pytorch实战-基于LeNet5网络结构
此博文用到的CIFAR10数据集,可从官网下载:官网入口
但是官网下载实在是太慢啦,这里贴一个百度云链接哈哈十分钟的事情嘛,百度云:链接入口
此博文用到的卷积网络结构为LeNet5,比较久远,但是为了pytorch练手嘛可以试试,加深理解。
LeNet 5卷积神经网络结构如下图:
图1 LeNet 5卷积神经网络结构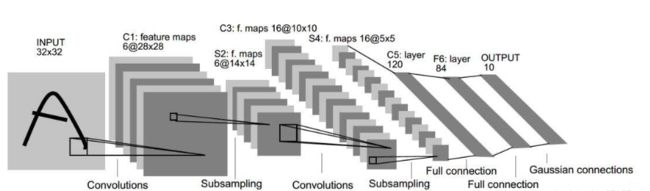
一、主要库包理解与解释
torchvision详细介绍:参考博文入口
(1) Torchvision
torchvision是独立于pytorch的关于图像操作的一些方便工具库.
- vision.datasets :
几个常用视觉数据集(MINIST,CIFAR),可以下载和加载,这里主要的高级用法就是可以看源码如何自己写自己的Dataset的子类 - vision.models : 流行的模型,例如 AlexNet, VGG, ResNet 和 Densenet 以及 与训练好的参数。
- vision.transforms : 常用的图像操作,例如:随机切割,旋转,数据类型转换,图像到tensor ,numpy
数组到tensor , tensor 到 图像等。 - vision.utils : 用于把形似 (3 x H x W) 的张量保存到硬盘中,给一个mini-batch的图像可以产生一个图像格网
MINIST数据
dset.MNIST(root, train=True, transform=None, target_transform=None, download=False)
- root:数据的目录,里边有 processed/training.pt 和processed/test.pt 的内容
- train: True -使用训练集, False -使用测试集.
- transform: 给输入图像施加变换
- target_transform:给目标值(类别标签)施加的变换
- download: 是否下载mnist数据集,下载到root中指定的目录
CIFAR数据集
cifar10表示10个图片分类种类;cifar100将图片更加细分为100个分类情况
如下图所示:

dset.CIFAR10(root, train=True, transform=None, target_transform=None, download=False)
dset.CIFAR100(root, train=True, transform=None, target_transform=None, download=False)
- root : 数据的目录,存放 cifar-10-batches-py数据集
- train :True -使用训练集, False -使用测试集.
- download : 是否下载mnist数据集,下载到root中指定的目录
(2)DataLoader
从DataLoader类的属性定义中可以看出,这个类的作用就是实现数据以什么方式输入到什么网络中
下面具体研究一下:
先看看 dataloader.py脚本是怎么写的(VS中按F12跳转到该脚本)
init(构造函数)中的几个重要的属性:
-
dataset:(数据类型 dataset)
输入的数据类型。看名字感觉就像是数据库,C#里面也有dataset类,理论上应该还有下一级的datatable。这应当是原始数据的输入。PyTorch内也有这种数据结构。这里先不管,估计和C#的类似,这里只需要知道是输入数据类型是dataset就可以了。
-
batch_size:(数据类型 int)
每次输入数据的行数,默认为1。PyTorch训练模型时调用数据不是一行一行进行的(这样太没效率),而是一捆一捆来的。这里就是定义每次喂给神经网络多少行数据,如果设置成1,那就是一行一行进行。
-
shuffle:(数据类型 bool)
洗牌。默认设置为False。在每次迭代训练时是否将数据洗牌,默认设置是False。将输入数据的顺序打乱,是为了使数据更有独立性,但如果数据是有序列特征的,就不要设置成True了。
-
collate_fn:(数据类型 callable,没见过的类型)
将一小段数据合并成数据列表,默认设置是False。如果设置成True,系统会在返回前会将张量数据(Tensors)复制到CUDA内存中。(不太明白作用是什么,就暂时默认False)
-
batch_sampler:(数据类型 Sampler)
批量采样,默认设置为None。但每次返回的是一批数据的索引(注意:不是数据)。其和batch_size、shuffle 、sampler
and
drop_last参数是不兼容的。我想,应该是每次输入网络的数据是随机采样模式,这样能使数据更具有独立性质。所以,它和一捆一捆按顺序输入,数据洗牌,数据采样,等模式是不兼容的。 -
sampler:(数据类型 Sampler)
采样,默认设置为None。根据定义的策略从数据集中采样输入。如果定义采样规则,则洗牌(shuffle)设置必须为False。
-
num_workers:(数据类型 Int)
工作者数量,默认是0。使用多少个子进程来导入数据。设置为0,就是使用主进程来导入数据。注意:这个数字必须是大于等于0的,负数估计会出错。
-
pin_memory:(数据类型 bool)
内存寄存,默认为False。在数据返回前,是否将数据复制到CUDA内存中。
-
drop_last:(数据类型 bool)
丢弃最后数据,默认为False。设置了 batch_size
的数目后,最后一批数据未必是设置的数目,有可能会小些。这时你是否需要丢弃这批数据。 -
timeout:(数据类型 numeric)
超时,默认为0。是用来设置数据读取的超时时间的,但超过这个时间还没读取到数据的话就会报错。 所以,数值必须大于等于0。
-
worker_init_fn(数据类型 callable,没见过的类型)
子进程导入模式,默认为Noun。在数据导入前和步长结束后,根据工作子进程的ID逐个按顺序导入数据。
利用CIFAR 10数据集举例代码如下:
batchsz = 128
cifar_train = datasets.CIFAR10('cifar', True, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True)
cifar_train = DataLoader(cifar_train, batch_size=batchsz, shuffle=True)
cifar_test = datasets.CIFAR10('cifar', False, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True)
cifar_test = DataLoader(cifar_test, batch_size=batchsz, shuffle=True)
二、完整代码
准备工作
首先创建红色边框里的对应文件
(1) Lenet5.py
主要定义网络结构
网络结构直观图见图1,对应代码如下
import torch
from torch import nn
from torch.nn import functional as F
class Lenet5(nn.Module):
# 针对手写体最先提出的网络结构Lenet5
"""
for cifar10 dataset.
"""
# 定义具体的网络结构
def __init__(self):
super(Lenet5, self).__init__()
self.conv_unit = nn.Sequential(
# x: [b, 3, 32, 32] => [b, 16, ]
# 通道数=3,深度=16,卷积核:5*5,步长=1
nn.Conv2d(3, 16, kernel_size=5, stride=1, padding=0),
# 卷积核:2*2,步长=2
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
# 基于上面深度为16,通道数则变为16,卷积核5*5=>[b,32,]
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=0),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
#
)
# flatten
# 全连接操作 fc unit
self.fc_unit = nn.Sequential(
# nn.Linear()函数其实就是在做一个y=wx+b的线性操作
# x:[32*5*5] b:[32]
nn.Linear(32*5*5, 32),
nn.ReLU(),
# nn.Linear(120, 84),
# nn.ReLU(),
nn.Linear(32, 10)
)
# 简单测试一下
# [b, 3, 32, 32]
tmp = torch.randn(2, 3, 32, 32)
out = self.conv_unit(tmp)
# [b, 16, 5, 5]
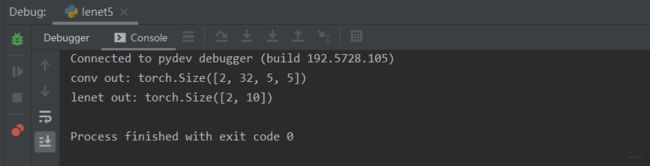
print('conv out:', out.shape)
# # use Cross Entropy Loss
# self.criteon = nn.CrossEntropyLoss()
# 具体网络实现流程
def forward(self, x):
"""
:param x: [b, 3, 32, 32]
:return:
"""
batchsz = x.size(0)
# [b, 3, 32, 32] => [b, 16, 5, 5]
x = self.conv_unit(x)
# [b, 16, 5, 5] => [b, 16*5*5]
x = x.view(batchsz, 32*5*5)
# [b, 16*5*5] => [b, 10]
# logits一般用来表示未经过softmax()操作
logits = self.fc_unit(x)
# # [b, 10]
# pred = F.softmax(logits, dim=1)
# loss = self.criteon(logits, y)
return logits
# 简单测试
def main():
# 初始化对象,执行__init__()
net = Lenet5()
tmp = torch.randn(2, 3, 32, 32)
# 实例化则自动调用forward()函数
out = net(tmp)
print('lenet out:', out.shape)
if __name__ == '__main__':
main()
Lenet5.py测试结果见下图:
(2) main.py
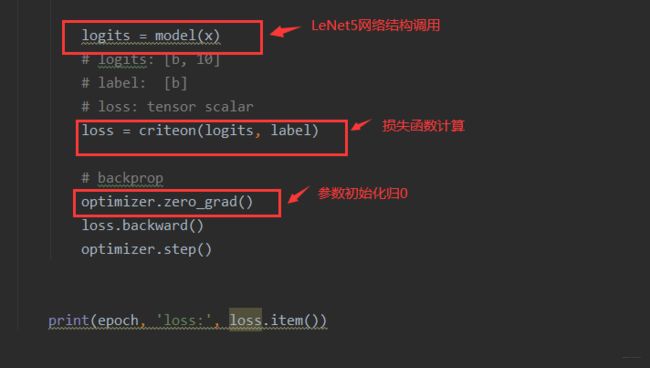
主要完成数据导入,网络结构调用,loss计算等
import torch
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
from torch import nn, optim
from lenet5 import Lenet5
from resnet import ResNet18
def main():
batchsz = 128
# 一次加载数据的量
cifar_train = datasets.CIFAR10('cifar', True, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True)
cifar_train = DataLoader(cifar_train, batch_size=batchsz, shuffle=True)
cifar_test = datasets.CIFAR10('cifar', False, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True)
cifar_test = DataLoader(cifar_test, batch_size=batchsz, shuffle=True)
#x, label = iter(cifar_train).next()
#print('x:', x.shape, 'label:', label.shape)
device = torch.device('cuda')
# 将定义的LeNet5网络结构部署到GPU上
model = Lenet5().to(device)
# model = ResNet18().to(device)
# criteon 评价标准
# CrossEntropyLoss进行交叉熵运算(包括了softmax计算),判断多分类问题中预测试与真实值的差距
criteon = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
print(model)
# 训练过程
for epoch in range(1000):
model.train()
for batchidx, (x, label) in enumerate(cifar_train):
# [b, 3, 32, 32]
# [b]
x, label = x.to(device), label.to(device)
logits = model(x)
# logits: [b, 10]
# label: [b]
# loss: tensor scalar
loss = criteon(logits, label)
# backprop
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(epoch, 'loss:', loss.item())
# 测试过程
model.eval()
# 测试不需要梯度变化,以防安全
with torch.no_grad():
# test
total_correct = 0
total_num = 0
for x, label in cifar_test:
# [b, 3, 32, 32]
# [b]
x, label = x.to(device), label.to(device)
# [b, 10]
logits = model(x)
# [b]
pred = logits.argmax(dim=1)
# [b] vs [b] => scalar tensor
correct = torch.eq(pred, label).float().sum().item()
total_correct += correct
total_num += x.size(0)
# print(correct)
acc = total_correct / total_num
print(epoch, 'test acc:', acc)
if __name__ == '__main__':
main()
运行结果截图
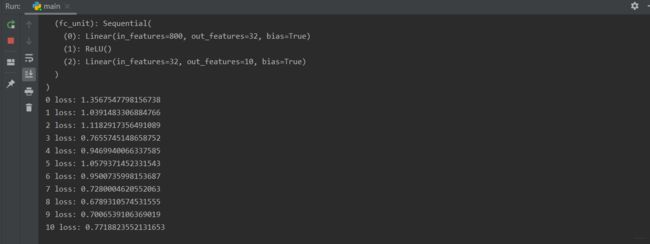
1.打印出的model结构

2.运行epoch次后loss的变化结果(电脑太垃圾,这里没有跑eval测试过程结果),跑了不知道好几十分钟,这只是部分结果哈,他要跑1000次顶不住了先溜。
整个代码主要框架如下