数据结构与算法:跳表的实现
我们知道Redis、LevelDB 都是著名的 Key-Value 数据库,Redis中 的 SortedSet以及LevelDB 中的 MemTable 都用到了跳表,那么什么是跳表呢?跳表又是如何实现的呢?
1、有序链表
说跳表之前,先说说有序链表:

一个有序链表搜索、添加、删除的平均时间复杂度是都是O(n)。有序数组的随机访问时间复杂度为O(1),在查询某个特定的元素的时候能够进行二分搜索优化,时间复杂度为O(logn)。因此有序链表的访问效率低于有序数据。那么就需要有某种方法来让有序链表搜索、添加、删除的平均时间复杂度降低至 O(logn),跳表这种方法就出现了。
2、什么是跳表
跳表,又叫做跳跃表、跳跃列表,是在有序链表的基础上增加了“跳跃”的功能,它是由William Pugh于1990年发布的,设计的初衷是为了取代平衡树(比如红黑树)。
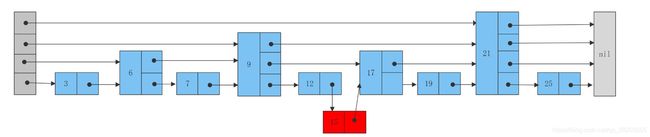
跳表的结构如下:

从图中可以看到, 跳跃表主要由以下部分构成:
- 表头(first):负责维护跳跃表的节点指针。
- 跳跃表节点:保存着元素值,以及多个层。
- 层:保存着指向其他元素的指针。高层的指针越过的元素数量大于等于低层的指针,为了提高查找的效率,程序总是从高层先开始访问,然后随着元素值范围的缩小,慢慢降低层次。
- 表尾:全部由
NULL组成,表示跳跃表的末尾。
对比于平衡树,跳表有以下优点:
-
跳表的实现和维护更加简单。
-
跳表的搜索、添加、删除的平均时间复杂度为 O(logn)。
-
跳表在新增、删除节点时不需要复杂的旋转。
3、跳表的搜索
① 从顶层链表的首元素开始,从左往右搜索,直至找到一个大于或等于目标的元素,或者到达当前层链表的尾部。
② 如果该元素等于目标元素,则表明该元素已被找到。
③ 如果该元素大于目标元素或已到达链表的尾部,则退回到当前层的前一个元素,然后转入下一层进行搜索。

比如要查找17这个数,先从头结点的顶层开始找,找到21,大于17,则返回头结点转入下一层,找到9,小于17,则从9向右查找到21,大于17,则返回上一节点9,转入下一层,开始搜索,发现9的下一个是17,说明被找到。
4、跳表的添加
① 根据跳表搜索的方式确定节点添加的位置
- a:如果已经存在这个节点,则覆盖
- b: 如果不存在,则应该找到第一个大于这个需要新添加的节点的位置
② 随机决定新添加元素的层数
例如,我们需要添加15这个元素:
5、跳表的删除
① 根据跳表搜索的方式确定节点删除的位置,如果已经存在这个节点,则删除
② 删除一个元素后,这个元素的所有前驱节点指向这个节点的所有后继节点
③ 删除一个元素后,整个跳表的层数可能会降低
例如,我们需要添加9这个元素:

6、代码实现
public class SkipList<K, V> {
//链表长度
private int size;
//虚拟节点 null
private Node<K, V> first;
//默认为32层
private static final int MAX_LEVEL = 32;
//redis中的层数因子
private static final double P = 0.25;
//有效层数
private int level;
private Comparator<K> comparator;
public SkipList() {
this(null);
}
public SkipList(Comparator<K> comparator) {
this.comparator = comparator;
first = new Node<K, V>(null, null, MAX_LEVEL);
}
public int size() {
return size;
}
//返回旧的值
public V put(K k, V v) {
checkKey(k);
Node<K, V> node = this.first;
//放置前驱节点
Node<K,V>[] pres=new Node[level];
int comp = -1;
for (int i = level - 1; i >= 0; i--) {
while (node.nexts[i] != null && (comp = compare(k, node.nexts[i].key)) > 0) {
node = node.nexts[i];
}
if (comp == 0) {
V oldValue = node.nexts[i].value;
node.nexts[i].value = v;
return oldValue;
}
pres[i]=node;
}
//新节点层数
int randomLevel = randomLevel();
//新节点
Node<K, V> newNode = new Node<>(k, v, randomLevel);
for (int i = 0; i <randomLevel ; i++) {
if(i>=level){
first.nexts[i]=newNode;
}else{
newNode.nexts[i] = pres[i].nexts[i];
pres[i].nexts[i]=newNode;
}
}
size++;
// 计算跳表的最终层数
level=Math.max(level,randomLevel);
return null;
}
/**
* 仿redis构造随机层数
*
* @return
*/
private int randomLevel() {
int level = 1;
while ((Math.random() < P) && level < MAX_LEVEL) {
level++;
}
return level;
}
public V get(K k) {
checkKey(k);
Node<K, V> node = this.first;
for (int i = level - 1; i >= 0; i--) {
int comp = -1;
while (node.nexts[i] != null && (comp = compare(k, node.nexts[i].key)) > 0) {
node = node.nexts[i];
}
if (comp == 0) return node.nexts[i].value;
}
return null;
}
public V remove(K k) {
checkKey(k);
V oldValue =null;
Node<K, V> node = this.first;
boolean exist = false;
int comp = -1;
for (int i = level - 1; i >= 0; i--) {
while (node.nexts[i] != null && (comp = compare(k, node.nexts[i].key)) > 0) {
node = node.nexts[i];
}
if (comp == 0) {
exist=true;
oldValue = node.nexts[i].value;
node.nexts[i] = node.nexts[i].nexts[i];
}
}
if(exist){
size--;
//更新跳表层数
int newLevel=level;
while (--newLevel>=0 && first.nexts[newLevel]==null){
level=newLevel;
}
}
return oldValue;
}
public int compare(K k1, K k2) {
return comparator != null ? comparator.compare(k1, k2)
: ((Comparable<K>) k1).compareTo(k2);
}
private void checkKey(K k) {
if (k == null) throw new IllegalArgumentException("k must not be null.");
}
private static class Node<K, V> {
K key;
V value;
Node<K, V>[] nexts;
public Node(K key, V value, int level) {
this.key = key;
this.value = value;
nexts = new Node[level];
}
@Override
public String toString() {
return "{"+key+":"+value+"}"+nexts.length;
}
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append("一共" + level + "层").append("\n");
for (int i = level - 1; i >= 0; i--) {
Node<K, V> node = first;
while (node.nexts[i] != null) {
sb.append(node.nexts[i]);
sb.append(" ");
node = node.nexts[i];
}
sb.append("\n");
}
return sb.toString();
}
}
7、测试
对跳表和二插搜索树TreeMap同时插入100万条数据,测试效率。
跳表:
public static void main(String[] args) {
long begin = System.currentTimeMillis();
SkipList<Integer, Integer> list = new SkipList<>();
int count = 100_0000;
int delta = 10;
//新增
for (int i = 0; i < count; i++) {
list.put(i, i + delta);
}
//删除
for (int i = 0; i < count; i++) {
list.remove(i);
}
long end = System.currentTimeMillis();
double duration = end - begin;
System.out.println("耗时:" + duration / 1000.0 + "s(" + duration + "ms)");
}
结果:
新增数据 耗时:0.395s(395.0ms)
删除数据 耗时:0.014s(14.0ms)
平衡二叉搜索树TreeMap:
public static void main(String[] args) {
long begin = System.currentTimeMillis();
TreeMap<Integer, Integer> map = new TreeMap<>();
int count = 100_0000;
int delta = 10;
//新增数据
for (int i = 0; i < count; i++) {
map.put(i, i + delta);
}
//删除数据
for (int i = 0; i < count; i++) {
map.remove(i);
}
long end = System.currentTimeMillis();
double duration = end - begin;
System.out.println("耗时:" + duration / 1000.0 + "s(" + duration + "ms)");
}
新增数据结果:
新增数据 耗时:0.339s(339.0ms)
删除数据 耗时:0.024s(24.0ms)
总结:由上面的实验得知,跳表和平衡二叉搜索树的增、删、查的效率差不多。