深度之眼Pytorch打卡(二):Pytorch张量与张量的创建
前言
张量既是Pytorch中的一种基本数据结构,表示多维数组,也是一种自动求梯度的方式。本笔记框架主要来源于深度之眼,并作了一些相关的拓展。内容包括:张量的含义,0维,1维,2维,3维,4维,5维张量的形状;张量的若干参数和自动求梯度的方法;张量的若干常用创建方法。
Pytorch张量
在各种深度学习框架中,张量(tensor)一般是被定义成多维数组,目的是把向量、矩阵推向更高的维度。张量在Pytorch中,既是基本数据结构,也是自动求梯度的工具。
- 张量(tensor)
标量,向量,矩阵等都是张量。其中标量是0维张量,向量是1维张量,矩阵是2维张量。我们通常见到的灰度图像是2维张量,彩色图像是3维张量。由若干三维张量可以构成4维张量,若干4维张量可以构成5维张量,以此类推。如下图所示(改画自博客,这篇博客系统的介绍了张量的各种含义)
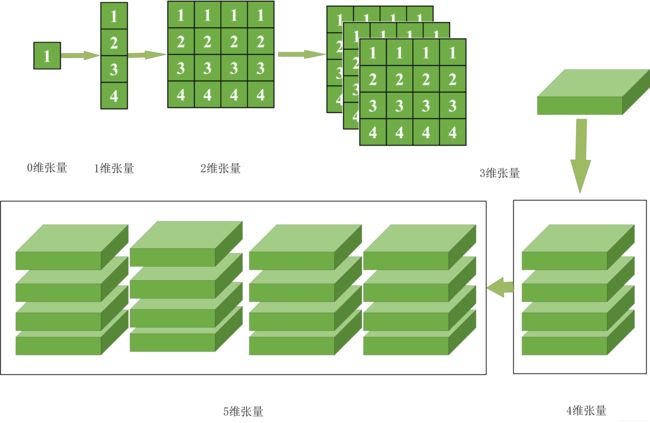
- Variable
Variable是 torch.autograd中的数据类型,主要用于封装 Tensor,便于进行自动求导。在Pytorch0.4.0及其之后的版本中,Variable被并入了Tensor里。torch.autograd.Variable包含以下5个属性:
data:用于存放tensor,是数据本体。
grad:data的梯度值。
grad_fn:记录创建张量时所用的方法(函数——乘法:grad_fn = 加法:grad_fn = ),用于反向传播的梯度计算之用。grad_fn指向创建Tensor的函数,如果某一个Tensor是由用户创建的,则指向:None。
requires_grad:指示是否需要梯度,对于需要求导的tensor,其requires_grad属性必须为True,即:requires = Ture.自己定义的tensor的requires_grad属性默认为False,神经网络层中的权值w的tensor的requires_grad属性默认为True。
is_ leaf : 指示是否是叶子结点(张量),用户创建的结点称为叶子结点(张量),如X 与 W。is_leaf 为False,即:is_leaf = Ture,的时候,则不是叶子节点,,is_leaf为True的时候是叶子节点。叶子节点在经过反向传播之后梯度值能够得以保留,非叶子节点的梯度值则为:None。
- Pytorch张量
前面已经提到,Pytorch0.4.0及其之后的版本中,Tensor已经包含Variable的内容,所以它理应包含Variable的所有属性。Pytorch张量一共有如下图所示的8个属性,其中5个如上,剩余3个如下:

dtype:张量的数据类型,分成浮点,整型和布尔三大类,共9种数据类型,如下表所示(引自pytorch官网),其中32位浮点和64位整型最为常用。图像预处理结果默认:torch.float32,图像标签默认:torch.int64.
| 数据类型 |
dtype |
CPU张量 |
GPU张量 |
|---|---|---|---|
| 32位浮点 |
|
|
|
| 64位浮点 |
|
|
|
| 16位浮点 |
|
|
|
| 8位整数(无符号) |
|
|
|
| 8位整数(有符号) |
|
|
|
| 16位整数(有符号) |
|
|
|
| 32位整数(有符号) |
|
|
|
| 64位整数(有符号) |
|
|
|
| 布尔型 |
|
|
|
shape : 张量的形状。如(32,3,448,448)就是一个32*3*448*448的4维张量,相当于32张448*448的RGB图像,堆积方式可以通过上述张量的示意图推出。
device : 张量所在设备,GPU 或CPU,张量在GPU上才能用其加速。
常用的Pytorch张量创建方式
-
★torch.tensor()
torch.tensor(data, dtype=None, device=None, requires_grad=False, pin_memory=False) data:张量的初始数据。可以是列表,元组,NumPy的n维数组(ndarray),标量和其他类型。
dtype:返回张量的数据类型,默认值:None,表示与data数据类型一致。
device:返回张量的所需设备。默认值:None,表示使用当前设备。若是CPU张量,则设备是当前CPU,若是cuda张量,则设备是当前GPU。
requires_grad:是否需要计算梯度,默认False。
pin_memory:返回的张量是否在固定内存中分配,仅适用于CPU张量,涉及效率问题。默认值:False。
代码:
# 输入列表,数据类型是int64
a = [[1, 2, 3, 4], [1, 2, 3, 4], [1, 2, 3, 4], [1, 2, 3, 4]]
t = torch.tensor(a)
print(t, '\n', t.dtype)结果:
tensor([[1, 2, 3, 4],
[1, 2, 3, 4],
[1, 2, 3, 4],
[1, 2, 3, 4]])
torch.int64代码:
# 输入列表,数据类型是float32
a = [[1.2, 2, 3, 4], [1, 2, 3, 4], [1, 2, 3, 4], [1, 2, 3, 4]]
t = torch.tensor(a)
print(t, '\n', t.dtype)结果:
tensor([[1.2000, 2.0000, 3.0000, 4.0000],
[1.0000, 2.0000, 3.0000, 4.0000],
[1.0000, 2.0000, 3.0000, 4.0000],
[1.0000, 2.0000, 3.0000, 4.0000]])
torch.float32代码:
# 输入一个浮点数
a = 3.1415926535
t = torch.tensor(a, dtype=torch.int64)
print(t, '\n', t.dtype)结果:
tensor(3)
torch.int64代码:
# 输入一个浮点数,设备选择cuda,由于要从cpu先转换到GPU,所以结果输出较慢
a = 3.1415926535
t = torch.tensor(a, dtype=torch.float64, device='cuda')
print(t, '\n', t.dtype)结果: 根据cuda编号可以选择不同的GPU
tensor(3.1416, device='cuda:0', dtype=torch.float64)
torch.float64-
torch.from_numpy()
torch.from_numpy(ndarray) torch.from_numpy(ndarray)返回的张量和ndarray共享相同的内存,即:对张量的修改将反映在ndarray上,反之亦然。且返回的张量不可调整大小。目前,该函数接受dtypes为numpy.float64, numpy.float32,numpy.float16,numpy.int64,numpy.int32, numpy.int16,numpy.int8,numpy.uint8,和numpy.bool,的ndarray。
代码:
a = np.array([1, 2, 3, 4])
t = torch.from_numpy(a)
print(t)
t[0] = 10
print('modify t print a:', a)
a[3] = -5
print('modify a print t:', t)结果:印证了共享内存
tensor([1, 2, 3, 4], dtype=torch.int32)
modify t print a: [10 2 3 4]
modify a print t: tensor([10, 2, 3, -5], dtype=torch.int32)-
★torch.zeros()
torch.zeros(*size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)size:张量的形状,是一个整数序列,如(448,448)。
out:输出张量到out指向的地址
layout:张量在内存中的布局形式,目前支持 torch.strided(密集张量),并提供实验支持 torch.sparse_coo(稀疏COO张量),默认值:torch.strided,它也是最常用的布局形式。
代码:
out_t = torch.tensor(3.14)
t = torch.zeros(4, out=out_t)
print(t.dtype)
print('address of t:', id(t), '\n', t)
print('address of out_t:', id(out_t), '\n', out_t)结果:值与分配的内存地址均相同,是同一个数据,只是名字不同。默认数据类型,float32
torch.float32
address of t: 2377593164568
tensor([0., 0., 0., 0.])
address of out_t: 2377593164568
tensor([0., 0., 0., 0.])-
torch.zeros_like()
torch.zeros_like(input, dtype=None, layout=None, device=None, requires_grad=False)input:创建与输入张量形状相同的全0张量。
代码:
a = torch.tensor([1, 2, 3, 4])
t = torch.zeros_like(a)
print('a:', a)
print('t:', t)结果:
a: tensor([1, 2, 3, 4])
t: tensor([0, 0, 0, 0])-
★torch.ones()
torch.ones(*size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)-
torch.ones_like()
torch.ones_like(input, dtype=None, layout=None, device=None, requires_grad=False)-
★torch.empty()
torch.empty(*size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False, pin_memory=False)返回填充了未初始化数据的张量。
代码:
a = torch.empty(4, 2)
print(a)结果:
tensor([[1.3563e-19, 4.7393e+30],
[1.4312e+13, 1.7753e+28],
[1.9208e+31, 4.6114e+24],
[3.1036e+27, 7.1941e+28]])-
torch.empty_like()
torch.empty_like(input,dtype = None,layout = None,device = None,require_grad = False ) -
torch.full()
torch.full(size, fill_value, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)full_value:填充到张量的值,必须是个数。
代码:
a = torch.full((3, 3), 3.14)
print(a)结果:
tensor([[3.1400, 3.1400, 3.1400],
[3.1400, 3.1400, 3.1400],
[3.1400, 3.1400, 3.1400]])-
torch.full_like()
torch.full_like(input, fill_value, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)-
★ torch.arange()
torch.arange(start=0, end, step=1, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)返回一个大小为下式的一维等差张量

start(Number):起始值。默认值:0。
end(Number):结束值
step(Number):每对相邻点之间的间隙,即公差。默认值:1
代码:
a = torch.arange(2, 10)
print(a)
b = torch.arange(3, 10, 6)
print(b)结果:
tensor([2, 3, 4, 5, 6, 7, 8, 9])
tensor([3, 9])-
★torch.linspace()
torch.linspace(start,end,steps = 100,out = None,dtype = None,layout = torch.strided,device = None,require_grad = False )创建一个包含在start与end之间的,steps 个等距点值的一维张量。
start(python:float):起始值
end(python:float):结束值
steps(python:int)start 和 end之间要采样的点数。默认值:100
代码:
a = torch.linspace(1, 10, 8)
print(a)结果:间距为(end-start)/(steps-1)
tensor([ 1.0000, 2.2857, 3.5714, 4.8571, 6.1429, 7.4286, 8.7143, 10.0000])-
torch.logspace()
创建一个包含在![]() 与
与![]() 之间的,steps 个对数等距点值的一维张量
之间的,steps 个对数等距点值的一维张量
torch.logspace(start,end,steps = 100,base = 10.0,out = None,dtype = None,layout = torch.strided,device = None,require_grad = False ) base(python:float):–对数函数的底。默认值:10.0
代码:
a = torch.logspace(1, 10, 8)
print(a)结果:
tensor([1.0000e+01, 1.9307e+02, 3.7276e+03, 7.1969e+04, 1.3895e+06, 2.6827e+07,
5.1795e+08, 1.0000e+10])-
torch.eye()
torch.eye(n,m = None,out = None,dtype = None,layout = torch.strided,device = None,require_grad = False )创建一个2维对角张量。 若是方阵,只需要设置行数
n:行数
m:列数
代码:
a = torch.eye(3, 4)
print(a)结果:
tensor([[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.]])-
torch.seed()
用于将生成随机数的种子设置为不确定的随机数
-
★torch.normal
torch.normal(mean, std, *, generator=None, out=None)从均值为mean,标准差为std的正态分布函数中取样来形成张量。一共有四种模式:
mean为标量,std为标量:在给定mean和std决定的正态分布中取样特定个数个值形成张量,形成张量的尺寸需要指定,如形成一个(2,1,4)的张量。
代码:
a = torch.normal(2, 3, size=(2, 2, 4))
print(a)结果:
tensor([[[ 3.4884, 1.9780, -1.2065, 2.6255],
[ 0.6016, 5.3134, -0.4075, -0.4173]],
[[-2.2090, -1.3162, -0.8148, -1.2134],
[-1.3311, 1.8877, 6.2911, 1.7421]]])mean为张量,std为标量: 不可设置size,分别在以张量mean的各个元素为均值,标量std为方差,构成的正态分布中取一个值来组成一个张量。张量尺寸与张量mean相同。
代码:
mean = torch.tensor([[1., 2., 3.],
[4., 5., 6.]])
a = torch.normal(mean, 1.)
print(a)结果:
tensor([[3.5307, 1.9584, 4.2141],
[3.5544, 4.3479, 5.6270]])mean为标量,std为张量:与上一个类似。
mean为张量,std为张量:两个张量必须尺寸一样,元素一一对应。
代码:
mean = torch.tensor([[1., 2., 3.],
[4., 5., 6.]])
std = torch.tensor([[1., 0., 1.],
[0., 1., 0.]])
a = torch.normal(mean, std)
print(a)结果:
tensor([[0.6861, 2.0000, 5.1926],
[4.0000, 5.6284, 6.0000]])-
torch.rand()
torch.rand(* size,out = None,dtype = None,layout = torch.strided,device = None,require_grad = False ) 生成的张量由区间[0,1)上的均匀分布的随机数填充,张量的形状由变量参数size定义。也有对应的torch.rand_like()
-
torch.randint()
torch.randint(low = 0,high,size,*,generator = None,out = None,dtype = None,layout = torch.strided,device = None,require_grad = False ) 生成的张量由区间[low,high]上的均匀分布的随机数填充,张量的形状由变量参数size定义。也有对应的torch.randint_like()
-
torch.randn()
torch.randn(* size,out = None,dtype = None,layout = torch.strided,device = None,require_grad = False ) 生成的张量由标准正态分布上的随机数填充,张量的形状由变量参数size定义。也有对应的torch.randn_like()
更多的方法,点击这里。
参考
https://ai.deepshare.net/detail/p_5df0ad9a09d37_qYqVmt85/6
https://blog.csdn.net/qq_25948717/article/details/80310020
https://www.cnblogs.com/henuliulei/p/11363121.html
https://www.cnblogs.com/hellcat/p/8449031.html
https://zhuanlan.zhihu.com/p/85506092