ValueError: shapes (a,b) and (c,d) not aligned: b (dim 1) != c (dim 0)问题分析与解决方案
目录
1 问题提出
2 问题分析
3 解决方案
3.1 人为方法
3.2 机器方法
3.3 结合本nlp问题解决方案
3.4 其他方法
4 其他错误
0 引言
本文将会对此类错误 ValueError: shapes (a,b) and (c,d) not aligned: b (dim 1) != c (dim 0) 进行详细分析并提出解决方案,尤其实在机器学习中多发生此类错误,文章结合大家熟知的鸢尾花数据集进行问题分析,不仅对此类问题进行了解决,也对本程序应用在nlp文本分类中提出了解决方案。
1 问题提出
首先来看下面这个错误:
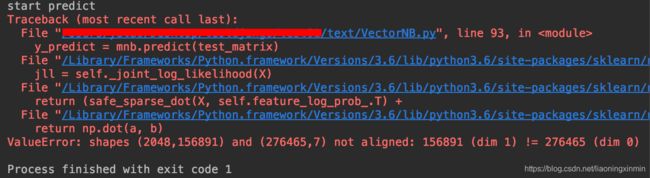
这个问题是使用机器学习的多项式贝叶斯函数做文本预测时出现的, 抛开文本预测这个局限,当使用机器学习函数进行模型构建与预测时就会出现类似的错误:ValueError: shapes (a,b) and (c,d) not aligned: b (dim 1) != c (dim 0)
这个错误是机器学习中的一个通病,错误中的a、b、c、d 实际数值可能会不同,请大家看清这个错误的样子,有助于下文理解。
2 问题分析
在进行实际问题分析之前,请允许我对问题背景进行简单介绍:
我在程序中使用机器学习中的贝叶斯模型训练文本数据,然后通过训练好的模型进行对测试集文本类别的预测。训练集与测试集的划分采用的是ML中的train_test_split。模型不可能对文本数据进行fit,需要提取文本特征,因此我在此使用的是TfidfVectorizer构建词典,并计算所有文章的tfidf值作为本文特征进行fit,模型训练过程无问题,而在predict过程中报错。
问题分析:
错误出现在使用模型进行预测时,观察上图报错的倒数第二行,即 return np.dot(a,b)
numpy的dot函数是进行矩阵乘法的函数,那我们了解若是想要两个矩阵相乘有一定的要求,就是第一个矩阵的列数必须与第二个矩阵的行数相同,若计算 matrix(a*b) * matrix(c,d) ,则 b=c 才可完成计算,即满足一定的维度要求。
了解矩阵乘法的要求后这个问题也就迎刃而解了,那观察上图倒数第一行:
ValueError: shapes (2048,156891) and (276465,7) not aligned: 156891 (dim 1) != 276465 (dim 0)
提示的ValueError错误中提供了两个shape的矩阵(也就是两个维度的矩阵),matrix (2048 * 156891) 与matrix (276465 * 7)。通过上述的矩阵乘法的常识,我们初步可以了解错误是由矩阵维度不同引起的,而通过错误实际提供的矩阵维度正好验证了我们的分析是正确的,即第一个矩阵的列的维度 156891 不等于 第二个矩阵行的维度 276465,正是错误中的 156891 (dim 1) != 276465 (dim 0)。
分析出了错误原因,还需了解这两个矩阵到底是什么,才能由根源解决问题。
matrix (2048 * 156891) 这个矩阵是模型使用predict函数进行预测所需要的数据,程序中的写法为
y_predict = mnb.predict(test_matrix)
此矩阵也就是 test_matrix 矩阵,此矩阵的行的维度 2048 是测试集的个数,就本问题来说是测试集文本的个数,矩阵的列的维度 156891 是 特征的个数,也就是说每个文本都根据词典选取了 156891 个特征值。 此处若您还不是很清楚,我举一个ML中非常经典的例子:鸢尾花数据集。鸢尾花数据集是列举了4个特征:花瓣的长度和宽度以及花萼的长度和宽度 。若你使用train_test_split函数分割的测试集为30个,此时这个矩阵的维度即为 30 * 4,30为测试集的个数,4为特征的个数。
matrix (276465 * 7) 这个矩阵是模型使用fit函数训练后的结果,程序中的写法为
mnb.fit(train_matrix,y_train)
此矩阵也就是 对train_matrix 与y_train 训练后的结果,此矩阵的行的维度 276465 是训练集选取的 特征的个数 ,也就是说训练集中每个文本都根据词典选取了 276465 个特征值,矩阵的列的维度 7 是类别的个数,本实验中我定义了7个文本类别。在鸢尾花实例中此矩阵的行数为选取特征的个数 4个:花瓣的长度和宽度以及花萼的长度和宽度,列数为类别的个数 3个:setosa、versicolor 或 virginica,此时这个矩阵的维度为 4 * 3。
对两个矩阵介绍后相信对错误的原因有了更为深刻的理解,那么你可能会问,为什么鸢尾花数据集进行训练时一点问题都没有?因为鸢尾花数据集的特征个数十分标准,是经过标准化处理的,即为4个,在全部鸢尾花数据集中,每一个 个体的特征都为4个,因此在进行模型预测时不会出问题,因为 第一个矩阵的列的维度 等于 第二个矩阵行的维度。
相必通过以上的介绍你也能理解模型是如何预测的,即是通过矩阵乘法,将测试集样本映射到不同的类别中,举个例子,测试集个数为10个,数据集选取特征数为1000个,类别为5类,相信你也可以写出预测的矩阵乘法了,即为:matrix1(10 * 1000) * matrix2(1000 * 5) = matrix3(10 * 5)最终将10个数据分别映射到了5个类别上,通过矩阵乘法实现了维度降低并最终进行类别预测。
倘若鸢尾花数据集中的特征不是十分标准,也就是没有标准化这个概念,那麻烦就大了,假如鸢尾花训练集均取4个特征进行模型训练,而测试集均取3个特征作为预测数据,则就会出现上述介绍的问题,将会出现下述错误。(假设10个测试集)
ValueError: shapes (10,3) and (4,3) not aligned: 3 (dim 1) != 4 (dim 0)
再倘若数据集特征毫无规律,第一条数据可能具有3个特征,第二条数据可能具有5个特征 等等情况,毫无标准,则此数据集是有问题的,必须处理后才能进行使用,也就是要引出的标准化的概念!
鸢尾花数据集是ML官方提供的,因此无可挑剔。但我希望用这个简单的数据集 帮助大家了解 ML模型是如何进行预测的,以及在模型训练时对数据集的标准化要求,不仅对ValueError问题有个更为全面的了解,同时也对其本质有了更为深层的理解。
至此在宏观上对这类问题的分析已经十分清楚了,下面将介绍几种解决方案,若不想了解此问题是如何发生在我所做的nlp问题中,可直接看下面的解决方案,若想要继续了解,并对比自己的程序中是否会出现这种问题,请看下面的结合详细问题的分析。
结合nlp的问题分析:
此问题是做nlp中十分经典的文本分类问题中发生的,在前面介绍过,文本特征提取我使用了 TfidfVectorizer ,TfidfVectorizer是ML中文本特征提取的工具之一,还有CountVectorizer、TfidfTransformer,但CountVectorizer + TfidfTransformer 的最终效果与TfidfVectorizer 处理的一样,因此选择TfidfVectorizer。
TfidfVectorizer 是通过词袋法进行构建的,即构建出所有文章去除停用词后的词典,然后计算该篇文章词的tfidf值,matrix (276465 * 7) 前面介绍的这个矩阵中行的维度即是选择的特征个数,也就意味着训练文本构造的词典长度为 276465,而matrix (2048 * 156891) 中列的维度 与 276465不同,因此报错。
在前面鸢尾花数据集中我特别强调标准化的概念,但在我们实际编程中,数据集并不是称心如意,往往会有各种问题,不符合作为模型等的输入。
我出现的问题:在通过train_test_split函数对分词并去除停用词的数据集切分成x_train,x_test后分别调用TfidfVectorizer进行处理x_train与x_test,我将TfidfVectorizer的处理过程封装如下:
def calTfidf(stopword,data):
tfvector = TfidfVectorizer(stop_words=stopword)
tfidf = tfvector.fit_transform(data)
return tfidf首先初始化 TfidfVectorizer ,并定义去除停用词,然后使用 TfidfVectorizer 的 fit_transform函数对数据进行训练,我的调用即为两次调用,matrix_train = calTfidf(stopword,x_train) matrix_test = calTfidf(stopword,x_test)
那么问题就出现了,两次调用 fit_transform函数对数据进行处理,每一次均构造了一个词袋,每一次调用生成一个新的标准,原本数据集中的文本长度就良莠不齐,选取的文本特征更是难得统一,那么调用两次,构造这两个词袋的长度又怎么会相同呢?就导致训练集词袋长度为276465 ,测试集词袋长度为156891,造成了错误,最根本的原因就是数据集的标准化问题!解决方案相见下面3.3 结合本nlp问题解决方案。
3 解决方案
3.1 人为方法
在问题分析中多次引出标准化问题,数据集是否标准化是此类错误的关键,那既然数据集不标准,我们的想法就是借助手段使其标准,首先介绍一下人为手段,在对数据集处理时,若发现哪个数据元素的维度与其他不同,那么可以通过 补0 进行处理。与木桶原理相反,数据集的长度应取决于长度最大的数据元素,对其他长度小于它的数据元素均进行补0处理,当然补0并不是最好的,但一定是可行可使用的,下面我通过一个实例说明一下:
word = [
[0.2,0.4,0.2,0.1,0,0.4],
[0.3,0.5,0.2],
[0.3,0.5,0.2,0.4,0]
]
#cal max length
length = [len(item) for item in word]
maxlength = max(length)
#fill zero
for item in word:
if len(item) < maxlength:
item.extend([0.]*(maxlength-len(item)))
print(word)假设word中每个列表元素即为特征值, 可以看到,每个列表长度都不相同,那么可以首先获取word中元素的最大长度 并赋予变量 maxlength,然后通过循环,使用extend函数补0,补0的次数为: 最大的长度 - 此元素的长度,然后就可以看到word中每一个列表元素长度相等,也就达到了标准化效果。
word:
[
[0.2, 0.4, 0.2, 0.1, 0.0, 0.4],
[0.3, 0.5, 0.2, 0.0, 0.0, 0.0],
[0.3, 0.5, 0.2, 0.4, 0.0, 0.0]
]但在对numpy.ndarray类型进行补0操作时十分困难,因此需要考虑下面的机器方法。
3.2 机器方法
机器方法中将会使用sklearn库中数据预处理函数fit_transform()和transform(),在上文提到了fit_transform(),使用fit_transform()进行对数据集的处理,TfidfVectorizer中调用fit_transform()是为了构造词典,并计算出每篇文章词语的tfidf值。
fit_transform()的作用就是先拟合数据集,然后转化数据集为标准化形式。transform()的作用是通过找中心和缩放等实现标准化。字面上看两个函数都是为了实现标准化,但fit_transform 首先需要拟合数据集,进行数据归一化处理,而transform 通过寻找fit_transform 归一化处理后的中心实现标准化,也就是说transform 依赖 fit_transform的处理结果。
结合到实际ML中就是对x_train 进行 fit_transform,再对x_test 进行 transform!由于transform 依赖 fit_transform的处理结果,因此必须先进行 fit_transform,在进行transform。
总结:对训练集使用 fit_transform ,对测试集使用 transform。使用代码请看下面3.3 。
3.3 结合本nlp问题解决方案
本程序中的解决方案:
#get all articles tfidf matrix
def calTfidf(stopword,x_train,x_test):
tfvector = TfidfVectorizer(stop_words=stopword)
x_train_matrix = tfvector.fit_transform(x_train)
x_test_matrix = tfvector.transform(x_test)
return x_train_matrix,x_test_matrix对x_train(训练集)进行 fit_transform,再对x_test (测试集)进行 transform 后训练集与测试集均已标准化,使得矩阵相乘时列的维度与行的维度相同,成功的解决了问题。
3.4 其他方法
在未使用fit_transform()和transform()处理之前,我想到了一种其他处理办法,由于本程序的问题是由于调用了两次TfidfVectorizer 的 fit_transform函数 导致生成了两种标准的数据,此时处理顺序是先切分 x_train, x_test, y_train, y_test ,再调用fit_transform函数处理。
那我的想法就是完全可以将上述顺序反过来,就是先使用fit_transform函数处理文本数据,构造出了统一标准的数据集,然后切分x_train, x_test, y_train, y_test,这样切分的数据集用于训练与测试是没有问题的,已经通过程序实验证实,书写程序如下面所示:
tfvector = TfidfVectorizer(stop_words=stopword)
matrix = tfvector.fit_transform(data) #data 为数据集,大小为3个
cls = [0,0,0]
x_train,x_test,y_train,y_test = train_test_split(matrix,cls,test_size=0.1,random_state=0)
mnb = MultinomialNB()
mnb.fit(x_train,y_train)
print(mnb.predict(x_test))
大家可以测试一下这种方式的效率,对比使用机器方法fit_transform()和transform() 哪个更快?
4 其他错误
ValueError: Expected 2D array, got 1D array instead:
这种值错误想必大家也会遇到过,“期待2维的数组,但是得到的是1维的数组”,简单写了一个错误代码供大家参考。
from sklearn.naive_bayes import MultinomialNB
x_train = [
[0.2, 0.4, 0.2, 0.1, 0, 0.4],
[0.3, 0.5, 0.2, 0.0, 0.0, 0.0],
[0.3, 0.5, 0.2, 0.4, 0, 0.0]
]
y_train = [0,0,1]
mnb = MultinomialNB()
mnb.fit(x_train,y_train)
x_test = [0.2, 0.4, 0.2, 0.1, 0]
mnb.predict(x_test)错误发生在模型predict位置,那我们观察x_train为二维数组,也就是模型是通过二维数组进行训练的,而在predict时传入的是一维数组x_test,解决方法很简单,在x_test外侧在嵌套一层 [ ] 即可,改变后为 :
x_test = [ [0.2, 0.4, 0.2, 0.1, 0] ]
文章为作者原创,如需转载,请注明出处!如有问题,请留言交流!