基于tensorflow的隐语义推荐系统
使用Tensorflow构造隐语义模型的推荐系统
3900 个电影
6,040个用户
数据简介: http://files.grouplens.org/datasets/movielens/ml-1m-README.txt
数据下载地址:http://files.grouplens.org/datasets/movielens/ml-1m.zip
http://www.lfd.uci.edu/~gohlke/pythonlibs/#tensorflow
# Imports for data io operations
from collections import deque
from six import next
import readers
# Main imports for training
import tensorflow as tf
import numpy as np
# Evaluate train times per epoch
import time
# Constant seed for replicating training results
np.random.seed(42)
u_num = 6040 # Number of users in the dataset
i_num = 3952 # Number of movies in the dataset
# 迭代更新大小
batch_size = 1000 # Number of samples per batch
# 隐含因子维度
dims = 5 # Dimensions of the data, 15
# 迭代次数
max_epochs = 50 # Number of times the network sees all the training data
# Device used for all computations
place_device = "/cpu:0"
分割数据:
def get_data():
# Reads file using the demiliter :: form the ratings file
# Columns are user ID, item ID, rating, and timestamp
# Sample data - 3::1196::4::978297539
# seq分割符
df = readers.read_file("./ml-1m/ratings.dat", sep="::")
rows = len(df)
# Purely integer-location based indexing for selection by position
# 打乱原数据的顺序
df = df.iloc[np.random.permutation(rows)].reset_index(drop=True)
# Separate data into train and test, 90% for train and 10% for test
split_index = int(rows * 0.9)
# Use indices to separate the data
df_train = df[0:split_index]
df_test = df[split_index:].reset_index(drop=True)
return df_train, df_test
def clip(x):
return np.clip(x, 1.0, 5.0)
隐语义模型,添加了全局大环境偏差、用户偏差、电影偏差
def model(user_batch, item_batch, user_num, item_num, dim=5, device="/cpu:0"):
with tf.device("/cpu:0"):
with tf.variable_scope('lsi',reuse=True):
# Using a global bias term
# 全局大环境偏差
bias_global = tf.get_variable("bias_global", shape=[])
# User and item bias variables
# get_variable: Prefixes the name with the current variable scope
# and performs reuse checks.
# 用户偏差w_bias_user、电影偏差w_bias_item
# bias的shape=用户数量
w_bias_user = tf.get_variable("embd_bias_user", shape=[user_num])
w_bias_item = tf.get_variable("embd_bias_item", shape=[item_num])
# embedding_lookup: Looks up 'ids' in a list of embedding tensors
# Bias embeddings for user and items, given a batch
# 每次训练只需要查找得到batch中用户的bias,而不是全部用户的bias
bias_user = tf.nn.embedding_lookup(w_bias_user, user_batch, name="bias_user")
bias_item = tf.nn.embedding_lookup(w_bias_item, item_batch, name="bias_item")
# User and item weight variables
# w_user、w_item为要优化的矩阵,初始化初值为高斯分布
w_user = tf.get_variable("embd_user", shape=[user_num, dim],
initializer=tf.truncated_normal_initializer(stddev=0.02))
w_item = tf.get_variable("embd_item", shape=[item_num, dim],
initializer=tf.truncated_normal_initializer(stddev=0.02))
# 优化batch中用户的矩阵中的值
# Weight embeddings for user and items, given a batch
embd_user = tf.nn.embedding_lookup(w_user, user_batch, name="embedding_user")
embd_item = tf.nn.embedding_lookup(w_item, item_batch, name="embedding_item")
with tf.device(device):
# reduce_sum: Computes the sum of elements across dimensions of a tensor
infer = tf.reduce_sum(tf.multiply(embd_user, embd_item), 1)
infer = tf.add(infer, bias_global)
infer = tf.add(infer, bias_user)
infer = tf.add(infer, bias_item, name="svd_inference")
# l2_loss: Computes half the L2 norm of a tensor without the sqrt
regularizer = tf.add(tf.nn.l2_loss(embd_user), tf.nn.l2_loss(embd_item),
name="svd_regularizer")
# infer-结果值, regularizer-l2惩罚项
return infer, regularizer
更新迭代:
def loss(infer, regularizer, rate_batch, learning_rate=0.001, reg=0.1, device="/cpu:0"):
with tf.device(device):
# Use L2 loss to compute penalty
# 计算结果和真实结果的损失
cost_l2 = tf.nn.l2_loss(tf.subtract(infer, rate_batch))
# 惩罚项的损失,设置惩罚力度
penalty = tf.constant(reg, dtype=tf.float32, shape=[], name="l2")
# 总的损失cost
cost = tf.add(cost_l2, tf.multiply(regularizer, penalty))
# 'Follow the Regularized Leader' optimizer
# 梯度下降
train_op = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
return cost, train_op
开始训练:
# Read data from ratings file to build a TF model
df_train, df_test = get_data()
samples_per_batch = len(df_train) // batch_size
print("Number of train samples %d, test samples %d, samples per batch %d" %
(len(df_train), len(df_test), samples_per_batch))
# Using a shuffle iterator to generate random batches, for training
iter_train = readers.ShuffleIterator([df_train["user"],
df_train["item"],
df_train["rate"]],
batch_size=batch_size)
# Sequentially generate one-epoch batches, for testing
iter_test = readers.OneEpochIterator([df_test["user"],
df_test["item"],
df_test["rate"]],
batch_size=-1)
user_batch = tf.placeholder(tf.int32, shape=[None], name="id_user")
item_batch = tf.placeholder(tf.int32, shape=[None], name="id_item")
rate_batch = tf.placeholder(tf.float32, shape=[None])
infer, regularizer = model(user_batch, item_batch, user_num=u_num, item_num=i_num, dim=dims, device=place_device)
_, train_op = loss(infer, regularizer, rate_batch, learning_rate=0.0010, reg=0.05, device=place_device)
保存模型:
# 保存模型
saver = tf.train.Saver()
# 实例化
init_op = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_op)
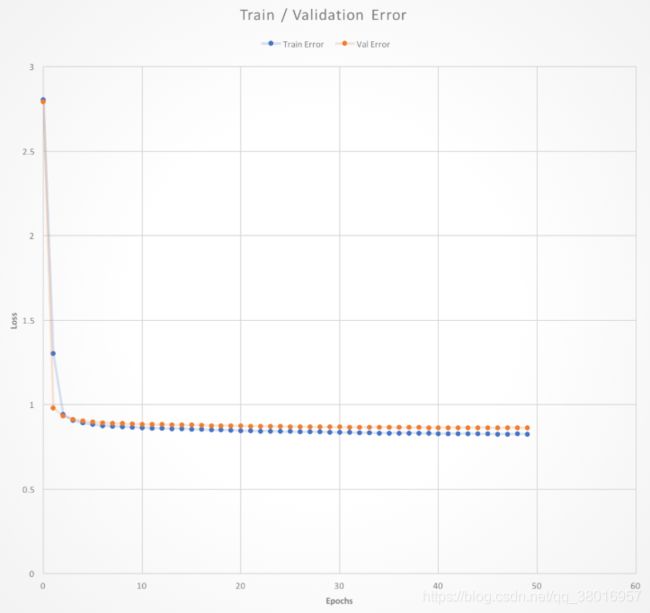
print("%s\t%s\t%s\t%s" % ("Epoch", "Train Error", "Val Error", "Elapsed Time"))
errors = deque(maxlen=samples_per_batch)
start = time.time()
for i in range(max_epochs * samples_per_batch):
users, items, rates = next(iter_train)
_, pred_batch = sess.run([train_op, infer], feed_dict={user_batch: users,
item_batch: items,
mul rate_batch: rates})
pred_batch = clip(pred_batch)
errors.append(np.power(pred_batch - rates, 2))
if i % samples_per_batch == 0:
train_err = np.sqrt(np.mean(errors))
test_err2 = np.array([])
for users, items, rates in iter_test:
pred_batch = sess.run(infer, feed_dict={user_batch: users,
item_batch: items})
pred_batch = clip(pred_batch)
test_err2 = np.append(test_err2, np.power(pred_batch - rates, 2))
end = time.time()
print("%02d\t%.3f\t\t%.3f\t\t%.3f secs" % (i // samples_per_batch, train_err, np.sqrt(np.mean(test_err2)), end - start))
start = end
saver.save(sess, './save/')