小白科研笔记:深入理解SA-SSD的子网络细节和Loss计算以及数据增强策略
1. 引言
前面若干篇博客讨论分析了SA-SSD的输入输出流,所需数据集的格式,整体网络框架,voxel生成,Anchor使用,BEV特征转换等等细节。同时对mmdetection的训练数据处理,训练推断等等做了一些了解。这篇博客将探讨SA-SSD中各种误差函数的计算细节。这篇博客主要讨论SA-SSD中几个问题:
- 辅助网络的细节和它的误差函数
rpn_head的细节和它的误差函数extra_head的细节和它的误差函数- 训练时候数据增强的细节
2. 辅助网络
2.1 深入理解辅助网络
SA-SSD论文框架中的辅助网络和Backbone Network对应代码中的Neck部分(事实上Neck还包括了处理BEV特征的网络)。在基类SingleStageDetector的前向运算中,对应代码是:
# Neck的粗糙结构如下所示:
# 输入点云 => Backbone Network => reshape 操作 => BEV Network => (x, conv6)
# ||
# || Tensor2Point (体素变点云)
# ||
# 辅助网络层 => MLP层 => point_misc
#
# 稀疏卷积 和 Reshape 和 Tensor2Point 的细节我在上一篇博客已经讨论了。
#
# 输入分析:
# vx 可以理解为 pointclpoud_range 内的点云,包含 xyz 和雷达强度项,是 (N,4).
# ret['coordinates'] 是 pointclpoud_range 内的点云体素化的结果
# batch_size 是批处理的大小
# 吐槽: ret['coordinates'] 才是真体素,如果我的理解有误,请大家多多指正
#
# 输出分析 :
# x, conv6 都是 BEV特征图
# point_misc = (points_mean, point_cls, point_reg) 它是个元组
# points_mean 是 bxyz 类型数据,xyz 是点云位置,b 是体素化后 z 轴分量, 它是(N,4)张量,为什么会有 b 这个分量,我也不太清楚,但是代码是这样写的
# point_cls 是点云分类结果,它是(N,1)张量,用于前景分割(可不是3d目标分类呀)
# point_reg 是点云回归结果,回归每一个3d类的中心位置,它是(N,3)张量
#
# 因为 SA-SSD 采用的是一个粗糙体素化处理方式,所以 vx 和 points_mean 的长度都是 N
(x, conv6), point_misc = self.neck(vx, ret['coordinates'], batch_size)
啰嗦一下,x, conv6之间差一个卷积BN池化层,在BEVNet的前向计算中的代码片段。
x = F.relu(self.bn6(x), inplace=True)
conv6 = x.clone()
x = self.conv7(x)
x = F.relu(self.bn7(x), inplace=True)
return x, conv6
我再次贴出Neck部分的前向计算代码。之前我分析过它粗框架,现在细致分析每一个变量的张量形式。
# voxel_features 是 pointclpoud_range 内的点云和雷达强度项 (N,4)张量
# coors 是 pointclpoud_range 内的点云体素化的结果 [z,y,x]
# coors 体素顺序为什么是 [z,y,x] 呢? 可以追溯变量,一直到 KITTILiDAR 中的 prepare_train_img
def forward(self, voxel_features, coors, batch_size, is_test=False):
points_mean = torch.zeros_like(voxel_features) # 初始化为(N,4)零值张量
points_mean[:, 0] = coors[:, 0] # 保留体素中 z 轴分量
points_mean[:, 1:] = voxel_features[:, :3] # 保留点云中 xyz 轴分量
coors = coors.int() # 整数化
# SparseConvTensor 还暂不清楚它的内部细节
# 考虑到稀疏卷积的输入是体素化的张量,x 应该是 [N, C, D, H, W] 张量形式
# D, H, W 是体素化点云总尺寸,C 是体素点的特征通道数,N 是批处理大小
# D = 40, H = 1408, W = 1600,这是根据点云范围和 Voxel 尺寸计算得到的
# C = 3 或者 4,可能包含强度项
x = spconv.SparseConvTensor(voxel_features, coors, self.sparse_shape, batch_size)
# backbone 包含 SA-SSD 框图中的 Backbone Network 和辅助网络
x, point_misc = self.backbone(x, points_mean, is_test)
# 从体素化点特征转变到 BEV 图特征
x = x.dense()
N, C, D, H, W = x.shape
x = x.view(N, C * D, H, W)
# 把 BEV 特征喂入 BEV 网络中
x = self.fcn(x)
if is_test:
return x
return x, point_misc
然后我们深入理解Neck中的self.backbone(对应SA-SSD中的Backbone Network)的前向计算部分。我会尽力分析它各个张量的尺寸含义。
# x 是 [B, C, D, H, W] 张量,B 是批处理尺寸
# 具体而言,x 是 [B, 3(4), 40, 1408, 1600] 的张量
# points_mean 是 [N, 4] 张量,含义是 bxyz
def forward(self, x, points_mean, is_test=False):
x = self.conv0(x)
x = self.down0(x) # sp 带降采样的点云卷积
x = self.conv1(x) # 2x sub [B, C1, D/2, H/2, W/2]
if not is_test:
# 体素转点云,注意 voxel_size=(.1, .1, .2),比原 voxel 大了一倍,
# 这是因为 conv1 采样的结果
# vx_nxyz 是 [N1, 4] 张量,4 是 bxyz
# vx_feat 是 [N1, C1] 张量
vx_feat, vx_nxyz = tensor2points(x, voxel_size=(.1, .1, .2))
# points_mean 是 [N, 4] 张量
# 注意 N1 < N,因为 N1 是降采样后的体素。
# nearest_neighbor_interpolate 就是近邻插值
# 遍历 N 个点云中任意一点,找 N1 中与它最近的三个点,
# 然后这个点的特征是三个点特征的平均,这是借鉴了 PointNet++ 的思想
# p1 是 [N, C1] 的张量
p1 = nearest_neighbor_interpolate(points_mean, vx_nxyz, vx_feat)
x = self.down1(x) # 带降采样的点云卷积
x = self.conv2(x) # [B, C2, D/4, H/4, W/4]
if not is_test:
# vx_nxyz 是 [N2, 4] 张量
# vx_feat 是 [N2, C2] 张量
# N2 < N1 < N
vx_feat, vx_nxyz = tensor2points(x, voxel_size=(.2, .2, .4))
# p2 是 [N, C2] 的张量
p2 = nearest_neighbor_interpolate(points_mean, vx_nxyz, vx_feat)
x = self.down2(x) # 带降采样的点云卷积
x = self.conv3(x) # [B, C3, D/8, H/8, W/8]
if not is_test:
# vx_nxyz 是 [N3, 4] 张量
# vx_feat 是 [N3, C3] 张量
# N3 < N2 < N1 < N
vx_feat, vx_nxyz = tensor2points(x, voxel_size=(.4, .4, .8))
# p3 是 [N, C3] 的张量
p3 = nearest_neighbor_interpolate(points_mean, vx_nxyz, vx_feat)
# 输出 [B, C4, D/8, H/8, W/8] 的结果
out = self.extra_conv(x)
if is_test:
return out, None
# torch.cat([p1, p2, p3]) 是 [N, C1+C2+C3] 的张量
# pointwise 是 [N, 64] 的张量
pointwise = self.point_fc(torch.cat([p1, p2, p3], dim=-1))
point_cls = self.point_cls(pointwise) # [N, 1] 的张量,预测是否是前景/背景
point_reg = self.point_reg(pointwise) # [N, 3] 的张量,预测3d目标的中心位置
return out, (points_mean, point_cls, point_reg)
基本上每个变量的张量都理清楚了。
再来看看函数nearest_neighbor_interpolate的内部细节,借鉴了PointNet++的实现:
# unknown 是点云中的点,(n,4),4 指 bxyz
# known 是体素转点云后的点,(m,3),m 是稀疏卷积降采样后的点
# known_feats 是这些点的特征,(m,C)
def nearest_neighbor_interpolate(unknown, known, known_feats):
"""
:param pts: (n, 4) tensor of the bxyz positions of the unknown features
:param ctr: (m, 4) tensor of the bxyz positions of the known features
:param ctr_feats: (m, C) tensor of features to be propigated
:return:
new_features: (n, C) tensor of the features of the unknown features
"""
# 找最近的三个点,对每一个 unknown 中的点,从 known 中找出三个与它近邻的点
dist, idx = pointnet2_utils.three_nn(unknown, known)
dist_recip = 1.0 / (dist + 1e-8)
norm = torch.sum(dist_recip, dim=1, keepdim=True)
# 权值比跟距离有关
weight = dist_recip / norm
# 近邻特征的加权插值
interpolated_feats = pointnet2_utils.three_interpolate(known_feats, idx, weight)
return interpolated_feats
到这里,应该辅助网络和Backbone Network中所有变量的张量尺寸都搞清楚了。这个时候来看辅助网络误差计算的方式。
2.2 辅助网络误差计算
在基类SingleStageDetector的前向计算中,计算辅助网络误差的代码如下所示:
losses = dict()
# point_misc = (points_mean, point_cls, point_reg)
# points_mean 是 [N,4] 的张量,4 指 bxyz
# point_cls 是 [N,1] 的张量,判别前景/后景
# point_reg 是 [N,3] 的张量,预测3d目标中心点
aux_loss = self.neck.aux_loss(*point_misc, gt_bboxes=ret['gt_bboxes'])
losses.update(aux_loss)
函数aux_loss主要计算:
- 点前景/后景分类误差,分类问题,使用
focal loss损失函数 - 3d目标中心点回归误差,回归问题,使用
smooth L1损失函数
在了解误差计算意义,以及误差函数输入变量含义后,深入理解self.neck.aux_loss:
# points 是 [A,4] 的张量,4 指 bxyz
# point_cls 是 [A,1] 的张量,判别前景/后景
# point_reg 是 [A,3] 的张量,预测3d目标中心点
# gt_bboxes 是长度为 N 的元组
def aux_loss(self, points, point_cls, point_reg, gt_bboxes):
N = len(gt_bboxes) # 这份点云中有 N 个车类目标
# 生成点云前景/后景的真值 pts_labels [A,1] bool 型
# 生成3d目标中心点的真值 center_targets [A,3]
pts_labels, center_targets = self.build_aux_target(points, gt_bboxes)
rpn_cls_target = pts_labels.float() # 转 float 型
pos = (pts_labels > 0).float() # 获取前景点索引向量
neg = (pts_labels == 0).float() # 获取背景点索引向量
pos_normalizer = pos.sum() # 前景点总数
pos_normalizer = torch.clamp(pos_normalizer, min=1.0) # 前景点总数必须大于等于 1
cls_weights = pos + neg
cls_weights = cls_weights / pos_normalizer
reg_weights = pos # 回归中心点,肯定是在预测为前景点的点云做回归的
reg_weights = reg_weights / pos_normalizer
# 对于正负样本不均衡的数据中使用 Focal Loss 做分类问题的损失函数
# 对于一个大点云来说,显然是背景点要多很多
aux_loss_cls = weighted_sigmoid_focal_loss(point_cls.view(-1), rpn_cls_target, weight=cls_weights, avg_factor=1.)
aux_loss_cls /= N
# 回归问题业界用 smooth l1
# 为什么这里要加权呢,是因为要滤去背景点的回归结果,只计算前景点的回归结果
aux_loss_reg = weighted_smoothl1(point_reg, center_targets, beta=1 / 9., weight=reg_weights[..., None], avg_factor=1.)
aux_loss_reg /= N
return dict(
aux_loss_cls = aux_loss_cls,
aux_loss_reg = aux_loss_reg,
)
最后看看build_aux_target的内部细节(这一块有些细节我还没有弄懂):
# nxyz是 [A,4] 的张量,4 指 bxyz
# gt_boxes3d 是长度为 N 的元组
def build_aux_target(self, nxyz, gt_boxes3d, enlarge=1.0):
center_offsets = list()
pts_labels = list()
# 遍历每一个 3D 目标真值框
for i in range(len(gt_boxes3d)):
boxes3d = gt_boxes3d[i].cpu()
# 这一行代码我没看懂,为什么 nxyz[:, 0] 会跟 i 有关?
# 如果我日后明白,回来补充
idx = torch.nonzero(nxyz[:, 0] == i).view(-1)
new_xyz = nxyz[idx, 1:].cpu()
boxes3d[:, 3:6] *= enlarge
# 把真值 3d 框内的点作为前景点,以及返回这个 3d 框的中心位置
pts_in_flag, center_offset = pts_in_boxes3d(new_xyz, boxes3d)
pts_label = pts_in_flag.max(0)[0].byte()
# 收集结果
pts_labels.append(pts_label)
center_offsets.append(center_offset)
center_offsets = torch.cat(center_offsets).cuda()
pts_labels = torch.cat(pts_labels).cuda()
return pts_labels, center_offsets
3. RPN Head
3.1 深入理解rpn_head
在讨论rpn_head之前,我总结一下第二节讨论的结果。做个承上启下。
我在第2.1节讨论了Neck的结构,主干部分由Backbone Network和BEV Net合并而成。Backbone Network输入是体素化的点云,由一个 B × C × D × H × W B\times C\times D\times H\times W B×C×D×H×W尺寸的张量构成。 B B B是批处理大小。 C C C是体素化点云的通道数,输入通道数为 1 1 1。其中 H × W × D H\times W\times D H×W×D是构成整个体素化点云的尺寸。具体而言 H = 1600 H=1600 H=1600, W = 1408 W=1408 W=1408, D = 40 D=40 D=40。(为啥是这些数值,请参考我上一篇博客中关于Voxel计算部分)。
输入的体素化点云的张量是 B × 1 × 40 × 1600 × 1408 B\times 1\times 40\times 1600\times 1408 B×1×40×1600×1408。
经过Backbone Network得到的点云特征的张量是 B × C 1 × 5 × 200 × 176 B\times C_1\times 5\times 200\times 176 B×C1×5×200×176。因为Backbone Network中有三次降采样的稀疏点云卷积,所以体素尺寸减小了 8 8 8倍。
经过Reshape后得到的BEV特征的张量是 B × 5 C 1 × 200 × 176 B\times 5C_1\times 200\times 176 B×5C1×200×176。
BEV特征输入至BEV Net输出的BEV特征的张量是 B × C 2 × 200 × 176 B\times C_2\times 200\times 176 B×C2×200×176。卷积并没有改变特征图的尺寸。
然后这个BEV特征会喂入到rpn_head中。一切准备就绪,我开始分析rpn_head的代码,来深入分析它前向计算的代码:
# 进过上述讨论,x 是 [B, C, 200, 176] 的张量
def forward(self, x):
# conv_box 和 conv_cls 是 1*1 的卷积
box_preds = self.conv_box(x) # 输出 [B, 14, 200, 176] 的张量
cls_preds = self.conv_cls(x) # 输出 [B, 2, 200, 176] 的张量
# 为啥会出现 14?
# 是因为 conv_box 的通道数定义为 num_anchor_per_loc * box_code_size = 2*7
# 对张量做置换,contiguous 是让置换后的张量内存分布连续的操作
box_preds = box_preds.permute(0, 2, 3, 1).contiguous() # [B, 200, 176, 14]
cls_preds = cls_preds.permute(0, 2, 3, 1).contiguous() # [B, 200, 176, 2]
if self._use_direction_classifier:
# conv_dir_cls 也是 1*1 的卷积
dir_cls_preds = self.conv_dir_cls(x) # 输出 [B, 4, 200, 176] 的张量
# 为什么是 4 呢?
# 是因为 conv_dir_cls 的通道数定义为 num_anchor_per_loc * 2 = 2*2
# 输出 [B, 200, 176, 4] 的张量
dir_cls_preds = dir_cls_preds.permute(0, 2, 3, 1).contiguous()
return box_preds, cls_preds, dir_cls_preds
运行的时候,使用print做了检查,验证了我的推算是对的。
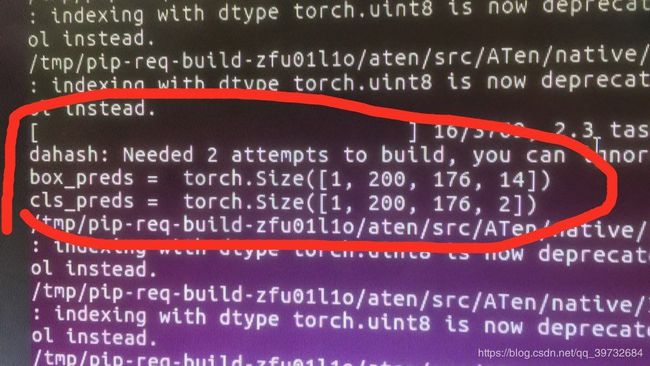
3.2 rpn_head网络误差计算
简而言之,rpn_head预测3d目标框和它本身朝向以及它对应的类别,所以它的误差函数主要是两种:
- 3d目标框的误差函数;使用
smooth L1误差损失函数; - 3d目标框对应目标类别的误差函数;类别用
one_hot编码,使用Focal loss损失函数;因为SA-SSD只识别车这一类,所以one_hot是 2 × 1 2\times 1 2×1向量,表示车类点和背景点; - 3d目标框朝向的误差函数;使用交叉熵损失函数;
rpn_head的前向计算并不难理解。比较复杂的是它误差计算的流程。复杂并不是说误差函数很复杂,而是其中的一些代码细节比较繁杂(有些细节我没有看懂,请多多见谅,日后看懂会更新)。我来看看它的loss函数:
# box_preds, cls_preds 是 RPN 网络的预测值,分别是
# [B, 200, 176, 14] 的张量和 [B, 200, 176, 2] 的张量
# gt_bboxes, gt_labels 是 3d 目标的框参数和类别
# anchors, anchors_mask 的概念在上一篇博客已经介绍了
# cfg 是配置参数
def loss(self, box_preds, cls_preds, dir_cls_preds, gt_bboxes, gt_labels, anchors, anchors_mask, cfg):
batch_size = box_preds.shape[0]
# 下面几行代码的作用
# 生成与 box_preds, cls_preds 相对应的真值 targets,cls_targets
# 和与之对应的权值 reg_weights 和 cls_weights
labels, targets, ious = multi_apply(create_target_torch,
anchors, gt_bboxes,
anchors_mask, gt_labels,
similarity_fn=getattr(iou3d_utils, cfg.assigner.similarity_fn)(),
box_encoding_fn = second_box_encode,
matched_threshold=cfg.assigner.pos_iou_thr,
unmatched_threshold=cfg.assigner.neg_iou_thr,
box_code_size=self._box_code_size)
labels = torch.stack(labels,)
targets = torch.stack(targets)
# 计算权值,计算方式跟辅助网络中的很相似
cls_weights, reg_weights, cared = self.prepare_loss_weights(labels)
# cared 表示 labels >= 0 的 bool 张量
# cls_targets 就是过滤掉 labels == -1 的张量
cls_targets = labels * cared.type_as(labels)
# 根据预测值,真值,权重,构建误差函数
# 为了让 3d框 的回归变得更加准确,加入 _encode_rad_error_by_sin 更细致刻画 3d 框
# loc_loss 是 3d框 的误差
# cls_loss 是 3d框类别 的误差
# 权值的意义:
# 对于 loc_loss,我只关心车这一类的3d目标框,设置其他类和背景点的权值为零,滤除它们
# 对于 cls_loss,正样本和负样本数量差异太大,比如正样本(是车的目标)太少,
# 需要加大它误差对应的权值,提高网络对车识别的准确率
loc_loss, cls_loss = self.create_loss(
box_preds=box_preds,
cls_preds=cls_preds,
cls_targets=cls_targets,
cls_weights=cls_weights,
reg_targets=targets,
reg_weights=reg_weights,
num_class=self._num_class,
encode_rad_error_by_sin=self._encode_rad_error_by_sin,
use_sigmoid_cls=self._use_sigmoid_cls,
box_code_size=self._box_code_size,
)
loc_loss_reduced = loc_loss / batch_size
loc_loss_reduced *= 2
cls_loss_reduced = cls_loss / batch_size
cls_loss_reduced *= 1
loss = loc_loss_reduced + cls_loss_reduced
if self._use_direction_classifier:
# 生成与 dir_cls_preds 对应的真值 dir_labels
dir_labels = self.get_direction_target(anchors, targets, use_one_hot=False).view(-1)
dir_logits = dir_cls_preds.view(-1, 2)
# 设置权值是为了仅仅考虑 labels > 0 的目标(即车这一类)
weights = (labels > 0).type_as(dir_logits)
weights /= torch.clamp(weights.sum(-1, keepdim=True), min=1.0)
# 使用交叉熵做朝向预测的误差损失函数
dir_loss = weighted_cross_entropy(dir_logits, dir_labels,
weight=weights.view(-1),
avg_factor=1.)
dir_loss_reduced = dir_loss / batch_size
dir_loss_reduced *= .2
loss += dir_loss_reduced
return dict(rpn_loc_loss=loc_loss_reduced, rpn_cls_loss=cls_loss_reduced, rpn_dir_loss=dir_loss_reduced)
函数create_loss里面计算比较好理解,核心是调用weighted_smoothl1计算loc_loss,调用weighted_sigmoid_focal_loss计算cls_loss。函数create_target_torch就比较复杂了。我还没太弄懂。等我调试的时候,如果有需要,再去做理解。
4. Extra Head
4.1 深入理解extra_head
从之前一篇我写的博客的计算图可以看出,extra_head的输入是conv_6和guided_anchors,输出bbox_score,代表guided_anchors对应3d目标的类别。所以extra_head的损失函数跟预测类别有关,选取Focal loss。代码中的extra_head对应论文框图中的PS Warp。来深入分析它的前向计算:
# x 指 conv_6
def forward(self, x, guided_anchors, is_test=False):
x = self.convs(x)
# 字面上理解,bbox_scores 是每一个 guided_anchors 的分数
# bbox_scores 又反映每一个 guided_anchors 的类别 (代码就是这样写的)
bbox_scores = list()
for i, ga in enumerate(guided_anchors):
# 一边遍历一边给 bbox_scores 做零值初始化
if len(ga) == 0:
bbox_scores.append(torch.empty(0).type_as(x))
continue
# 获取当前 guided_anchors 在 BEV 视图下的覆盖范围
# [0, 1, 3, 4, 6] 指 xylw 和 旋转角
(xs, ys) = self.gen_grid_fn(ga[:, [0, 1, 3, 4, 6]])
im = x[i]
# 获取当前 guided_anchors 在 BEV 视图下的覆盖范围下的特征图中的值
out = bilinear_interpolate_torch_gridsample(im, xs, ys)
# 当前 guided_anchors 的得分值为特征块 out 的平均值
# 这整个计算得分值的过程就是 PS Warp
score = torch.mean(out, 0).view(-1)
bbox_scores.append(score)
if is_test:
return bbox_scores, guided_anchors
else:
return torch.cat(bbox_scores, 0)
4.2 extra_head网络误差计算
在4.1节分析过,extra_head的的loss计算只包含分类误差函数。计算过程如下所示。计算权值,使用weighted_sigmoid_focal_loss的方式跟rpn_head中的分类误差函数是一样的。
# cls_preds 是 bbox_scores
def loss(self, cls_preds, gt_bboxes, gt_labels, anchors, cfg):
batch_size = len(anchors)
labels, targets, ious = multi_apply(create_target_torch,
anchors, gt_bboxes,
(None,) * batch_size, gt_labels,
similarity_fn=getattr(iou3d_utils, cfg.assigner.similarity_fn)(),
box_encoding_fn = second_box_encode,
matched_threshold=cfg.assigner.pos_iou_thr,
unmatched_threshold=cfg.assigner.neg_iou_thr)
labels = torch.cat(labels,).unsqueeze_(1)
# soft_label = torch.clamp(2 * ious - 0.5, 0, 1)
# labels = soft_label * labels.float()
cared = labels >= 0
positives = labels > 0
negatives = labels == 0
negative_cls_weights = negatives.type(torch.float32)
cls_weights = negative_cls_weights + positives.type(torch.float32)
pos_normalizer = positives.sum().type(torch.float32)
cls_weights /= torch.clamp(pos_normalizer, min=1.0)
cls_targets = labels * cared.type_as(labels)
cls_preds = cls_preds.view(-1, self._num_class)
cls_losses = weighted_sigmoid_focal_loss(cls_preds, cls_targets.float(), \
weight=cls_weights, avg_factor=1.)
cls_loss_reduced = cls_losses / batch_size
return dict(loss_cls=cls_loss_reduced,)
5. 数据增强和网络输出的细节
之前忘记说了,SA-SSD训练的时候对输入数据点云做了数据增强(Data Augmentation)。在KITTILiDAR中有数据增强的代码,代码节选如下所示:
# 给点云加噪声,给 num_try 个点加噪声
self.augmentor.noise_per_object_(gt_bboxes, points, num_try=100)
# 对点云做翻转操作,全局旋转,和全局缩放,当然真值也会随之移动
gt_bboxes, points = self.augmentor.random_flip(gt_bboxes, points)
gt_bboxes, points = self.augmentor.global_rotation(gt_bboxes, points)
gt_bboxes, points = self.augmentor.global_scaling(gt_bboxes, points)
在SA-SSD的推断阶段,对输出3d框做非极大值抑制(NMS)。这段代码在基类SingleStageDetector的前向计算中:
# extra_head 的输出
bbox_score, guided_anchors = self.extra_head(conv6, guided_anchors, is_test=True)
# 在 get_rescore_bboxes 中使用了 NMS
# 输入 guided_anchors (粗糙3d框预测结果), bbox_score (粗糙目标类别结果)
# 输出 det_bboxes(NMS后的3d框预测结果), det_scores(NMS后的目标类别结果)
det_bboxes, det_scores = self.extra_head.get_rescore_bboxes(
guided_anchors, bbox_score, img_meta, self.test_cfg.extra)
# 输出 SA-SSD 的 3D 目标检测结果
results = [kitti_bbox2results(*param) for param in zip(det_bboxes, det_scores, img_meta)]
6. 结束语
SA-SSD的代码阶段工作到这里就告一段落了。一路走来,我自顶向下分析了SA-SSD的代码框架。还是有一些细节不弄清楚。相当多的函数看着很迷。更多的细节还要在实践中掌握呀。