MIT 6.824 Lab 1: MapReduce 笔记
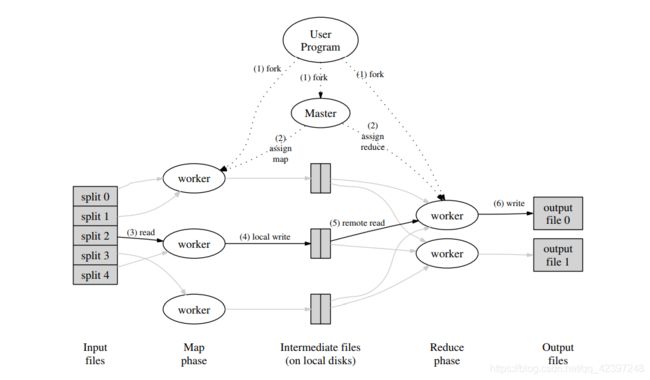
从图中可以看出,map将输入映射成若干个中间文件,这些文件在reduce中被处理之后合并成一个输出文件
序言
- 应用提供一些输入文件,一个map函数,一个reduce函数,还有reduce任务的数量
nReduce - master在接受这些信息后创建,它启动一个RPC服务器
// startRPCServer starts the Master's RPC server. It continues accepting RPC
// calls (Register in particular) for as long as the worker is alive.
func (mr *Master) startRPCServer() {
rpcs := rpc.NewServer()
rpcs.Register(mr)
os.Remove(mr.address) // only needed for "unix"
l, e := net.Listen("unix", mr.address)
if e != nil {
log.Fatal("RegstrationServer", mr.address, " error: ", e)
}
mr.l = l
// now that we are listening on the master address, can fork off
// accepting connections to another thread.
go func() {
loop:
for {
select {
case <-mr.shutdown:
break loop
default:
}
conn, err := mr.l.Accept()
if err == nil {
go func() {
rpcs.ServeConn(conn)
conn.Close()
}()
} else {
debug("RegistrationServer: accept error, %v", err)
break
}
}
debug("RegistrationServer: done\n")
}()
}
等待workers来注册
// Register is an RPC method that is called by workers after they have started
// up to report that they are ready to receive tasks.
func (mr *Master) Register(args *RegisterArgs, _ *struct{}) error {
mr.Lock()
defer mr.Unlock()
debug("Register: worker %s\n", args.Worker)
mr.workers = append(mr.workers, args.Worker)
// tell forwardRegistrations() that there's a new workers[] entry.
mr.newCond.Broadcast()
return nil
}
当任务可用时,schedule()决定如何将这些任务分发给workers,还有如何处理workers宕机问题
- master将每个输入文件作为一个map任务,每个map任务调用
doMap()至少一次。可以串行
// Sequential runs map and reduce tasks sequentially, waiting for each task to
// complete before running the next.
func Sequential(jobName string, files []string, nreduce int,
mapF func(string, string) []KeyValue,
reduceF func(string, []string) string,
) (mr *Master) {
mr = newMaster("master")
go mr.run(jobName, files, nreduce, func(phase jobPhase) {
switch phase {
case mapPhase:
for i, f := range mr.files {
doMap(mr.jobName, i, f, mr.nReduce, mapF)
}
case reducePhase:
for i := 0; i < mr.nReduce; i++ {
doReduce(mr.jobName, i, mergeName(mr.jobName, i), len(mr.files), reduceF)
}
}
}, func() {
mr.stats = []int{len(files) + nreduce}
})
return
}
或者利用RPC调用将任务分发给每个worker并行执行
// DoTask is called by the master when a new task is being scheduled on this
// worker.
func (wk *Worker) DoTask(arg *DoTaskArgs, _ *struct{}) error {
fmt.Printf("%s: given %v task #%d on file %s (nios: %d)\n",
wk.name, arg.Phase, arg.TaskNumber, arg.File, arg.NumOtherPhase)
wk.Lock()
wk.nTasks += 1
wk.concurrent += 1
nc := wk.concurrent
wk.Unlock()
if nc > 1 {
// schedule() should never issue more than one RPC at a
// time to a given worker.
log.Fatal("Worker.DoTask: more than one DoTask sent concurrently to a single worker\n")
}
pause := false
if wk.parallelism != nil {
wk.parallelism.mu.Lock()
wk.parallelism.now += 1
if wk.parallelism.now > wk.parallelism.max {
wk.parallelism.max = wk.parallelism.now
}
if wk.parallelism.max < 2 {
pause = true
}
wk.parallelism.mu.Unlock()
}
if pause {
// give other workers a chance to prove that
// they are executing in parallel.
time.Sleep(time.Second)
}
switch arg.Phase {
case mapPhase:
doMap(arg.JobName, arg.TaskNumber, arg.File, arg.NumOtherPhase, wk.Map)
case reducePhase:
doReduce(arg.JobName, arg.TaskNumber, mergeName(arg.JobName, arg.TaskNumber), arg.NumOtherPhase, wk.Reduce)
}
wk.Lock()
wk.concurrent -= 1
wk.Unlock()
if wk.parallelism != nil {
wk.parallelism.mu.Lock()
wk.parallelism.now -= 1
wk.parallelism.mu.Unlock()
}
fmt.Printf("%s: %v task #%d done\n", wk.name, arg.Phase, arg.TaskNumber)
return nil
}
每次doMap()调用都会读取适当的文件,对其内容进行用户指定的map函数处理,将返回的key/value结果写入nReduce个中间文件。在这里实验用哈希取模来选择读入哪个reduce任务要处理的文件。
- master接下来为每个reduce任务调用
doReduce()至少一次,串行或并行执行。从相对应的中间文件里读取内容并为每个key调用reduce函数,并产生nReduce个结果文件 - master调用
mr.merge()
// merge combines the results of the many reduce jobs into a single output file
// XXX use merge sort
func (mr *Master) merge() {
debug("Merge phase")
kvs := make(map[string]string)
for i := 0; i < mr.nReduce; i++ {
p := mergeName(mr.jobName, i)
fmt.Printf("Merge: read %s\n", p)
file, err := os.Open(p)
if err != nil {
log.Fatal("Merge: ", err)
}
dec := json.NewDecoder(file)
for {
var kv KeyValue
err = dec.Decode(&kv)
if err != nil {
break
}
kvs[kv.Key] = kv.Value
}
file.Close()
}
var keys []string
for k := range kvs {
keys = append(keys, k)
}
sort.Strings(keys)
file, err := os.Create("mrtmp." + mr.jobName)
if err != nil {
log.Fatal("Merge: create ", err)
}
w := bufio.NewWriter(file)
for _, k := range keys {
fmt.Fprintf(w, "%s: %s\n", k, kvs[k])
}
w.Flush()
file.Close()
}
合并这些结果文件为一个输出文件
- master对每个worker发送关闭请求,之后关闭RPC服务器
Part Ⅰ:Map/Reduce input and output
- 这部分根据注释提示实现
doMap()和doReduce()函数,主要是对golang语法的熟悉 doMap()函数读取输入文件,对文件内容进行map函数处理,通过ihash(kv.Key) % nReduce获取r(哈希取模),并将其写入到nReduce个中间文件里
func doMap(
jobName string, // the name of the MapReduce job
mapTask int, // which map task this is
inFile string,
nReduce int, // the number of reduce task that will be run ("R" in the paper)
mapF func(filename string, contents string) []KeyValue,
) {
content, err1 := ioutil.ReadFile(inFile)
if (err1 != nil) {
log.Fatal("check...", err1)
}
KV := mapF(inFile, string(content[:]))
for i := 0; i < nReduce; i ++{
filename := reduceName(jobName, mapTask, i)
reduceFile, err2 := os.Create(filename)
if (err2 != nil) {
log.Fatal("check...", err2)
}
defer reduceFile.Close()
enc := json.NewEncoder(reduceFile)
for _, kv := range KV{
if (ihash(kv.Key) % nReduce == i) {
err3 := enc.Encode(&kv)
if (err3 != nil) {
log.Fatal("check...", err3)
}
}
}
}
}
doReduce()读取nMap个中间文件,对key进行排序后对每个key对应的所有values做reduce函数处理,并将结果作为value和key一起写入到一个结果文件里
func doReduce(
jobName string, // the name of the whole MapReduce job
reduceTask int, // which reduce task this is
outFile string, // write the output here
nMap int, // the number of map tasks that were run ("M" in the paper)
reduceF func(key string, values []string) string,
) {
KV := make(map[string][] string, 0)
for i := 0; i < nMap; i++ {
reduceFile, err1 := os.Open(reduceName(jobName, i, reduceTask))
if (err1 != nil) {
log.Fatal("check...", err1)
}
defer reduceFile.Close()
dec := json.NewDecoder(reduceFile)
for {
var kv KeyValue
err2 := dec.Decode(&kv)
if (err2 != nil) {
break
}
_, ok := KV[kv.Key]
if (!ok) {
KV[kv.Key] = make([]string, 0)
}
KV[kv.Key] = append(KV[kv.Key], kv.Value)
}
}
var keys []string
for k, _ := range KV {
keys = append(keys, k)
}
sort.Strings(keys)
mergeName := mergeName(jobName, reduceTask)
mergeFile, err3 := os.Create(mergeName)
if (err3 != nil) {
log.Fatal("check...", err3)
}
defer mergeFile.Close()
enc := json.NewEncoder(mergeFile)
for _, k := range keys {
err := enc.Encode(KeyValue{k, reduceF(k, KV[k])})
if (err != nil) {
log.Fatal("check...", err)
}
}
}
Part Ⅱ:Single-worker word count
- 这部分根据论文里的描述写一个wordcount程序,map将输入里的单词作为key,"1"即出现次数作为value,返回一个key/value数组;reduce函数将key对应所有value值加起来,即统计每个单词出现次数,最后串行执行
func mapF(filename string, contents string) []mapreduce.KeyValue {
// Your code here (Part II).
KV := make([]mapreduce.KeyValue, 0)
words := strings.FieldsFunc(contents, func(r rune) bool {
if r == ' ' || !unicode.IsLetter(r) {
return true
}
return false
})
for _, w := range words {
KV = append(KV, mapreduce.KeyValue{w, "1"})
}
return KV
}
func reduceF(key string, values []string) string {
// Your code here (Part II).
var total int = 0
for _, cnt := range values {
c, _ := strconv.Atoi(cnt)
total += c
}
return strconv.Itoa(total)
}
PartⅢ:Distributing MapReduce tasks
- 这部分需要实现
schedule()函数,在master里会调用这个函数两次,一次map,一次reduce,这个函数的功能是分发任务给每个worker,分发方式是通过RPC调用Worker.DoTask,参数中的registerChan为传递worker地址的信道,我的方法是利用这个信道,配合sync.WaitGroup计数器,在goroutine执行前从信道取出,RPC调用执行完成后再将这个worker放入信道里,并将计数器值减一,计数器值到0后表示任务完成,函数退出
func schedule(jobName string, mapFiles []string, nReduce int, phase jobPhase, registerChan chan string) {
var ntasks int
var n_other int // number of inputs (for reduce) or outputs (for map)
switch phase {
case mapPhase:
ntasks = len(mapFiles)
n_other = nReduce
case reducePhase:
ntasks = nReduce
n_other = len(mapFiles)
}
fmt.Printf("Schedule: %v %v tasks (%d I/Os)\n", ntasks, phase, n_other)
wg := sync.WaitGroup{}
wg.Add(ntasks)
args := new(DoTaskArgs)
args.JobName = jobName
args.Phase = phase
args.NumOtherPhase = n_other
for i := 0; i < ntasks; i++ {
fmt.Printf("task %d start\n", i)
wk := <-registerChan
go func(i int) {
args.TaskNumber = i
if (phase == mapPhase) {
args.File = mapFiles[args.TaskNumber]
}
fmt.Printf("before given task %d\n", args.TaskNumber)
call(wk, "Worker.DoTask", args, nil)
wg.Done()
fmt.Printf("wg.Done%d\n", args.TaskNumber)
registerChan <- wk
fmt.Printf("register %s\n", wk)
}(i)
}
wg.Wait()
fmt.Printf("Schedule: %v done\n", phase)
}
PartⅣ:Handling worker failures
- 这部分处理worker宕机问题,若某一worker宕机就让另一worker处理宕机worker之前处理的任务,实验里
call()返回false表示worker宕机,利用这点对schedule()进行修改:
go func(i int){
for {
fmt.Printf("task %d start\n", i)
args.TaskNumber = i
if (phase == mapPhase) {
args.File = mapFiles[args.TaskNumber]
}
fmt.Printf("before given task %d\n", args.TaskNumber)
ok := call(wk, "Worker.DoTask", args, nil)
if ok {
wg.Done()
fmt.Printf("wg.Done%d\n", args.TaskNumber)
registerChan <- wk
fmt.Printf("register %s\n", wk)
return
} else {
fmt.Printf("worker %s fail\n", wk)
wk = <-registerChan
}
}
}(i)
PartⅤ:Inverted index generation
- 这部分实现反向索引工具,对文档中单词建立一个文档索引,根据单词查找对应文档
mapF()读取文档中所有不重复单词,返回key为每个单词,value为这个文档名字的切片数组reduceF()对单词对应所有文档排序,之后输出所有文档名组成的字符串
func mapF(document string, value string) (res []mapreduce.KeyValue) {
// Your code here (Part V).
KV := make([]mapreduce.KeyValue, 0)
contains := make(map[string] string, 0)
content, err := ioutil.ReadFile(document)
if err != nil {
log.Fatal("Read Inverted Index File Error:", err)
}
words := strings.FieldsFunc(string(content), func(r rune) bool {
if r == ' ' || !unicode.IsLetter(r) {
return true
}
return false
})
for _, w := range words {
_, ok := contains[w]
if !ok {
KV = append(KV, mapreduce.KeyValue{w, document})
contains[w] = document
}
}
return KV
}
func reduceF(key string, values []string) string {
// Your code here (Part V).
res := strconv.Itoa(len(values)) + " "
sort.Strings(values)
for i := 0; i < len(values)-1; i++ {
res += values[i] + ","
}
res += values[len(values)-1]
return res
}
第一部分完成,花了一个星期,这星期还要复习期考,求不挂科