Pytorch打卡第8天:18种损失函数
任务:学习18种损失函数
损失函数概念
损失函数:衡量模型输出与真实标签的差异。
损失函数(Loss Function)
代价函数(Cost Function)
目标函数(Objective Function)

nn.CrossEntropyLoss
- 功能: nn.LogSoftmax()与nn.NLLLoss()结合,进行交叉熵计算
- 主要参数:
• weight:各类别的loss设置权值
• ignore_index:忽略某个类别
• reduction :计算模式,可为none/sum/mean
none- 逐个元素计算
sum- 所有元素求和,返回标量
mean- 加权平均,返回标量
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
# fake data
inputs = torch.tensor([[1, 2], [1, 3], [1, 3]], dtype=torch.float)
target = torch.tensor([0, 1, 1], dtype=torch.long)
weights = torch.tensor([1, 2], dtype=torch.float)
# CrossEntropy loss: reduction
loss_f_none = nn.CrossEntropyLoss(weight=None, reduction='none')
loss_f_sum = nn.CrossEntropyLoss(weight=None, reduction='sum')
loss_f_mean = nn.CrossEntropyLoss(weight=weights, reduction='mean')
loss_none = loss_f_none(inputs, target)
loss_sum = loss_f_sum(inputs, target)
loss_mean = loss_f_mean(inputs, target)
print(weights)
print(loss_none, loss_sum, loss_mean)
输出:
tensor([1., 2.])
tensor([1.3133, 0.1269, 0.1269]) tensor(1.5671) tensor(0.3642)
nn.NLLLoss
- 功能:实现负对数似然函数中的负号功能
- 主要参数:
• weight:各类别的loss设置权值
• ignore_index:忽略某个类别
• reduction :计算模式,可为none/sum/mean
none-逐个元素计算
sum-所有元素求和,返回标量
mean-加权平均,返回标量
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
# fake data
inputs = torch.tensor([[1, 2], [1, 3], [1, 3]], dtype=torch.float)
target = torch.tensor([0, 1, 1], dtype=torch.long)
weights = torch.tensor([1, 1], dtype=torch.float)
# 2 NLLLoss
loss_f_none = nn.NLLLoss(weight=weights, reduction='none')
loss_f_sum = nn.NLLLoss(weight=weights, reduction='sum')
loss_f_mean = nn.NLLLoss(weight=weights, reduction='mean')
loss_none = loss_f_none(inputs, target)
loss_sum = loss_f_sum(inputs, target)
loss_mean = loss_f_mean(inputs, target)
print(weights)
print(loss_none, loss_sum, loss_mean)
输出:
tensor([1., 1.])
tensor([-1., -3., -3.]) tensor(-7.) tensor(-2.3333)
nn.BCELoss
- 功能:二分类交叉熵
- 注意事项:输入值取值在[0,1]
- 主要参数:
• weight:各类别的loss设置权值
• ignore_index:忽略某个类别
• reduction :计算模式,可为none/sum/mean
none-逐个元素计算
sum-所有元素求和,返回标量
mean-加权平均,返回标量
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
# fake data
inputs = torch.tensor([[1, 2], [2, 2], [3, 4], [4, 5]], dtype=torch.float)
target = torch.tensor([[1, 0], [1, 0], [0, 1], [0, 1]], dtype=torch.float)
target_bce = target
# itarget
inputs = torch.sigmoid(inputs)
weights = torch.tensor([1, 1], dtype=torch.float)
# 3 BCE Loss
loss_f_none = nn.BCELoss(weight=weights, reduction='none')
loss_f_sum = nn.BCELoss(weight=weights, reduction='sum')
loss_f_mean = nn.BCELoss(weight=weights, reduction='mean')
loss_none = loss_f_none(inputs, target)
loss_sum = loss_f_sum(inputs, target)
loss_mean = loss_f_mean(inputs, target)
print(weights)
print(loss_none, loss_sum, loss_mean)
输出:
tensor([1., 1.])
tensor([[0.3133, 2.1269],
[0.1269, 2.1269],
[3.0486, 0.0181],
[4.0181, 0.0067]]) tensor(11.7856) tensor(1.4732)
nn.BCEWithLogitsLoss
- 功能:结合Sigmoid与二分类交叉熵
- 注意事项:网络最后不加sigmoid函数
- 主要参数:
• pos_weight :正样本的权值
• weight:各类别的loss设置权值
• ignore_index:忽略某个类别
• reduction :计算模式,可为none/sum/mean
none-逐个元素计算
sum-所有元素求和,返回标量
mean-加权平均,返回标量
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
# fake data
inputs = torch.tensor([[1, 2], [2, 2], [3, 4], [4, 5]], dtype=torch.float)
target = torch.tensor([[1, 0], [1, 0], [0, 1], [0, 1]], dtype=torch.float)
target_bce = target
# itarget
# inputs = torch.sigmoid(inputs)
weights = torch.tensor([1, 1], dtype=torch.float)
# 4 BCE with Logis Loss
loss_f_none = nn.BCEWithLogitsLoss(weight=weights, reduction='none')
loss_f_sum = nn.BCEWithLogitsLoss(weight=weights, reduction='sum')
loss_f_mean = nn.BCEWithLogitsLoss(weight=weights, reduction='mean')
loss_none = loss_f_none(inputs, target)
loss_sum = loss_f_sum(inputs, target)
loss_mean = loss_f_mean(inputs, target)
print(weights)
print(loss_none, loss_sum, loss_mean)
输出:
tensor([1., 1.])
tensor([[0.3133, 2.1269],
[0.1269, 2.1269],
[3.0486, 0.0181],
[4.0181, 0.0067]]) tensor(11.7856) tensor(1.4732)
nn.L1Loss
- 功能: 计算inputs与target之差的绝对值
import torch
import torch.nn as nn
# fake data
inputs = torch.ones((2, 2))
target = torch.ones((2, 2)) * 3
# 5 L1 loss
loss_f = nn.L1Loss(reduction='none')
loss = loss_f(inputs, target)
print(inputs, target, loss)
输出:
tensor([[1., 1.],
[1., 1.]]) tensor([[3., 3.],
[3., 3.]]) tensor([[2., 2.],
[2., 2.]])
nn.MSELoss
- 功能: 计算inputs与target之差的平方
- 主要参数:
• reduction :计算模式,可为none/sum/mean
none- 逐个元素计算
sum- 所有元素求和,返回标量
mean- 加权平均,返回标量
import torch
import torch.nn as nn
# fake data
inputs = torch.ones((2, 2))
target = torch.ones((2, 2)) * 3
# 6 MSE loss
loss_f = nn.MSELoss(reduction='none')
loss = loss_f(inputs, target)
print(inputs, target, loss)
SmoothL1Loss
- 功能: 平滑的L1Loss
- 主要参数:
• reduction :计算模式,可为none/sum/mean
import torch
import torch.nn as nn
# fake data
inputs = torch.linspace(-3, 3, steps=500)
target = torch.zeros_like(inputs)
# 7 Smooth L1 loss
loss_f = nn.SmoothL1Loss(reduction='none')
loss = loss_f(inputs, target)
print(inputs, target, loss)
PoissonNLLLoss
- 功能:泊松分布的负对数似然损失函数
- 主要参数:
• log_input :输入是否为对数形式,决定计算公式
• full :计算所有loss,默认为False
• eps :修正项,避免log(input)为nan
import torch
import torch.nn as nn
# fake data
inputs = torch.randn((2, 2))
target = torch.randn((2, 2))
# 8 Poisson NLL Loss
loss_f = nn.PoissonNLLLoss(log_input=True, full=False, reduction='none')
loss = loss_f(inputs, target)
print(inputs, target, loss)
输出:
tensor([[ 0.9628, -0.2802],
[-1.3465, 0.5515]]) tensor([[ 0.8187, -1.1934],
[-0.6767, 0.5964]]) tensor([[ 1.8308, 0.4213],
[-0.6510, 1.4069]])
nn.KLDivLoss
- 功能:计算KLD(divergence),KL散度,相对熵
- 注意事项:需提前将输入计算 log-probabilities, 如通过nn.logsoftmax()
- 主要参数:
• reduction :none/sum/mean/batchmean
batchmean- batchsize维度求平均值
none- 逐个元素计算
sum- 所有元素求和,返回标量 mean- 加权平均,返回标量
import torch
import torch.nn as nn
# fake data
inputs = torch.tensor([[0.5, 0.3, 0.2], [0.2, 0.3, 0.5]])
inputs_log = torch.log(inputs)
target = torch.tensor([[0.9, 0.05, 0.05], [0.1, 0.7, 0.2]], dtype=torch.float)
# 9 KL Divergence Loss
loss_f_none = nn.KLDivLoss(reduction='none')
loss_f_mean = nn.KLDivLoss(reduction='mean')
loss_f_bs_mean = nn.KLDivLoss(reduction='batchmean')
loss_none = loss_f_none(inputs, target)
loss_mean = loss_f_mean(inputs, target)
loss_bs_mean = loss_f_bs_mean(inputs, target)
print("loss_none:\n{}\nloss_mean:\n{}\nloss_bs_mean:\n{}".format(loss_none, loss_mean, loss_bs_mean))
nn.MarginRankingLoss
- 功能:计算两个向量之间的相似度,用于排序任务
- 特别说明:该方法计算两组数据之间的差异,返回一个n*n 的 loss 矩阵
- 主要参数:
• margin :边界值,x1与x2之间的差异值
• reduction :计算模式,可为none/sum/mean
y = 1时, 希望x1比x2大,当x1>x2时,不产生loss
y = -1时,希望x2比x1大,当x2>x1时,不产生loss
import torch
import torch.nn as nn
# fake data
x1 = torch.tensor([[1], [2], [3]], dtype=torch.float)
x2 = torch.tensor([[2], [2], [2]], dtype=torch.float)
target = torch.tensor([1, 1, -1], dtype=torch.float)
# 10 Margin Ranking Loss
loss_f_none = nn.MarginRankingLoss(margin=0, reduction='none')
loss = loss_f_none(x1, x2, target)
print(loss)
输出:
tensor([[1., 1., 0.],
[0., 0., 0.],
[0., 0., 1.]])
nn.MultiLabelMarginLoss
- 功能:多标签边界损失函数
- 举例:四分类任务,样本x属于0类和3类, 标签:[0, 3, -1, -1] , 不是[1, 0, 0, 1]
- 主要参数:
• reduction :计算模式,可为none
import torch
import torch.nn as nn
# fake data
x = torch.tensor([[0.1, 0.2, 0.4, 0.8]])
y = torch.tensor([[0, 3, -1, -1]], dtype=torch.long)
# 11 Multi Label Margin Loss
loss_f = nn.MultiLabelMarginLoss(reduction='none')
loss = loss_f(x, y)
print(loss)
输出:tensor([0.8500])
nn.SoftMarginLoss
- 功能:计算二分类的logistic损失
- 主要参数:
• reduction :计算模式,可为none/sum/mean
import torch
import torch.nn as nn
# fake data
inputs = torch.tensor([[0.3, 0.7], [0.5, 0.5]])
target = torch.tensor([[-1, 1], [1, -1]], dtype=torch.float)
# 12 SoftMargin Loss
loss_f = nn.SoftMarginLoss(reduction='none')
loss = loss_f(inputs, target)
print("SoftMargin: ", loss)
输出:
SoftMargin: tensor([[0.8544, 0.4032],[0.4741, 0.9741]])
nn.MultiLabelSoftMarginLoss
- 功能:SoftMarginLoss多标签版本
- 主要参数:
• weight:各类别的loss设置权值
• reduction :计算模式,可为none/sum/mean
import torch
import torch.nn as nn
# fake data
inputs = torch.tensor([[0.3, 0.7, 0.8]])
target = torch.tensor([[0, 1, 1]], dtype=torch.float)
# 13 MultiLabel SoftMargin Loss
loss_f = nn.MultiLabelSoftMarginLoss(reduction='none')
loss = loss_f(inputs, target)
print("SoftMargin: ", loss)
输出:SoftMargin: tensor([0.5429])
nn.MultiMarginLoss
- 功能:计算多分类的折页损失
- 主要参数:
• p :可选1或2
• weight:各类别的loss设置权值
• margin :边界值
• reduction :计算模式,可为none/sum/mean
import torch
import torch.nn as nn
# fake data
x = torch.tensor([[0.1, 0.2, 0.7], [0.2, 0.5, 0.3]])
y = torch.tensor([1, 2], dtype=torch.long)
# 14 Multi Margin Loss
loss_f = nn.MultiMarginLoss(reduction='none')
loss = loss_f(x, y)
print("SoftMargin: ", loss)
输出:SoftMargin: tensor([0.8000, 0.7000])
nn.TripletMarginLoss
- 功能:计算三元组损失,人脸验证中常用
- 主要参数:
• p :范数的阶,默认为2
• margin :边界值
• reduction :计算模式,可为none/sum/mean
import torch
import torch.nn as nn
# fake data
anchor = torch.tensor([[1.]])
pos = torch.tensor([[2.]])
neg = torch.tensor([[0.5]])
# 15 Triplet Margin Loss
loss_f = nn.TripletMarginLoss(margin=1.0, p=1)
loss = loss_f(anchor, pos, neg)
print("SoftMargin: ", loss)
输出:SoftMargin: tensor(1.5000)
nn.HingeEmbeddingLoss
- 功能:计算两个输入的相似性,常用于非线性embedding和半监督学习
- 特别注意:输入x应为两个输入之差的绝对值
- 主要参数:
• margin :边界值
• reduction :计算模式,可为none/sum/mean
import torch
import torch.nn as nn
# 16 Hinge Embedding Loss
flag = 0
# flag = 1
if flag:
inputs = torch.tensor([[1., 0.8, 0.5]])
target = torch.tensor([[1, 1, -1]])
loss_f = nn.HingeEmbeddingLoss(margin=1, reduction='none')
loss = loss_f(inputs, target)
print("Hinge Embedding Loss", loss)
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
margin = 1.
loss = max(0, margin - inputs.numpy()[0, 2])
print(loss)
nn.CosineEmbeddingLoss
- 功能:采用余弦相似度计算两个输入的相似性
- 主要参数:
• margin :可取值[-1, 1] , 推荐为[0, 0.5]
• reduction :计算模式,可为none/sum/mean
import torch
import torch.nn as nn
# 17 Cosine Embedding Loss
flag = 0
# flag = 1
if flag:
x1 = torch.tensor([[0.3, 0.5, 0.7], [0.3, 0.5, 0.7]])
x2 = torch.tensor([[0.1, 0.3, 0.5], [0.1, 0.3, 0.5]])
target = torch.tensor([[1, -1]], dtype=torch.float)
loss_f = nn.CosineEmbeddingLoss(margin=0., reduction='none')
loss = loss_f(x1, x2, target)
print("Cosine Embedding Loss", loss)
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
margin = 0.
def cosine(a, b):
numerator = torch.dot(a, b)
denominator = torch.norm(a, 2) * torch.norm(b, 2)
return float(numerator/denominator)
l_1 = 1 - (cosine(x1[0], x2[0]))
l_2 = max(0, cosine(x1[0], x2[0]))
print(l_1, l_2)
nn.CTCLoss
- 功能: 计算CTC损失,解决时序类数据的分类Connectionist Temporal Classification
- 主要参数:
• blank :blank label
• zero_infinity :无穷大的值或梯度置0
• reduction :计算模式,可为none/sum/mean
# 18 CTC loss
flag = 1
if flag:
T = 50 # Input sequence length
C = 20 # Number of classes (including blank)
N = 16 # Batch size
S = 30 # Target sequence length of longest target in batch
S_min = 10 # Minimum target length, for demonstration purposes
# Initialize random batch of input vectors, for *size = (T,N,C)
inputs = torch.randn(T, N, C).log_softmax(2).detach().requires_grad_()
# Initialize random batch of targets (0 = blank, 1:C = classes)
target = torch.randint(low=1, high=C, size=(N, S), dtype=torch.long)
input_lengths = torch.full(size=(N,), fill_value=T, dtype=torch.long)
target_lengths = torch.randint(low=S_min, high=S, size=(N,), dtype=torch.long)
ctc_loss = nn.CTCLoss()
loss = ctc_loss(inputs, target, input_lengths, target_lengths)
print("CTC loss: ", loss)
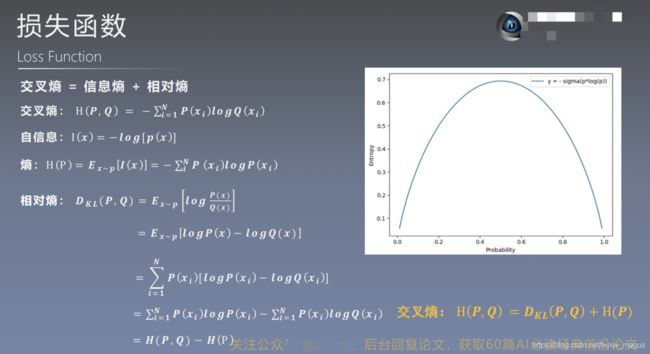
熵的概念
熵:描述一个事情的不确定性。
熵的值越大,表示这个事情发生的概率越小。
0.69: 第一个literation,或者是模型训练坏掉的时候,loss经常是0.69。
代码
# -*- coding: utf-8 -*-
import os
import random
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torch.optim as optim
from PIL import Image
from matplotlib import pyplot as plt
from model.lenet import LeNet
from tools.my_dataset import RMBDataset
from tools.common_tools import transform_invert, set_seed
set_seed(1) # 设置随机种子
rmb_label = {"1": 0, "100": 1}
# 参数设置
MAX_EPOCH = 10
BATCH_SIZE = 16
LR = 0.01
log_interval = 10
val_interval = 1
# ============================ step 1/5 数据 ============================
split_dir = os.path.join("..", "..", "data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomCrop(32, padding=4),
transforms.RandomGrayscale(p=0.8),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
# ============================ step 2/5 模型 ============================
net = LeNet(classes=2)
net.initialize_weights()
# ============================ step 3/5 损失函数 ============================
loss_functoin = nn.CrossEntropyLoss() # 选择损失函数
# ============================ step 4/5 优化器 ============================
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1) # 设置学习率下降策略
# ============================ step 5/5 训练 ============================
train_curve = list()
valid_curve = list()
for epoch in range(MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
net.train()
for i, data in enumerate(train_loader):
# forward
inputs, labels = data
outputs = net(inputs)
# backward
optimizer.zero_grad()
loss = loss_functoin(outputs, labels)
loss.backward()
# update weights
optimizer.step()
# 统计分类情况
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().sum().numpy()
# 打印训练信息
loss_mean += loss.item()
train_curve.append(loss.item())
if (i+1) % log_interval == 0:
loss_mean = loss_mean / log_interval
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))
loss_mean = 0.
scheduler.step() # 更新学习率
# validate the model
if (epoch+1) % val_interval == 0:
correct_val = 0.
total_val = 0.
loss_val = 0.
net.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
inputs, labels = data
outputs = net(inputs)
loss = loss_functoin(outputs, labels)
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).squeeze().sum().numpy()
loss_val += loss.item()
valid_curve.append(loss_val)
print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, j+1, len(valid_loader), loss_val, correct / total))
train_x = range(len(train_curve))
train_y = train_curve
train_iters = len(train_loader)
valid_x = np.arange(1, len(valid_curve)+1) * train_iters*val_interval # 由于valid中记录的是epochloss,需要对记录点进行转换到iterations
valid_y = valid_curve
plt.plot(train_x, train_y, label='Train')
plt.plot(valid_x, valid_y, label='Valid')
plt.legend(loc='upper right')
plt.ylabel('loss value')
plt.xlabel('Iteration')
plt.show()
# ============================ inference ============================
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
test_dir = os.path.join(BASE_DIR, "test_data")
test_data = RMBDataset(data_dir=test_dir, transform=valid_transform)
valid_loader = DataLoader(dataset=test_data, batch_size=1)
for i, data in enumerate(valid_loader):
# forward
inputs, labels = data
outputs = net(inputs)
_, predicted = torch.max(outputs.data, 1)
rmb = 1 if predicted.numpy()[0] == 0 else 100
img_tensor = inputs[0, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.title("LeNet got {} Yuan".format(rmb))
plt.show()
plt.pause(0.5)
plt.close()