pycaret快速上手
在前段时间里面,我觉得使用sklearn进行机器学习以及足够方便了.方便的离谱的那种,时常会觉得自己用sklearn有点水,直到我今天尝试了pycaret,我才明白啥叫懒惰推进人类发展.pycaret更是方便的离谱.
安装方式
pip install pycaret
(由于要装挺多依赖的,所以可能有点慢,如果安装的时候报错了,多安几次就好)
官方的教程,jupyter notebook形式的
from pycaret.classification import *
from pycaret.datasets import get_data
第一行把分类相关的函数导入,如果是回归就regression聚类就cluster等.
第二个这里主要是使用内置的数据集,也可以用panda读取.
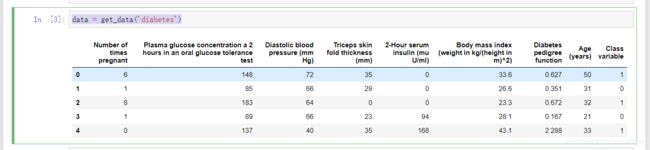
data = get_data('diabetes')
获取内置的糖尿病数据集
setup(data=data,target='Class variable')
这步其实就是喂数据,data就是获取的数据,target就是标签的列名,这里是Class variable.如果用pandas读取自己的数据集时,label和data一起放就不说了.如果data和label分开放了,可以用panda分别读出来以后,再用pd.concat()合并到一起.
x = pd.read_csv(r'')
y_ = pd.read_csv(r'')
y_ = y_['label']
all_add = pd.concat([x,y_],axis=1)

喂进去以后,骚气的来了…自动提取特征+自动填补缺失值…
compare_models()
载入数据后,就可以为所欲为了,比如上面这个的意思是,用所有的模型尝试一下数据,然后显示相关模型的表现,方便选择模型.

catboost = create_model('catboost')
如果想创建一个模型,也很简单,就上面一行代码就够了.输入模型的简称就ok.如果想查看简称的话,简称就在creat_model方法的描述里
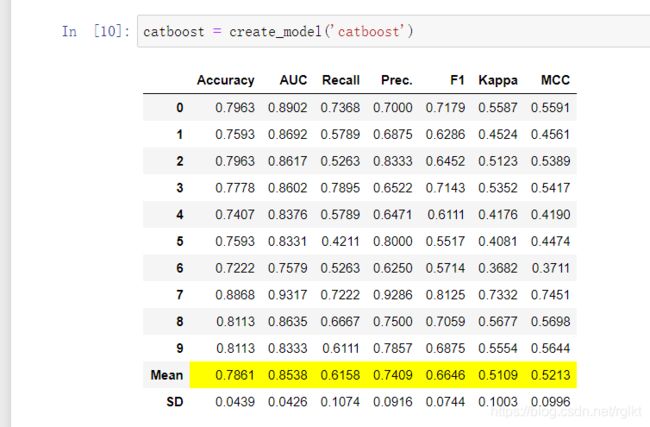
上面的代码运行后就自动训练模型了,目测应该是十折交叉验证
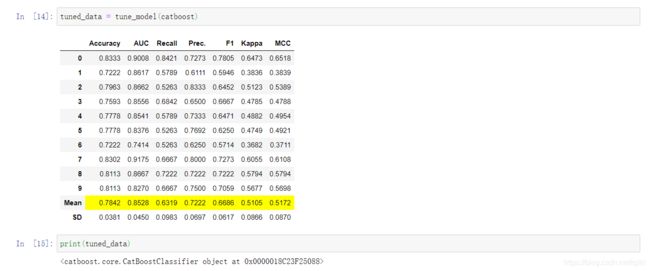
tuned_data = tune_model(catboost)
print(tuned_data)
模型调参.以及调参后参数的展示
这里可能是catboost比较特别…展现不出来,补一张官网的图.我的感受是比较复杂高级点的算法都有点特别…

plot_model(tuned_data)
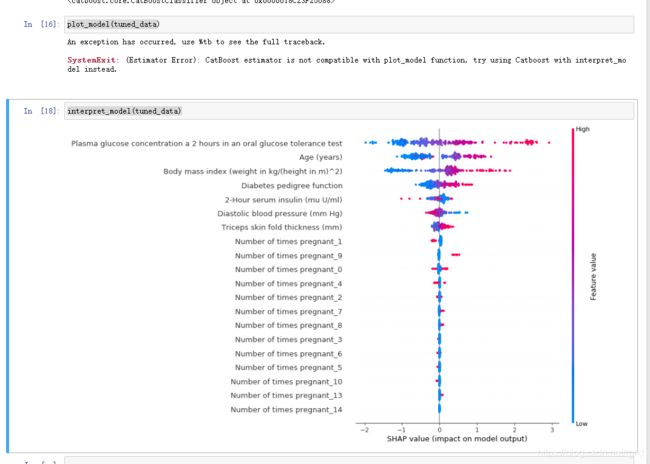
interpret_model(tuned_data)
模型展示和模型解释…我用的感觉就是,高级的的用解释,低级的算法就可以展示.一张我的,一张官网的

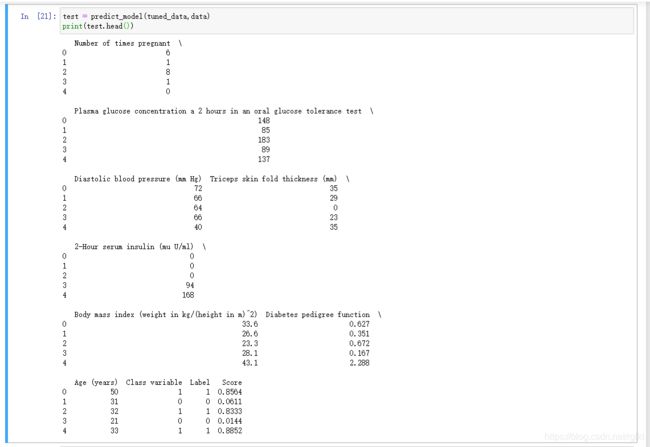
test = predict_model(tuned_data,data)
print(test.head())
训练好后的模型拿去预测
还有保存/载入模型,就不说了,官网都有
总的来说…基本每一步都只用一行代码…恐怖如斯…