关于等待事件cursor:mutex X的一次案例分析
数据库环境:oracle12.1.0.2.170718,两节点RAC+单实例ADG
日常巡检时候发现,晚上11点系统跑批的时候,会出现系统负载过高情况,明显有异于平时。但并不是每天晚上跑批都会出现该问题,一开始怀疑是跑批内容存在差异导致,后跟开发人员再三确认,跑批程序一致,数据也不相上下。
正常时,跑批期间DB Time:

异常时,跑批期间DB Time:

看看等待事件情况:
正常时的等待事件情况:

异常时的等待事件情况:
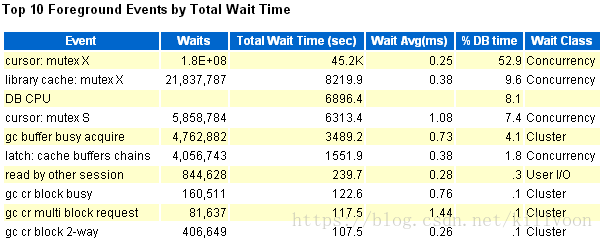
这个问题观察了有半个月的时间,发现问题的出现不存在规律性,更像是偶然事件,但偶发性概率较高,平均三四天就可能出现一次,有时候会连续出现两三天。
根据等待事件来看,主要是cursor:mutex X和library cache:mutex X,其中cursor:mutex X尤为突出。
关于cursor:mutex X的介绍:
某个进程申请以EXCL mode持有mutex时进入该等待, 该Mutex要么正被其他进程以SHRD模式参考,这导致X mode的申请必须要等待直到Ref count=0, 或者该mutex正被另一个进程以X mode持有。
触发该事件的情况有:
a、在一个父游标下面创建一个新的子游标
b、捕获SQL中的绑定变量
c、更新或构建SQL统计信息V$SQLSTAT
-----------------------------------------------------------------------
看下出问题时的TOP SQL:
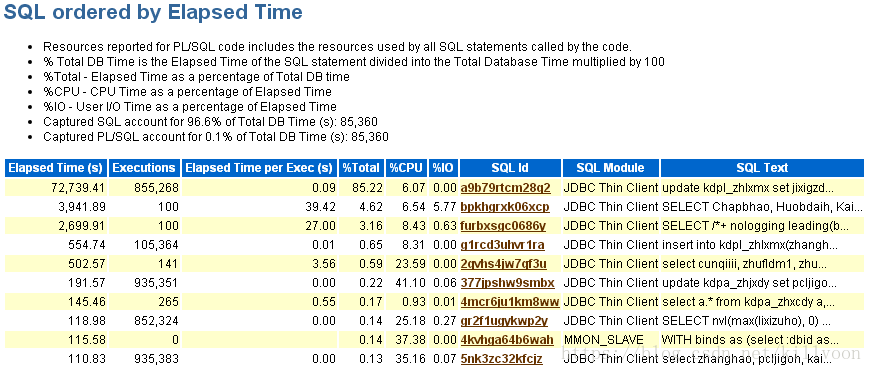
主要是a9b79rtcm28q2这条语句,观察了出现问题的几次,全是该语句,这条语句是一条很简单的update语句:
update kdpl_zhlxmx
set jixigzdm = :1,
lixizusl = :2,
lixiczdm = :3,
jixiqsrq = :4,
jixizzrq = :5,
jzjtllbh = :6,
lilvdanc = :7,
cencllbh = :8,
cencllcq = :9,
lilvkdfs = :10,
zhjiznll = :11,
zhxililv = :12,
llsxriqi = :13,
jitishul = :14,
sjlxfsje = :15,
lixsfsje = :16,
jzlxfsje = :17,
tzhhlixi = :18,
tzhhlixs = :19,
fencllbz = :20,
dngcjxye = :21,
dngcjxcq = :22,
zongjxye = :23,
jishuuuu = :24,
bzjixiff = :25,
mnxisybz = :26,
tzshynbz = :27,
lixitzff = :28,
scjexirq = :29,
zhaiyodm = :30,
zhaiyoms = :31,
nbjoyima = :32,
wbjoyima = :33,
jiaoyirq = :34,
jiaoyisj = :35,
jiaoyijg = :36,
guiylius = :37,
lilvfdbz = :38,
lilvfdlx = :39,
lilvfdsz = :40,
youhuibz = :41,
youhuilx = :42,
youhuisz = :43,
lilvfdbl = :44,
youhuill = :45,
fenhbios = :46,
weihguiy = :47,
weihjigo = :48,
weihriqi = :49,
weihshij = :50,
shijchuo = :51,
jiluztai = :52
where zhanghao = :53
and xuhaoooo = :54
and lixizuho = :55
and lixileix = :56
and farendma = :57
唯一可以发力的地方就是:似乎绑定变量有点多。尤记得之前在MOS上看到过类似的文章,讲的便是绑定变量过多触发某些bug。由于没记录相关DOC ID,专门去找又找不到了。
咦,绑定变量过多,而产生等待时间cursor:mutex X的一种原因是获取SQL绑定变量,莫非这其中存在联系。按照绑定变量这个思路去寻找突破口,通过查找dba_hist_sqlbind和v$sql_bind_capture来查看该语句具体的绑定变量值时发现,竟然没有where条件之前的绑定变量信息,value_string这一项竟然是空值。
于是怀疑,由于程序未对where条件之前的绑定变量传值,导致oracle在捕获绑定变量时候,频繁获取到空值,继而触发大量cursor:mutex X,导致系统负载过高。
事情看起来有些明了了,需要的就是oracle官方相关文章来佐证我的推测。当然,当务之急还是找来开发,询问开发人员,为何不对where条件之前52个绑定变量传值,既然是空值,就没必要再用绑定变量的形式,直接写成null岂不是更完美。
然而,开发人员一脸懵逼的看着我:不应该啊,我们肯定都是传值的,不会出现空值的情况。我顺手查了表中的数据,发现确实不存在空值的情况,又跟开发人员确认再三,得到肯定做了传值的保证。我只好让开发人员先撤退,我也偷偷摸摸溜走来缓解尴尬了。
因为我知道,我的推测出问题了。首先绑定变量这块,就出问题了。因为紧接着发现,top sql中下面还有不少sql语句,绑定变量都很多,where条件之前的绑定变量都是空值,并且,一条简单的insert into value语句,也查不到绑定变量。
敲黑板的时候到了,带着疑问寻找到知识点:
oracle捕获绑定变量的值会存在dba_hist_sqlbind和v$sql_bind_capture中,前者代表磁盘,后者代表内存中。受到参数cursor_bind_capture_destination控制,默认值是memory+disk,而之前查不到绑定变量的值,是由于oracle默认只捕获where谓词条件之后的绑定变量,对于where条件之前的绑定变量,则是不屑一顾了,高冷的很。
我尝试的去寻找是否可以捕获所有绑定变量值的方法,未果,只好寄希望于日后的机缘巧合了。
经此一折腾,大致判断出,我所遇到的cursor:mutex X应该和绑定变量的关系不大。
--------------------------------------------------------------------------------------
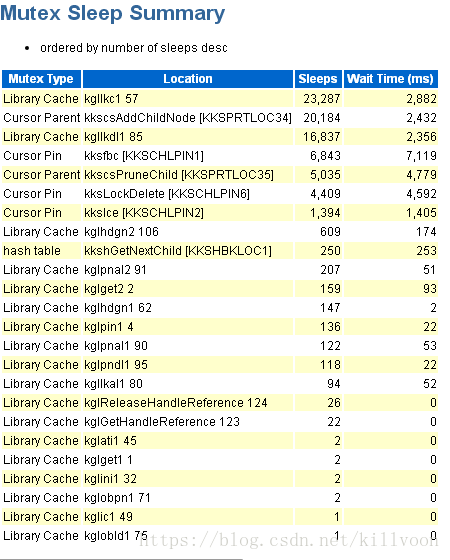
立马来了一招回头望月,再次细致的阅读awr报告,嘿,果然发现了点有意思的东西:
正常情况下的awr报告:
异常情况下的awr报告;
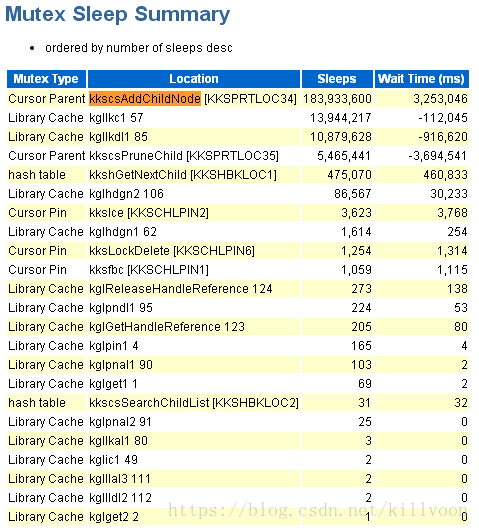
一目了然的可以看到:kkscsAddChildNode [KKSPRTLOC34] 就是导致mutex出问题的原因所在。
感谢oracle开发人员,这个看起来不知道是什么玩意的玩意,让我看明白了,是用来添加子游标的。呦呵,这不巧了么,前面提到过导致出现cursor:mutex X的情况就有增加子游标!
查了下v$sqlarea中的version_count,呵,不太对啊,怎么这么多语句都有上百个子游标。暂时不管,将上面的a9b79rtcm28q2带入到v$sql_shared_cursor,查看子游标失效的原因,发现绝大多数都是由于:roll_invalid_mismatch
roll_invalid_mismatch意思是由于收集过统计信息后,将相关对象游标置为invalid。
这里面涉及到一个知识点:
在10g之前一个对象的统计信息在收集后,相关的游标全部失效需要重新解析,这个可能造成风暴问题,在10g之后可以使用参数no_invalidate 控制这个行为,查看参数值
select DBMS_STATS.GET_PREFS ( pname =>'NO_INVALIDATE') from dual;
这个参数有下面的几个设置值
TRUE………………….: Does not invalidate the cursor.
FALSE…………………: Invalidates the cursor immediatelly, same as for verion <= 9i
AUTO_INVALIDATE.: Default value which means Oracle will invalidate over time.
对于oracle10g版本开始,默认值是auto_invalidate,其中涉及到一个隐藏参数:_optimizer_invalidation_period
该参数默认在是18000,单位秒,意思就是,虽然你是auto_invalidate,但是也是有时间限制的,这个时间就是_optimizer_invalidation_period 的值,即默认情况下,统计信息收集完之后,oracle会在18000秒之内将相关对象的游标置为invalid。
到这里,需要阐述一个情况,就是我这边在程序里面写的收集统计信息语句,no_invalidate都是设置成false的,也就是收集统计信息后立马将相关游标置为失效,重新生成新的子游标,这应该便是我看到的,很多sql语句都有多个子游标的原因。而之所以这么做的原因就是,之前遇到过统计信息做过了,但没有及时生效,仍然用的错误的统计信息,导致相关sql语句生成了一个笛卡尔乘积的执行计划,那滋味,相当酸爽。于是,一不做,二不休,在表数据量发生较大改动后收集统计信息,都是将游标立马失效生成新游标,而不是晃悠悠的等它个几个小时。。。
但是oracle每天晚上十点的统计信息收集任务仍然是默认的auto_invalidate,怀疑是晚上10点收集完统计信息后,晚上11点做跑批,概率性的遇到子游标恰巧被置为失效,并当大并发的情况下,产生了大量cursor:mutex X争用,遇到解析风暴。
咳咳,以上纯属推测,随时可能被打脸。
我采取的措施,是将每天晚上10点统计信息收集任务的no_invalidate置为false:
execute DBMS_STATS.SET_GLOBAL_PREFS ( pname =>'NO_INVALIDATE', pvalue => 'FALSE');
查看修改后的值:
select DBMS_STATS.GET_PREFS ( pname =>'NO_INVALIDATE') from dual;
也是邪性,改为之后,目前一周过去了,问题尚未出现,当然,不排除日后打脸,话还不能说的太死。
话虽如此,内心还是窃喜的,问题应该是解决了。
---------------------------------------------------------------------------------
需要点时间,去思考下,关于当下,关于未来,如何去做好一个丈夫,一个父亲,一个儿子,如何去他们的超级英雄!