Python学习笔记(一):Numpy库(上)
前言
Numpy 是 Python 专门处理高维数组计算的包。直接pip install numpy进行安装,或者安装Anaconda,其中含有大量的机器学习和数据相关的Python模块。如果在安装或者学习过程中出现什么问题的话可以进入Numpy官网查看相关信息。在使用Numpy库之前首先我们要引用它:
import numpy as np
因为每次使用Numpy中的方法或函数都要写numpy字数有点多,所以我们可以用np作为别名。
之所以要额外引入数组这一种数据结构在于它的计算效率非常高。下面是对数组和列表每个元素进行平方的运算速度对比:
先随机生成大小为10000000的数组和列表:
Array = np.arange(10000000)
List = list(range(10000000))
然后分别对其中的每个元素进行平方处理:
start1 = t.perf_counter()
Array = Array ** 2
end1 = t.perf_counter()
print("数组平方用时为{:4f}s".format(end1 - start1))
start2 = t.perf_counter()
for i in List:
i = i ** 2
end2 = t.perf_counter()
print("列表平方用时为{:4f}s".format(end2 - start2))
得到结果:
数组平方用时为0.021923s
列表平方用时为2.955364s
所以我们可以看出二者的运算速度相差了上百倍,所以numpy数组显然更适合做数值运算。
一、ndarray数组对象
1、数组的初步认识
NumPy 最重要的一个特点是其 n 维数组对象 ndarray,它是一系列同类型数据的集合所组成数据结构,以 0 下标为开始进行集合中元素的索引。ndarray 数组中的元素用的最多是数值型元素,平时我们说的一维、二维、三维数组长下面这个样子 (对应着线、面、体)。
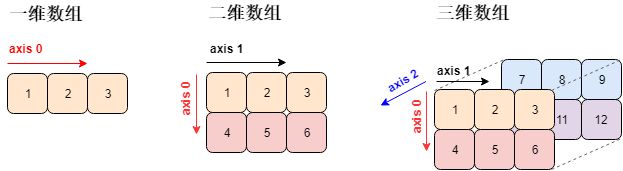
axis,中文叫轴,一个数组是多少维度就有多少根轴。 Python 计数都是从 0 开始的,如下图:

2、数组的创建
(1)由python中的列表和元组等数据类型创建
这种方法主要用到np.array()函数,参数里面是元组或者列表都可以:
a = np.array([[2,3,4,7,5],[4,8,5,7,2]])
b = np.array(((1,2,5,3,7),(3,7,2,9,5)))
print("a=\n{}\n".format(a))
print("b=\n{}\n".format(b))
a=
[[2 3 4 7 5]
[4 8 5 7 2]]
b=
[[1 2 5 3 7]
[3 7 2 9 5]]
元组或列表混着来也可以:
c = np.array([(1,3,7,5,2),[2,7,4,9,6]])
print("c=\n{}\n".format(c))
c=
[[1 3 7 5 2]
[2 7 4 9 6]]
(2)定隔定点创建
这种创建方式一共有两种函数:
- np.arange():固定元素大小间隔
- np.linspace():固定元素个数
np.arange()函数的定义如下:
numpy.arange(start, stop, step, dtype)
参数说明:
| 参数 | 说明 |
|---|---|
| start | 起始值,默认为0 |
| stop | 终止值(不能为空且不包括) |
| step | 步长,默认为1 |
| dtype | 返回ndarray的数据类型,如果没有提供,则会使用输入数据的类型。 |
下面是具体例子:
d1 = np.arange(5)
d2 = np.arange(2,5)
d3 = np.arange(2,8,2)
print("d1=\n{}\n".format(d1))
print("d2=\n{}\n".format(d2))
print("d3=\n{}\n".format(d3))
d1=
[0 1 2 3 4]
d2=
[2 3 4]
d3=
[2 4 6 8]
np.linspace()函数的定义如下:
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
参数说明:
| 参数 | 说明 |
|---|---|
| start | 序列的起始值 |
| stop | 序列的终止值,如果endpoint为true,该值包含于数列中 |
| num | 要生成的等步长的样本数量,默认为50 |
| endpoint | 该值为 true 时,数列中包含stop值,反之不包含,默认是True。 |
| retstep | 如果为 True 时,生成的数组中会显示间距,反之不显示。 |
| dtype | 返回ndarray的数据类型,如果没有提供,则会使用输入数据的类型。 |
下面是具体例子:
d4 = np.linspace(1,100,8)
d5 = np.linspace(1,100,8,endpoint=False)
print("d4=\n{}\n".format(d4))
print("d5=\n{}\n".format(d5))
d4=
[ 1. 15.14285714 29.28571429 43.42857143 57.57142857 71.71428571 85.85714286 100. ]
d5=
[ 1. 13.375 25.75 38.125 50.5 62.875 75.25 87.625]
(3)特殊数组创建
这种创建方式有以下这些函数:
- ones()函数生成元素全为1的多维数组,参数为元组类型
- zeros()函数生成元素全为0的多维数组,参数为元组类型
- full()函数根据第一个参数生成一个多维数组,元素全为第二个参数
- eye()函数生成一个n维的单位矩阵,参数为n
- ones_like()函数根据参数中的数组形状生成一个全为1的数组
- zeros_like()函数根据参数中的数组形状生成一个全为0的数组
- full_like()函数根据第一个参数数组的形状生成一个全为第二个参数的数组
下面是具体例子:
e = np.ones((2,2,5))
f = np.zeros((2,5))
g = np.full((2,5),8)
h = np.eye((3))
# a=[[2 3 4 7 5][4 8 5 7 2]]
i = np.ones_like(a)
j = np.zeros_like(a)
k = np.full_like(a,8)
print("e=\n{}\n".format(e))
print("f=\n{}\n".format(f))
print("g=\n{}\n".format(g))
print("h=\n{}\n".format(h))
print("i=\n{}\n".format(i))
print("j=\n{}\n".format(j))
print("k=\n{}\n".format(k))
e=
[[[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]]
[[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]]]
f=
[[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]]
g=
[[8 8 8 8 8]
[8 8 8 8 8]]
h=
[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]
i=
[[1 1 1 1 1]
[1 1 1 1 1]]
j=
[[0 0 0 0 0]
[0 0 0 0 0]]
k=
[[8 8 8 8 8]
[8 8 8 8 8]]
3、数组的属性
下表展示了数组的一些常见的属性:
| 属性 | 含义 |
|---|---|
| naim | 表示数组的秩,即数组的维数 |
| shape | 表示数组是几行几列的 |
| size | 表示数组元素的个数 |
| dtype | 表示数组的元素类型 |
| itemsize | 数组中每个元素的大小,以字节为单位 |
下面是具体的例子
# a=[[2 3 4 7 5][4 8 5 7 2]]
print(a.ndim)
print(a.shape)
print(a.size)
print(a.dtype)
print(a.itemsize)
2
(2, 5)
10
int32
4
其中下面列表中列举了常用的的数组的元素类型:
| 名称 | 描述 | 简写 |
|---|---|---|
| np.bool | 用一个字节存储的布尔类型(True或False) | ‘b’ |
| np.int8 | 一个字节大小,-128 至 127 | ‘i’ |
| np.int16 | 整数,-32768 至 32767 | ‘i2’ |
| np.int32 | 整数,-232 至 232 -1 | ‘i4’ |
| np.int64 | 整数,-264 至 264 - 1 | ‘i8’ |
| np.uint8 | 无符号整数,0 至 255 | ‘u’ |
| np.uint16 | 无符号整数,0 至 65535 | ‘u2’ |
| np.uint32 | 无符号整数,0 至 232 - 1 | ‘u4’ |
| np.uint64 | 无符号整数,0 至 264 - 1 | ‘u8’ |
| np.float16 | 半精度浮点数:16位,正负号1位,指数5位,精度10位 | ‘f2’ |
| np.float32 | 单精度浮点数:32位,正负号1位,指数8位,精度23位 | ‘f4’ |
| np.float64 | 双精度浮点数:64位,正负号1位,指数11位,精度52位 | ‘f8’ |
| np.complex64 | 复数,分别用两个32位浮点数表示实部和虚部 | ‘c8’ |
| np.complex128 | 复数,分别用两个64位浮点数表示实部和虚部 | ‘c16’ |
| np.object_ | python对象 | ‘O’ |
| np.string_ | 字符串 | ‘S’ |
| np.unicode_ | unicode类型 | ‘U’ |
二、数组的存储与读入
1、CSV文件格式
CSV文件的存储和读入只适用于一维和二维数组
(1)存储
将数组储存为CSV格式的函数如下:
np.savetxt(frame, array, fmt='%.18e', delimiter=None)
| 参数 | 说明 |
|---|---|
| frame | 存储的文件名(也可以是字符串,产生器,压缩文件) |
| array | 存入文件的数组 |
| fmt | 数组元素写入文件的格式,例如:%d %.2f %.18e |
| delimiter | 分割字符串,默认是任何空格,如果是CSV文件,则使用’,'它可以生成任意带有分割符的文件 |
例如:
a = np.arange(60).reshape(5,12)
print('a=\n{}\n'.format(a))
np.savetxt('a.csv',a,fmt='%d',delimiter=',')
a=
[[ 0 1 2 3 4 5 6 7 8 9 10 11]
[12 13 14 15 16 17 18 19 20 21 22 23]
[24 25 26 27 28 29 30 31 32 33 34 35]
[36 37 38 39 40 41 42 43 44 45 46 47]
[48 49 50 51 52 53 54 55 56 57 58 59]]
下图是用Excel打开a.csv文件:

(2)读入
将CSV格式的数组文件读入的函数如下:
np.loadtxt(frame, dtype=np.float, delimiter=None, skiprows=0, usecols=None, unpack=False)
| 参数 | 说明 |
|---|---|
| frame | 存储的文件名(也可以是字符串,产生器,压缩文件) |
| dtype | 需要将文件的数据转化为特定格式,由dtype指定 |
| delimiter | 分割字符串,默认是任何空格,如果是CSV文件,则使用’,’ |
| skipprows | 读取文件时需要跳过的行数,默认为0 |
| usecols | 选取指定的列,默认为全部 |
| unpack | 如果是True,把每一列当成一个向量输出写入不同变量(默认为False) |
例如我要读取a.csv文件且不要第一行:
b = np.loadtxt('a.csv',dtype=np.int,delimiter=','skiprows=1)
print('b=\n{}\n'.format(b))
b=
[[12 13 14 15 16 17 18 19 20 21 22 23]
[24 25 26 27 28 29 30 31 32 33 34 35]
[36 37 38 39 40 41 42 43 44 45 46 47]
[48 49 50 51 52 53 54 55 56 57 58 59]]
结果数组b与数组a相一致。而如果我要选取两列分别赋给两个变量的话,就要通过usecols和unpack变量,下面是把文件中数组的第一列:
b,c = np.loadtxt('a.csv',dtype=np.int,delimiter=',',usecols=(0, 2),unpack=True)
b=
[ 0 12 24 36 48]
c=
[ 2 14 26 38 50]
2、其他格式
由于CSV文件的存储和读入只适用于一维和二维数组,所以当遇见多维数组或者不想储存为CSV格式时我们可以使用tofile()方法与fromfile()函数存储和读入数组。
(1)存储
数组的储存我们可以使用tofile()方法,其定义为:
a.tofile(frame,sep='',format='%s')
| 参数 | 说明 |
|---|---|
| frame | 存储的文件名(也可以是字符串,产生器,压缩文件) |
| sep | 设置分隔符(默认为空串,如果为空串文件将用二进制方式储存) |
| format | 数组元素写入文件的格式 |
例如:
c = np.arange(100).reshape(2,5,10)
print('c=\n{}\n'.format(c))
c.tofile('c.txt',sep=',',format='%d')
c=
[[[ 0 1 2 3 4 5 6 7 8 9]
[10 11 12 13 14 15 16 17 18 19]
[20 21 22 23 24 25 26 27 28 29]
[30 31 32 33 34 35 36 37 38 39]
[40 41 42 43 44 45 46 47 48 49]]
[[50 51 52 53 54 55 56 57 58 59]
[60 61 62 63 64 65 66 67 68 69]
[70 71 72 73 74 75 76 77 78 79]
[80 81 82 83 84 85 86 87 88 89]
[90 91 92 93 94 95 96 97 98 99]]]
下图是用记事本打开c.txt文件:

从图中我们可以看出,数组通过tofile()方法储存在文件中的形式是一维数组,并不是它本来的形状。所以我们通常还需要建立一个维度信息文件用来储存维度信息方便读入。
如果我们采用二进制形式存储(二进制形式可以压缩文件大小):
c.tofile('c1.txt',format='%d') #二进制形式的存储和读入
用记事本打开c1.txt文件,文件中都是乱码:
(2)读入
将数组文件读入可以使用fromfile()函数,它的定义为:
np.fromfile(frame,dtype=float,count=-1,sep='')
| 参数 | 说明 |
|---|---|
| frame | 存储的文件名(也可以是字符串,产生器,压缩文件) |
| dtype | 文件的数据类型(默认为浮点数) |
| count | 设置读取数据的个数(默认为-1,表示全部读入) |
| sep | 设置分隔符(默认为空串,如果为空串文件将用二进制方式读入) |
例如:
d = np.fromfile('c.txt',dtype=np.int,count=-1,sep=',').reshape(2,5,10)
print('d=\n{}\n'.format(d))
d=
[[[ 0 1 2 3 4 5 6 7 8 9]
[10 11 12 13 14 15 16 17 18 19]
[20 21 22 23 24 25 26 27 28 29]
[30 31 32 33 34 35 36 37 38 39]
[40 41 42 43 44 45 46 47 48 49]]
[[50 51 52 53 54 55 56 57 58 59]
[60 61 62 63 64 65 66 67 68 69]
[70 71 72 73 74 75 76 77 78 79]
[80 81 82 83 84 85 86 87 88 89]
[90 91 92 93 94 95 96 97 98 99]]]
如果是读取二进制文件,如c1.txt:
d = np.fromfile('c1.txt',dtype=np.int).reshape(2,5,10)
print('d=\n{}\n'.format(d))
d=
[[[ 0 1 2 3 4 5 6 7 8 9]
[10 11 12 13 14 15 16 17 18 19]
[20 21 22 23 24 25 26 27 28 29]
[30 31 32 33 34 35 36 37 38 39]
[40 41 42 43 44 45 46 47 48 49]]
[[50 51 52 53 54 55 56 57 58 59]
[60 61 62 63 64 65 66 67 68 69]
[70 71 72 73 74 75 76 77 78 79]
[80 81 82 83 84 85 86 87 88 89]
[90 91 92 93 94 95 96 97 98 99]]]
从上面我们可以发现得到的两个d数组都与c数组一致。
3、.npy格式
Numpy本身有它自己的.npy文件格式,使用np.save()函数和np.load()函数存储和读入。
(1)存储
使用np.save()函数对数组进行存储,下面是其定义:
np.save(fname,array)
| 参数 | 说明 |
|---|---|
| frame | 文件名,扩展名为.npy,压缩文件的扩展名为.npz |
| array | 存入文件的数组 |
例如:
np.save('c.npy',c)
np.save()函数其实是用二进制形式存储,且把维度信息存储下来。如果用记事本打开c.npy文件,可以发现里面是乱码:

通过与c1.txt文件对比我们可以发现二者之间的差别就是c.npy文件第一行多了维度信息。正是因为这一点所以使用np.save()函数储存多维数组时不用额外建立一个文件储存维度信息。
(2)读入
.npy或者.npz文件的读入使用np.load()函数,其定义如下:
np.load(fname)
| 参数 | 说明 |
|---|---|
| frame | 文件名,扩展名为.npy,压缩文件的扩展名为.npz |
例如:
d = np.load('c.npy')
print('d=\n{}\n'.format(d))
d=
[[[ 0 1 2 3 4 5 6 7 8 9]
[10 11 12 13 14 15 16 17 18 19]
[20 21 22 23 24 25 26 27 28 29]
[30 31 32 33 34 35 36 37 38 39]
[40 41 42 43 44 45 46 47 48 49]]
[[50 51 52 53 54 55 56 57 58 59]
[60 61 62 63 64 65 66 67 68 69]
[70 71 72 73 74 75 76 77 78 79]
[80 81 82 83 84 85 86 87 88 89]
[90 91 92 93 94 95 96 97 98 99]]]
三、数组的索引和切片
1、类似Python基础语法的索引和切片
(1)一维数组
一维数组的索引和切片和列表类似
m = np.array([1,13.375,25.75,38.125,50.5,62.875,75.25,87.625])
print("m=\n{}\n".format(m))
print("m数组的第3个元素是:{}\n".format(m[2]))
print("m数组从第2到第7个元素偶数序号的元素是:{}\n".format(m[1:6:2]))
m=
[ 1. 13.375 25.75 38.125 50.5 62.875 75.25 87.625]
m数组的第3个元素是:25.75
m数组从第2到第7个元素偶数序号的元素是:[13.375 38.125 62.875]
(2)二维数组
二维数组的索引把每个维度的序号都写出来,维度序号之间用逗号分割,二维数组的切片和Matlab类似,维度之间用逗号隔开,每个维度的切片和一维数组一样。其他多维数组也是一样。
p = np.arange(24).reshape((2,3,4))
print("p=\n{}\n".format(p))
print("p数组第一维度的第1个元素的第2行第3个元素是:{}\n".format(p[0,1,2]))
print("p数组第一维度的第2个元素的第3行的所有元素是:{}\n".format(p[1,2]))
print("p数组第一维度的最后1个元素的倒数第二行的所有元素是:{}\n".format(p[-1,-2]))
print("p数组偶数列的所有元素是:\n{}\n".format(p[:,:,1::2]))
p=
[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]
p数组第一维度的第1个元素的第2行第3个元素是:6
p数组第一维度的第2个元素的第3行的所有元素是:[20 21 22 23]
p数组第一维度的最后1个元素的倒数第二行的所有元素是:[16 17 18 19]
p数组偶数列的所有元素是:
[[[ 1 3]
[ 5 7]
[ 9 11]]
[[13 15]
[17 19]
[21 23]]]
(3)索引和切片的区别
在这里我们要注意:虽然切片可以看作是多次索引,但二者还是有区别的:
- 切片得到的是原数组的一个视图,修改切片中的内容会改变原数组
- 索引得到的是原数组的一个复制,修改索引中的内容不会改变原数组
比如:如果是修改索引中的内容,像如果我将通过索引得到数组a的第1行第3个元素值的变量的值修改为10,但是a数组本身并不会改变:
# a = [[2,3,4,7,5],[4,8,5,7,2]]
x = a[0,2]
x = 10
print(a)
[[2 3 4 7 5]
[4 8 5 7 2]]
但是如果修改切片中的内容,像我将通过切片得到数组a的第一行第2到第4元素的变量y的第2个值变为10(也就是数组a的第1行第3个元素值),那么修改之后数组a会发生变化:
y = a[0,1:4]
y[1] = 10
print(a)
[[ 2 3 10 7 5]
[ 4 8 5 7 2]]
2、整数数组索引
Numpy中不仅仅像Python序列中一样只能用整数来索引,还可以用整数数组来索引。
(1)设定行和列中不同的索引
先来看个例子:
print(a[[0,1],[0,4]])
[2 2]
这里得到的结果并不是数组a通过整数索引:[0,1],[0,4]对应的第1行第2和第5个元素3,5。而是数组a通过整数索引:[0,0],[1,4]对应的第1行第1个元素和第2行第5个元素2,2。
这里我们可以把第n个数组当作是被索引的元素的第n根轴(axis n-1)上对应位置的集合。 比如上面例子中的两个元素分别位于第1和第2行,所以第一个数组为[0,1]。而它们在各自行上分别是处于第1列和第5列,所以第2个数组为[0,4]。
下面再举一个例子:通过整数数组索引得到 4X3 数组中的位于四个角的元素。
x = np.array([[0,1,2],[3,4,5],[6,7,8],[9,10,11]])
print ("x = \n{}".format(x))
y = x[[0,0,-1,-1],[0,-1,0,-1]]
print("数组x的四个角的元素是:{}".format(y))
x =
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
数组x的四个角的元素是:[ 0 2 9 11]
(2)按特定顺序获取特定元素
通过上面介绍的整数数组的索引方法我们可以按特定顺序获取特定元素:例如我想按照4,1,2的顺序获取数组第1,2,4行:
print(x[[3,0,1]])
[[ 9 10 11]
[ 0 1 2]
[ 3 4 5]]
(3)选取方形区域的索引(借助np.ix_函数)
np.ix_函数就是输入两个数组,产生笛卡尔积的映射关系。例如:
x=np.arange(32).reshape((8,4))
print ("x = \n{}\n".format(x))
print (x[np.ix_([1,5,7,2],[0,3,1,2])])
x =
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]
[16 17 18 19]
[20 21 22 23]
[24 25 26 27]
[28 29 30 31]]
[[ 4 7 5 6]
[20 23 21 22]
[28 31 29 30]
[ 8 11 9 10]]
np.ix_函数将输入的数组[1,5,7,2]和数组[0,3,1,2]产生笛卡尔积,就是得到(1,0),(1,3),(1,1),(1,2);(5,0),(5,3),(5,1),(5,2);(7,0),(7,3),(7,1),(7,2);(2,0),(2,3),(2,1),(2,2)。然后将这些位置构成一个数组进行索引。
3、布尔索引
布尔索引,就是用一个由布尔类型值组成的数组来选择元素的方法。
看下面的例子:我要从数组x中选出大于5的元素
# x = [[0,1,2],[3,4,5],[6,7,8],[9,10,11]]
print ("x = \n{}\n".format(x))
y = x>5
print(y)
x =
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
[[False False False]
[False False False]
[ True True True]
[ True True True]]
像上面例子中所示,如果直接将选择条件打印出来得到的是一个值为 True 和 False 的布尔数组。而这个布尔数组可以作为一个索引。对应位置是 True 则输出,False 则跳过:
z = x[y]
print(z)
[ 6 7 8 9 10 11]
当然也可以直接print(x[x>5]),上面的写法只是为了突出布尔数组。
四、参考
- 盘一盘 Python 系列 2 - NumPy
- NumPy 教程
- MOOC课程Python数据分析与展示