图文详细讲解·jvm垃圾回收全过程及垃圾回收算法
垃圾回收
- 什么是垃圾
- 如何定位垃圾
- (1)引用计数
- (2)根可达算法
- 常见垃圾回收算法
- 标记清除(mark-sweap)
- 拷贝(copy)
- 标记压缩(mark-compact)
- jvm分代模型(仅用于分代垃圾回收算法)
- 堆内存逻辑分区
- 常见垃圾回收器
- serial
- serial old
- Parallel Scavenge
- Parallel Old
- parNew
- CMS
- todo G1 ZGC
#小白话
什么是垃圾
没有引用指向的任何对象
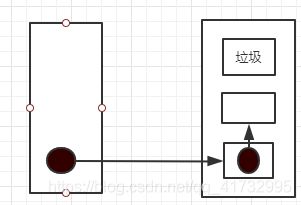
如何定位垃圾
(1)引用计数
每个对象有一个引用计数属性,新增一个引用时计数加1,引用释放时计数减1。(注:无法解决循环引用问题)
Object objectA = new Object();
Object objectB = new Object();
objectA.instance = objectB;
objectB.instance = objectA;
objectA = null;
objectB = null;
程序启动后,objectA和objectB两个对象被创建并在堆中分配内存,它们都相互持有对方的引用,但是除了它们相互持有的引用之外,再无别的引用。而实际上,引用已经被置空,这两个对象不可能再被访问了,但是因为它们相互引用着对方,导致它们的引用计数都不为0,因此引用计数算法无法通知GC回收它们,造成了内存的浪费.
(2)根可达算法
概念:通过根对象(下路GC roots)的进行引用搜索,最终可以到达的对象为可达对象,可达对象即为存在引用的对象,反之,则为不可达对象。
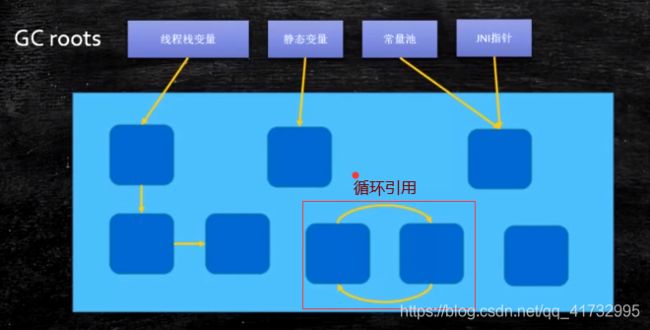
``
常见垃圾回收算法
标记清除(mark-sweap)
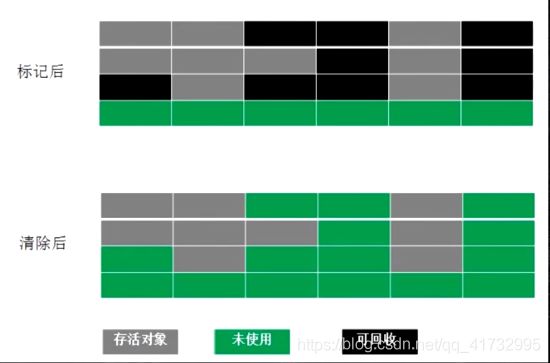
特点:
算法简单,存活对象比较高的时候效率高(从根遍历的存活对象比较多,需要清理的对象比较少)------不适合Eden区的清理,伊甸区的存活对象比较少。
问题:
1-两遍扫描,效率偏低(第一次扫描标记不可回收对象–根可达标记为存活对象,第二遍清除没有被标记的对象)
2-容易产生碎片(清理出来的内存空间不是连续的)
拷贝(copy)

做法:将内存分为两块,每次只使用一块,GC时,将正在使用的内存中的存活对象复制到另一块存储空间中,然后清除正在使用的空间的所有对象

缺点:空间浪费,移动复制对象,需要调整对象引用
总结:使用于存活对象较少的情况,只扫描一次,效率提高了,没有碎片了,------适合Eden区。
标记压缩(mark-compact)

做法:先标记所有的根可达对象(存在引用的对象),不同的是,标记完成后并不是直接清除未标记的垃圾对象,而是将所有的被标记的对象(即存活对象)压缩到内存空间的一端后在清理边界外所有的空间。
特点:扫描两次(第一次标记索引根可达对象,第二遍移动),需要移动对象,
优点:不会产生碎片,方便内存分配,不会内存减半
jvm分代模型(仅用于分代垃圾回收算法)
ZGC Shenandoah这些不适用分代模型。
G1是逻辑分代,物理不分代(垃圾回收器种类见下节)
除此之外不仅逻辑分代,而且物理分代
堆内存逻辑分区

这里需要补一点运行时数据区的知识:https://blog.csdn.net/u010488116/article/details/79800142
如图:1、年轻代中分为一个Eden区和两个Surviver区,比例为8:1:1,两个Surviver区分别称为“From”区和“To”区。对象在Eden区创建,经过一次Yong GC后,还存活的对象将会被复制到Surviver区的“From”区,此时“To”区是空的。到了下一次GC的时候,Eden区还存活的对象会直接移动到Surviver区的“To”区,而“Form”区的对象有两个去处,“From”区的对象会根据经过的GC次数计算年龄,如果年龄到达了阈值(默认15),则会被移动到老年代中,否则就复制到“To”区,此时“From”区变成了空的,然后“From”区和“To”区进行角色互换,到下一次进行GC时,还是有一块空的“To”区,用来存放从eden区和“From”区移动过来的对象。(注意from和to第一次gc后不到年龄的对象会来回在from和to互换)
YGC/minor gc :年轻代空间耗尽时
Major GC/Full GC:老年代无法分配空间时触发,新生代,老年代同时进行回收
·一个对象分配过程

注意:
并不是所有new出来的对象都是分配在堆上的。不在堆上分配的特殊情况:TLAB和栈上分配。
为什么?
我们知道堆是由所有线程共享的,既然如此那它就是竞争资源,对于竞争资源,必须采取必要的同步,所以当使用new关键字在堆上分配对象时,是需要锁的。既然有锁,就必定存在锁带来的开销,而且由于是对整个堆加锁,相对而言锁的粒度还是比较大的,当对象频繁分配时,不免影响效率。
所以对于某些特殊情况,可以采取避免在堆上分配对象的办法,以提高对象创建和销毁的效率。
哪些new的对象分配在栈上?
·栈上分配
–线程私有小对象
–无逃逸(只在某段代码使用)eg:一个对象的方法里面就一句new Object(),没有任何引用指向它),如果有外部引用指向它就会有逃逸。
–支持标量替换 eg 一个对象里面只有 int a, int b,使用普通类型直接代替对象
·线程本地分配(Thread-local allocation buffer)
–占用eden,默认1%
多线程的时候不用竞争eden就可以申请空间,(eden区,多线程情况都想往一个地址分配对象,效率会降低)提高效率
小对象
常见垃圾回收器
serial

STW:在执行垃圾收集算法时,Java应用程序的其他所有线程都被挂起(只有gc线程工作)
缺点:stw时间太长,停顿时间太长,内存空间太大导致清理时间会变长。(以前是扫屋子,现在扫整个省)
serial old

使用mark sweap 或mark compact算法,也是单线程
Parallel Scavenge

多GC线程处理垃圾(就是喊些小弟和你一起扫大街,行人都给我旁边捎着去)
Parallel Old

使用多线程mark compact算法的垃圾回收器
parNew
它实际是Serial GC的多线程版本

PS 和 PN区别的延伸阅读: ▪https://docs.oracle.com/en/java/javase/13/gctuning/ergonomics.html#GUID-3D0BB91E-9BFF-4EBB-B523-14493A860E73
CMS

垃圾回收线程和工作线程同时进行。(一边扔垃圾一边捡垃圾),因无法忍受stw产生。
cmsGC标记有七个阶段,主要了解上图四个阶段
初始化标记阶段:,也是标记阶段的开始。主要工作是 标记可直达的存活对象 。(注:第一阶段只标记了老年代最根上的对象)

并发标记:通过遍历第一个阶段(Initial Mark)标记出来的存活对象,继续递归遍历老年代,并标记可直接或间接到达的所有老年代存活对象

重新标记:在并发标记的期间又重新产生的垃圾,停止工作线程,新产生的垃圾不多,因此stw时间很短。
并发清理:在清理的过程中产生的垃圾称为浮动垃圾,下一次cms清理过程清理
缺点:CMS 和 serial old配合使用
(老年代碎片划严重,老年代满了的时候,使用serial old – 单线程老奶奶进行清理,32g内存清理太慢了)解决方案:降低触发cms阈值。
问题:
内存碎片话(使用的是mark sweap)
产生浮动垃圾