pytorch-经典的网络架构
最近在学习如何使用pytorch构建网络架构,现在整理一些常见的网络架构
1 VGG
VGG是一个非常“整齐”和“美观”的网络架构,很多模型都是以VGG作为网络的backbone,VGG的网络架构是这样的
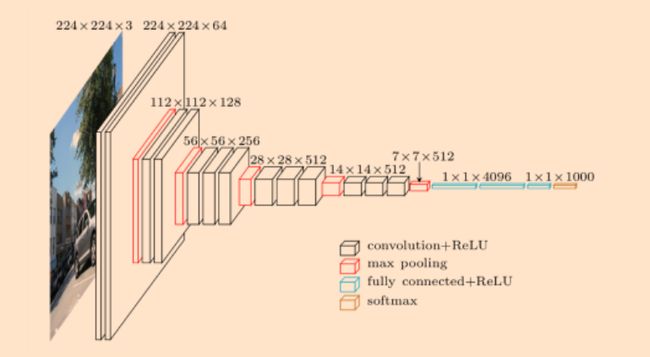
下面是使用pytorch的网络架构的过程。我们在使用pytorch构建网络架构的时候,不需要关心feature map的尺寸,我们只需要关心输入输出的channels。在VGG中是使用maxpooling进行下采样的,maxpooling的kernel_size=2,stride=2,padding=0。
通常来说,我们进行2倍下采样的常用的是:
kernel_size = 2, stride = 2, padding = 0 : 不使用padding
kernel_size = 3, stride = 2, padding = 1 : 使用padding
class VGG16(nn.Module):
def __init__(self):
super(VGG, self).__init__()
# the vgg's layers
# self.features = features
# 13 conv + 3 FC
cfg = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M']
layers = []
batch_norm = False
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.Batchnorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
# use the vgg layers to get the feature
self.features = nn.Sequential(*layers)
# 全局池化
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
# 决策层:分类层
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 1000),
)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 1)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.features(x)
x_fea = x
x = self.avgpool(x)
x_avg = x
# batch*pixel
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x, x_fea, x_avg当然,pytorch已经将VGG16封装成一个模块了,你可以使用相关的API调用这个模块
import torchvision.models as models
models.vgg16(pretrained=True)