚盒底部的对角线。
B、训练相关
1、loss

2、数据增强
3、最优化
利用随机梯度下降(SGD)对所提出的第二检测器进行了训练)。 我们使用了一个Adam优化器运行在GTX1080Ti GPU上,每个小型舱总共有三点云。 所有模特都是 训练160个历元(200K迭代)。 初始学习率为0.0002,指数衰减因子为0.8,每15个时代衰减一次。 衰变重量为0.0001,β1值为0.9和 β2值为0.999。 用单个GTX1080TiGPU训练大型汽车检测网络需要19h,只需要9h就可以训练较小的模型。
4、Network Details
我们建议使用两个网络:大网络和小网络。 位于摄像机视野外的点需要移除。
对于汽车检测,第二层使用两个VFE层,即大网络的VFE(32)和VFE(128),小网络的VFE(32)和VFE(64),遵循线性(128)层。 因此,一角钱 大网络的输出稀疏张量为128×10×400×352,小网络为128×10、320×264。 然后,我们使用两阶段稀疏CNN进行特征提取和二值化 关于还原,如图3所示。 每个卷积层遵循批处理范数层和ReLU层。 所有稀疏卷积层都有64输出特征映射,内核大小为(3,1,1)内核 大小和步幅(2,1,1)。 中间块的输出尺寸为64×2×400×352为大网络。 一旦输出被重塑到128×400×352,RPN网络ca 应用。 图4显示了RPN的体系结构。 我们使用Conv2D(cout,k,s)表示Conv2D-舱口规范-ReLU层和DeConv2D(cout,k,s)表示DeConv2D-舱口规范-ReLU层,wh 其中cout是输出通道的数目,k是内核大小,s是步长。 因为所有层在所有维度上都有相同的大小,所以我们使用k和s的标量值。所有Conv2D层ha 有相同的填充,所有的DeConv2D层都有零填充。 在RPN的第一阶段,应用了三个Conv2D(128,3,1(2)层。 然后,五个Conv2D(128,3,1(2)层和五个Conv2D(256 分别在第二和第三阶段应用3、1(2)层。 在每个阶段,s只=第一卷积层的2;否则,s=1。 我们应用一个单一的DeConv2D(128,3,s)层f 或者每个阶段的最后一个卷积,三个阶段的s=1、2和4,依次进行。 对于行人和骑车人的检测,与汽车检测相比,唯一的区别是条纹 在RPN中,第一卷积层的De为1,而不是2。

(详细的RPN结构。 蓝色框表示卷积层,紫色框表示级联的层,天空蓝色框表示跨步-2下采样卷积层,和 棕色盒表示转置卷积层。)
二、PointPillars(2019,pixel-based,2D卷积)
论文:https://arxiv.org/abs/1812.05784
Github: https://github.com/nutonomy/second.pytorch
A、网络结构

(图2:该网络的主要组成部分是Pillar Featrue Net、Backbone和SSD检测头。网络首先将原始点云转换为堆叠柱张量和PIL 拉尔指数张量。然后用编码器使用堆叠的支柱来学习一组特征,这些特征可以分散到卷积神经网络的2D伪图像上。通过Backbone进一步提取特征。最后将特征输入SSD检测头,预测对象的三维检测框。)
Point-Pillars接受点云作为输入,并估计面向汽车、行人和骑自行车的3D盒。 它由三个主要阶段组成(图2):(1)转换的特征编码器网络 稀疏伪图像的点云;(2)将伪图像处理为高级表示的二维卷积骨干;(3)检测和回归3D检测框的检测头SSD。
1、Pointcloud to Pseudo-Image
为了应用二维卷积结构,我们首先将点云转换为伪图像。
我们用 I 表示点云中的一个点,坐标为x,y,z和反射率r。作为第一步,点云被离散为x-y平面上均匀间隔的网格,形成一组点云柱P:|P|=B。 请注意,不需要超参数来控制z维中的绑定。 然后用xc、yc、zc、xp和yp对每个支柱中的点进行增强,其中c下标表示与支柱中所有点的算术平均值的距离,p下标表示与支柱x,y中心的偏移量。 增强激光雷达点 l 现在是D=9维。
由于点云的稀疏性,这组柱子大多是空的,而非空柱一般都有很少的点。 例如,从HDL-64E Velodyne激光雷达中回收的点云(收录在KITTI数据集中),每0.162平方米,有6k-9k非空柱的稀疏度达到97%。 这种稀疏性是通过对每个样本(P)的非空柱数和每个柱(N)的点数施加限制来利用的,以创建一个密集的尺寸张量(D,P,N)。 如果一个样本或支柱持有太多的数据来拟合这个张量,则数据被随机抽样。 相反,如果样本或支柱的数据太少,无法填充张量,则应用零填充。

(图3:定性分析KITTI结果。 我们展示了激光雷达点云(顶部)的鸟瞰图,以及投影到图像中的三维包围框,以便更清晰地可视化。 注意我们的方法只使用激光雷达。 我们展示了汽车(橙色)、自行车(红色)和行人(蓝色)的预测箱。 地面真相框显示为灰色。盒子的方向是用一条线连接底部中心到盒子的前面)

( 图4:KITTI的失败案例。 与图3相同的可视化设置,但侧重于几种常见的故障模式)
接下来,我们使用PointNet的简化版本。其中,对于每个点,一个线性层被应用,然后是Batch-Norm[10]和ReLU[19]来生成一个(C,P,N)大小的张量。 这之后是最大值 在通道上操作以创建大小的输出张量(C,P)。 请注意,线性层可以表示为跨越张量的1x1卷积,从而产生非常有效的计算。
一旦编码,这些特征就会分散到原始的支柱位置,以创建一个大小为(C,H,W)的伪图像,其中H和W表示画布的高度和宽度。
2.、Backbone
我们使用与[31]相似的骨干,结构如图2所示。 主干网有两个子网:一个自顶向下的网络,以越来越小的空间分辨率和a产生特征;第二个网络,执行自上而下功能的上采样和级联。 自顶向下的骨干可以用一系列的块块(S,L,F)来表征。 每个块工作在步长S(相对于原始输入伪图像测量)。 一个块有L 3x3 2D卷积层与F输出通道,每个跟随BatchNorm和一个ReLU。该层内的第一个卷积具有跨步![]() ,以确保块在接收到跨步Sin的输入BLOB后在跨步S上工作。 块中的所有后续卷积都有步幅1。
,以确保块在接收到跨步Sin的输入BLOB后在跨步S上工作。 块中的所有后续卷积都有步幅1。
每个自上而下的块的最终特征通过上采样和级联组合如下。 首先,特征被放大,从最初的步长到最后的步长(Sin,Sout,FideSout(两者都再次测量WRT。 原始伪图像)使用带F最终特征的转置2D卷积。 接下来,将BatchNorm和ReLU应用于upsamped特性。 最终输出特征是来自不同步幅的所有特性的级联。
3、Detection Head
在本文中,我们使用SSD[18]设置来执行三维目标检测。 类似于SSD,我们使用2D交叉在联合(IoU)[4]上匹配先验框到地面真相。 球箱高度和高程不用于匹配;相反,给定2D匹配,高度和高程成为额外的回归目标。
B、训练方法
在这一部分中,我们描述了我们的网络参数和我们优化的损失函数。
1、Network
不是预先训练我们的网络,所有的权重都是随机初始化的,使用均匀的分布,就像在[8]中一样。
编码器网络具有C=64输出特性。 除了第一个街区的步幅外,汽车和行人/骑自行车的骨干是相同的( 汽车的S=2,行人/骑自行车的S=1)。 这两个网络都由三个块组成,Block1(S,4,C),Block2(2S,6,2C)和Block3(4S,6,4C)。每个块由以下上采样步骤进行上采样:Up1(S,S,2C)、Up2(2S,S,2C)和Up3(4S,S,2C)。 然后将Up1、Up2和Up3的特征连接在一起,为检测头创建6C特征。
2、loss
我们使用SECOND[28]中引入的相同的损失函数。 地面真值框和锚由(x,y,z,w,l,h,θ)定义。 地面真相与锚a之间的定位回归残差重新定义:

其中![]() 和
和 分别代表地面真相和锚盒和
分别代表地面真相和锚盒和![]() 。 总体定位损失为:
。 总体定位损失为:

由于角度定位损失不能区分翻转框,我们在离散化方向[28]Ldir上使用Softmax分类损失,使网络能够学习航向。
对于物体分类损失,我们使用焦点损失[16]:

其中pa是锚的类概率。 我们使用α=0.25和γ2的原始纸张设置。 因此总损失为:

其中Npos是正锚和βloc的数量=2,βcls=1,和βdir0.2。
为了优化损失函数,我们使用初始学习速率为2∗![]() , 每15次将学习速率衰减0.8倍,并训练160次。 我们使用2个单位的批处理大小作为验证集,4个单位作为我们的测试提交。
, 每15次将学习速率衰减0.8倍,并训练160次。 我们使用2个单位的批处理大小作为验证集,4个单位作为我们的测试提交。
三、SA-SSD(2020)(单阶段,结合二阶段特征提取的优势)
https://blog.csdn.net/a_123456598/article/details/107143972