不同
1.logistic regression适合需要得到一个分类概率的场景,SVM则没有分类概率
2.LR其实同样可以使用kernel,但是LR没有support vector在计算复杂度上会高出很多。如果样本量很大并且需要的是一个复杂模型,那么建议SVM
3. 如果样本比较少,模型又比较复杂。那么建议svm,它有一套比较好的解构风险最小化理论的保障,比如large margin和soft margin
相同
1. 由于hinge loss和entropy loss很接近,因此得出来的两个分类面是非常接近的
2. 都是在两个loss上做了一个regularization
作者:Jack
链接:https://www.zhihu.com/question/21704547/answer/74459964
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
LR 与SVM
在Andrew NG的课里讲到过:
1. 如果Feature的数量很大,跟样本数量差不多,这时候选用LR或者是Linear Kernel的SVM
2. 如果Feature的数量比较小,样本数量一般,不算大也不算小,选用SVM+Gaussian Kernel
3. 如果Feature的数量比较小,而样本数量很多,需要手工添加一些feature变成第一种情况
仔细想想,为什么是这样?
作者:雷军
链接:https://www.zhihu.com/question/21704547/answer/30682505
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
下面内容来源:http://www.cnblogs.com/suanec/p/4992887.html
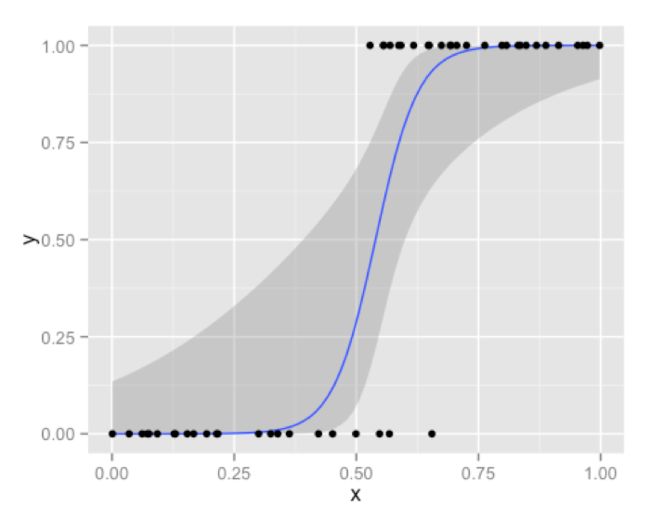
首先,我们来分析下逻辑回归(Logistic Regression),它是解决工业规模问题最流行的算法,尽管与其他技术相比,其在效率和算法实现的易用性方面并不出众。
逻辑回归非常便利并且很有用的一点就是,它输出的结果并不是一个离散值或者确切的类别。相反,你得到的是一个与每个观测样本相关的概率列表。你可以使用不同的标准和常用的性能指标来分析这个概率分数,并得到一个阈值,然后使用最符合你业务问题的方式进行分类输出。在金融行业,这种技术普遍应用于记分卡中,对于同一个模型,你可以调整你的阈值【临界值】来得到不同的分类结果。很少有其它算法使用这种分数作为直接结果。相反,它们的输出是严谨的直接分类结果。同时,逻辑回归在时间和内存需求上相当高效。它可以应用于分布式数据,并且还有在线算法实现,用较少的资源处理大型数据。
除此之外,逻辑回归算法对于数据中小噪声的鲁棒性很好,并且不会受到轻微的多重共线性的特别影响。严重的多重共线性则可以使用逻辑回归结合L2正则化来解决,不过如果要得到一个简约模型,L2正则化并不是最好的选择,因为它建立的模型涵盖了全部的特征。
当你的特征数目很大并且还丢失了大部分数据时,逻辑回归就会表现得力不从心。同时,太多的类别变量对逻辑回归来说也是一个问题。逻辑回归的另一个争议点是它使用整个数据来得到它的概率分数。虽然这并不是一个问题,但是当你尝试画一条分离曲线的时候,逻辑回归可能会认为那些位于分数两端“明显的”数据点不应该被关注。有些人可能认为,在理想情况下,逻辑回归应该依赖这些边界点。同时,如果某些特征是非线性的,那么你必须依靠转换,然而当你特征空间的维数增加时,这也会变成另一个难题。所以,对于逻辑回归,我们根据讨论的内容总结了一些突出的优点和缺点。
Logistic回归分析的优点:
1.适合需要得到一个分类概率的场景
2.实现效率较高
3.对逻辑回归而言,多重共线性并不是问题,它可以结合L2正则化来解决;
4.逻辑回归广泛的应用于工业问题上
逻辑回归的缺点:
1.当特征空间很大时,逻辑回归的性能不是很好;
2.不能很好地处理大量多类特征或变量;
4.对于非线性特征,需要进行转换;
5.依赖于全部的数据特征,当特征有缺失的时候表现效果不好
决策树
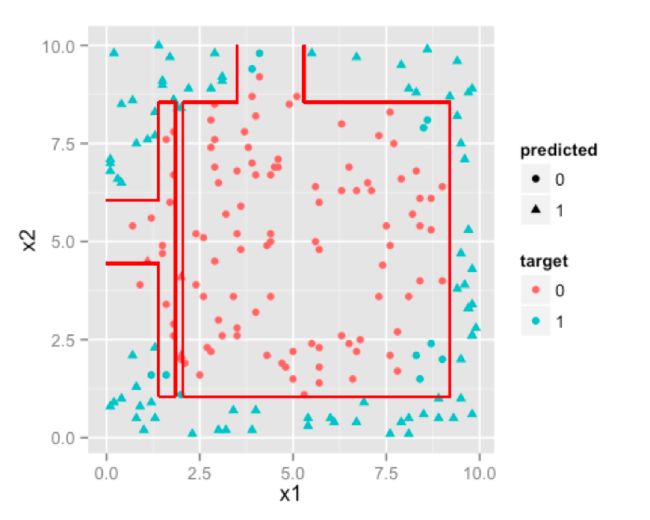
决策树固有的特性是它对单向变换或非线性特征并不关心[这不同于预测器当中的非线性相关性>,因为它们简单地在特征空间中插入矩形[或是(超)长方体],这些形状可以适应任何单调变换。当决策树被设计用来处理预测器的离散数据或是类别时,任何数量的分类变量对决策树来说都不是真正的问题。使用决策树训练得到的模型相当直观,在业务上也非常容易解释。决策树并不是以概率分数作为直接结果,但是你可以使用类概率反过来分配给终端节点。这也就让我们看到了与决策树相关的最大问题,即它们属于高度偏见型模型。你可以在训练集上构建决策树模型,而且其在训练集上的结果可能优于其它算法,但你的测试集最终会证明它是一个差的预测器。你必须对树进行剪枝,同时结合交叉验证才能得到一个没有过拟合的决策树模型。
随机森林在很大程度上克服了过拟合这一缺陷,其本身并没有什么特别之处,但它却是决策树一个非常优秀的扩展。随机森林同时也剥夺了商业规则的易解释性,因为现在你有上千棵这样的树,而且它们使用的多数投票规则会使得模型变得更加复杂。同时,决策树变量之间也存在相互作用,如果你的大多数变量之间没有相互作用关系或者非常弱,那么会使得结果非常低效。此外,这种设计也使得它们更不易受多重共线性的影响。
决策树总结如下:
决策树的优点:
1.直观的决策规则
2.可以处理非线性特征
3.考虑了变量之间的相互作用
决策树的缺点:
1.训练集上的效果高度优于测试集,即过拟合[随机森林克服了此缺点]
2.没有将排名分数作为直接结果
支持向量机
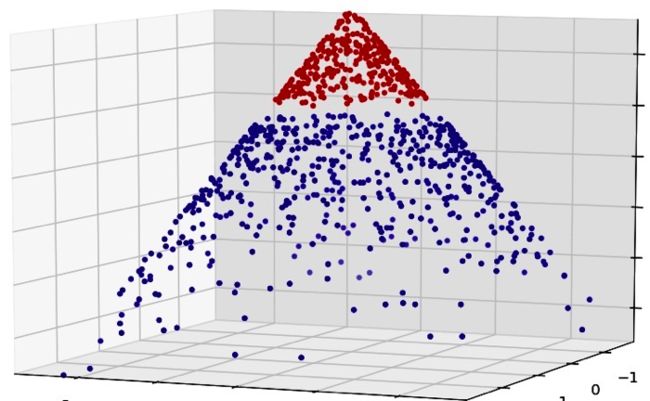
现在来讨论下支持向量机(SVM, Support Vector Machine)。支持向量机的特点是它依靠边界样本来建立需要的分离曲线。正如我们 之间看到的那样,它可以处理非线性决策边界。对边界的依赖,也使得它们有能力处理缺失数据中“明显的”样本实例。支持向量机能够处理大的特征空间,也因此成为文本分析中最受欢迎的算法之一,由于文本数据几乎总是产生大量的特征,所以在这种情况下逻辑回归并不是一个非常好的选择。
对于一个行外人来说,SVM的结果并不像决策树那样直观。同时使用非线性核,使得支持向量机在大型数据上的训练非常耗时。总之:
SVM的优点:
1.能够处理大型特征空间
2.能够处理非线性特征之间的相互作用
3.无需依赖整个数据
SVM的缺点:
1.当观测样本很多时,效率并不是很高
2.有时候很难找到一个合适的核函数
为此,我试着编写一个简单的工作流,决定应该何时选择这三种算法,流程如下:
首当其冲应该选择的就是逻辑回归,如果它的效果不怎么样,那么可以将它的结果作为基准来参考;
然后试试决策树(随机森林)是否可以大幅度提升模型性能。即使你并没有把它当做最终模型,你也可以使用随机森林来移除噪声变量;
如果特征的数量和观测样本特别多,那么当资源和时间充足时,使用SVM不失为一种选择。
最后,大家请记住,在任何时候好的数据总要胜过任何一个算法。时常思考下,看看是否可以使用你的领域知识来设计一个好的特征。在使用创建的特征做实验时,可以尝试下各种不同的想法。此外,你还可以尝试下多种模型的组合。这些我们将在下回讨论,所以,整装待发吧!
作者:在山的那边_
链接:http://www.jianshu.com/p/95e5faa3f709
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。