CCIPCA:直观协方差无关增量式主成分分析算法
CCIPCA是由密西根州立大学翁巨扬教授于2003年,在TPAMI上发表的论文,与传统的主成分分析(PCA)不同,CCIPCA在一个样本集的主成分过程中,不需要对样本的协方差矩阵进行评估,因此,存在Covariance-free这个特性。
一、PCA(主成分分析)
我们回顾一下PCA算法:
PCA算法对样本序列进行降维的原理,按照Pattern Reccognition And Maching Learning第十二章中定义有:"PCA can be defined as the orthogonal prejection of the data onto a lower dimentional linear space, known as the pricipal subspace, such that the variance of the projected data is maximized",翻译过来就是:将数据正交化投影到一个低维线性空间(主成分空间),使得投影后的数据方差最大。
假定,现有一个数据集 首先,考虑将数据投影到一个一维的空间,我们采用一个D维的向量 其中S为数据集的方差矩阵: 现在问题就转换成求 极大值和极小值应该位于导数为0的位置,因此,将f对 两边再同时乘以 可以看到,投影后数据的方差等于 二、CCIPCA算法推导 假设,我们顺序的获取一个样本序列:u(1),u(2),...。每一个u(k),k= 1, 2, 3, .....为一个d维向量,然后将前n个样本减去均值,计算其协方差矩阵: 其中, 这里,最关键的步骤来了,PCA在计算特征值和特征向量时,样本集是已知的,也即是数据集中的所有样本都已知,计算过程直接就是求取样本集协方差矩阵的特征值和特征向量,这里需要计算协方差矩阵,计算量较大,同时,在实际应用场景中,数据序列的获取是序列的,比如,摄像头获取图片,也是一帧一帧获取的,完整数据集是无法得到的。 因此,CCIPCA 采用了一种不计算协方差矩阵的方式,逐个样本对数据集的均值和特征向量进行更新,当前特征值计算是对特征值上一个状态的进一步评估: 其中 具体流程如下: 下面就是采用CCIPCA对yale库提取63个最判别特征向量的提取效果如图1所示。 图1 CCIPCA算法 C++版本的代码就不贴了,这里我贴一下我用python写的部分关键代码: 对Mninst数据集提取20个特征向量,效果如图2所示。 图2 CCIPCA 对Mnist数据集提取前20个最判别特征向量 如果有需要完整代码的,请留言,哈哈哈哈~~~~~ 三、IBDPCA算法 图3 IBDPCA算法工作原理示意图(摘自文献[3]) IBDPCA算法相当于就是将图像每一行和每一列都视为一个单独的数据,然后进行CCIPCA,提取K个最判别特征向量。这样,IBDPCA在提取到最判别特征分量之后,计算n个样本X在特征分量上投影。 python源码已经上传github: https://github.com/1976277169/CCIPCA/tree/master 未完待续~~~ 参考文献: [1] Abramson N, Braverman D, Sebestyen G. Pattern Recognition and Machine Learning[M]. Springer, 2006. [2] Weng J, Zhang Y, Hwang W S. Candid covariance-free incremental principal component analysis[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2003, 25(8):1034-1040. [3] 王肖锋, 张明路, 刘军. 基于增量式双向主成分分析的机器人感知学习方法研究, 2017年11月27日[J]. 电子与信息学报, 2018, 40(3):618-625. ![]() ,每个数据的维度为D。我们的目标是将数据投影到一个只有M(
,每个数据的维度为D。我们的目标是将数据投影到一个只有M( 来表示投影后子空间的方向,由于我们仅仅对所代表方向感兴趣,所以将的模长设置为1,即
来表示投影后子空间的方向,由于我们仅仅对所代表方向感兴趣,所以将的模长设置为1,即![]() ,这样,将数据集中所有数据投影到上之后,数据集的方差为:
,这样,将数据集中所有数据投影到上之后,数据集的方差为:![]()
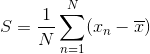
![]() 条件下,
条件下,![]() 的最大值,这里引入拉格朗日乘子:
的最大值,这里引入拉格朗日乘子:![]() 求偏导,并令其等于0得到:
求偏导,并令其等于0得到:![]()
![]() 有:
有:![]()
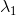 ,也即是,如果为方差矩阵最大特征值对应的特征向量,投影后的方差也最大,因此PCA算法计算,也即是计算样本方差矩阵的特征值及对应特征向量。
,也即是,如果为方差矩阵最大特征值对应的特征向量,投影后的方差也最大,因此PCA算法计算,也即是计算样本方差矩阵的特征值及对应特征向量。 
![]() 为样本减去均值后的残差量,按照PCA计算过程有:
为样本减去均值后的残差量,按照PCA计算过程有:![]()
 为
为![]() 的特征值,
的特征值, 为对应特征向量,如果假定特征向量的模长近似等于特征值 大小,有:
为对应特征向量,如果假定特征向量的模长近似等于特征值 大小,有:![]()
![]()
![]()
 为遗忘方程,第二个式子理解过程可以参考一下Gram-Schimdt方法,相当于是剔除当前残差量在前一个特征向量上的投影量,相当于是去除掉当前残差量与当前特征向量之间的关联,这样,就降低了特征向量之间关联,使得特征向量间彼此正交,CCIPCA算法的目的是找到最判别的前k个特征向量,进而实现对数据的降维处理。
为遗忘方程,第二个式子理解过程可以参考一下Gram-Schimdt方法,相当于是剔除当前残差量在前一个特征向量上的投影量,相当于是去除掉当前残差量与当前特征向量之间的关联,这样,就降低了特征向量之间关联,使得特征向量间彼此正交,CCIPCA算法的目的是找到最判别的前k个特征向量,进而实现对数据的降维处理。

def update(self, x):
assert(x.shape[0] == 1)
# compute the mean imcrementally
self._mean = float(self._n - 1) / self._n * self._mean + float(1) / self._n * x
if self._n > 1:
u = x - self._mean # reduce the mean vector
[w1, w2] = self._amnestic(self._n) # conpute the amnestic parameters
k = min(self._n, self._output_dim)
for i in range(k): # update all eigenVectors
v = self._eigenVectors[i,:].copy() # get the current eigenVector
if(i == k - 1):
v = u.copy()
vn = v / np.linalg.norm(v) # normalize the vector
else:
v = w1 * v + w2 * np.dot(u, v.T)/ np.linalg.norm(v) * u # update the eigenVector
vn = v / np.linalg.norm(v) # normalize the vector
u = u - np.dot(u, vn.T) * vn # remove the projection of u on the v
self._eigenVectors[i,:] = v.copy()
self._n += 1 # update the mean of the data 
