scrapy爬取优信二手车
学习scrapy需要一定的小项目练手,最近在练习使用scrapy来爬取瓜子二手车的信息,但是不知道为什么老是出现203错误,cookie,robot协议,请求头什么的都搞了,但是还是不行.最后只能退而求其次,来爬取优信二手车的信息了
通过观察优信二手车的信息,发现信息与瓜子二手车的信息差不多一致,关键是还不反爬(没有使用IP代理,也没有封我的IP),当然还是需要设置一下延时的,如果过快会出现验证码
好了,废话不多说,下面来记录一下过程
1.观察网站结构
优信二手车的链接:https://www.xin.com/guangzhou/s/
这里就以广州的二手车为例
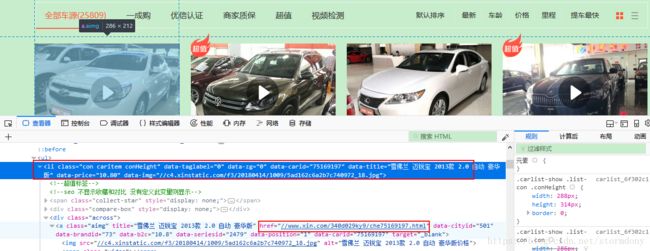
从图中可以看出,每一辆二手车都是在里面的,所以我们需要拿到里面的href 然后遍历每一个链接,拿到具体的信息
2.编写items
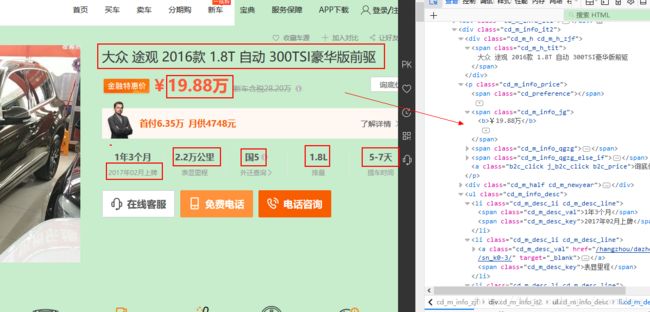
通过网页可以找到我们需要的信息
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class GuaziCarItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()#标题
time = scrapy.Field()#上牌时间
milestone = scrapy.Field()#里程数
GB = scrapy.Field()#外迁查询
displacement = scrapy.Field()#排量
get_car_time = scrapy.Field()#提车时间
price = scrapy.Field()#车主报价
3.编写spider
在这里注意链接的拼接
# -*- coding: utf-8 -*-
import scrapy
from guazi_car.items import GuaziCarItem
import re
class GauziSpider(scrapy.Spider):
name = 'gauzi'
allowed_domains = ['www.xin.com']
start_urls = ['https://www.xin.com/guangzhou/s/']
def parse(self, response):
num = len(response.xpath('//li[@class="con caritem conHeight"]').extract())
for i in range(1, num+1):
url = response.xpath('//li[{}]/div/a[@class="aimg"]/@href'.format(i)).extract_first()
real_url = "https:"+str(url)
#进入抓取详细信息的方法
yield scrapy.Request(url=real_url, callback=self.parse_detail)
next_url = response.xpath('//div[@class="con-page search_page_link"]/a[contains(text(),"下一页")]/@href').extract_first()
if next_url:
#递归抓取每辆车的href
yield scrapy.Request(url="https://www.xin.com"+next_url, callback=self.parse)
def parse_detail(self, response):
car_detail = response.xpath('/html/body/div[2]/div[2]')
if car_detail:
# 标题
title = response.xpath('/html/body/div[2]/div[2]/div[2]/div[1]/span/text()').extract_first()
# 上牌时间
time = response.xpath('/html/body/div[2]/div[2]/div[2]/ul/li[1]/span[2]/text()').extract_first()
# 里程数
milestone = response.xpath('/html/body/div[2]/div[2]/div[2]/ul/li[2]/a/text()').extract_first()
# 外迁查询
GB = response.xpath('/html/body/div[2]/div[2]/div[2]/ul/li[3]/span[1]/text()').extract_first()
# 排量
displacement = response.xpath('/html/body/div[2]/div[2]/div[2]/ul/li[4]/span[1]/text()').extract_first()
# 提车时间
get_car_time = response.xpath('/html/body/div[2]/div[2]/div[2]/ul/li[5]/span[1]/text()').extract_first()
# 车主报价
price = response.xpath('//span[@class="cd_m_info_jg"]/b/text()').extract_first()
real_price = re.findall(r'\d+.\d+',price)
item = GuaziCarItem()
item['title'] = title.strip()
item['time'] = time.strip()
item['milestone'] = milestone.strip()
item['GB'] = GB.strip()
item['displacement'] = displacement.strip()
item['get_car_time'] = get_car_time.strip()
item['price'] = real_price[0]
yield item
4.修改settings
爬取优信二手车是不需要使用IP代理池的但是这里我演示一下IP代理池和User-Agent代理池的的使用,这两个是差不多的;注意设置DOWNLOAD_DELAY = 1否则爬取过快,会出现验证码
# -*- coding: utf-8 -*-
BOT_NAME = 'guazi_car'
SPIDER_MODULES = ['guazi_car.spiders']
NEWSPIDER_MODULE = 'guazi_car.spiders'
#定义IPPool
IPPOOL=[
{"ipaddr":"218.72.66.43:18118"},
{"ipaddr":"114.99.26.120:18118"},
{"ipaddr":"183.159.84.219:18118"},
{"ipaddr":"183.159.92.201:18118"},
{"ipaddr":"183.159.88.172:18118"},
{"ipaddr":"113.200.156.91:8118"},
{"ipaddr":"60.177.230.5:8118"},
{"ipaddr":"183.159.90.23:18118"},
{"ipaddr":"115.58.131.243:8118"},
]
#定义User-Agent代理池
UAPOOL =[
'User-Agent:Mozilla/5.0(Windows;U;WindowsNT6.1;en-us)AppleWebKit/534.50(KHTML,likeGecko)Version/5.1Safari/534.50',
'User-Agent:Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1;360SE)',
'User-Agent:Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1)',
'User-Agent:Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1;Maxthon2.0)'
]
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 1 #这里需要去掉注释,否则爬取过快会出现验证码
COOKIES_ENABLED = False
#DEFAULT_REQUEST_HEADERS = {
#'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
#'Accept-Language': 'en',
#'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'
#}
#使用中间件
DOWNLOADER_MIDDLEWARES = {
'guazi_car.middlewares.MYIPPOOL': 125,
'guazi_car.middlewares.UserAgentMiddleware': 120,
}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'guazi_car.pipelines.GuaziCarPipeline': 300,
}
#使用MongoDB存储数据
MONGODB_HOST = '127.0.0.1'
MONGODB_PORT = 27017
MONGODB_DBNAME = 'youxin'
MONGODB_DOCNAME = 'car_item'
5.修改Pipelines
定义使用MongoDB
import pymongo
from scrapy.conf import settings
class GuaziCarPipeline(object):
def __init__(self):
port = settings['MONGODB_PORT']
host = settings['MONGODB_HOST']
db_name = settings['MONGODB_DBNAME']
client = pymongo.MongoClient(host=host, port=port)
db = client[db_name]
self.post = db[settings['MONGODB_DOCNAME']]
def process_item(self, item, spider):
car_info = dict(item)
self.post.insert(car_info)
return item6.修改middlewares
在middlewares.py后面,添加下面代码,这是定义使用IP代理和UA代理的方法
import logging
import random
from guazi_car.settings import IPPOOL
from guazi_car.settings import UAPOOL
class MYIPPOOL(object):
logger = logging.getLogger(__name__)
def __init__(self,ip=''):
self.ip = ip
def process_request(self,request,spider):
thisip = random.choice(IPPOOL)
self.logger.debug('Using IP')
print("当前使用的IP是:"+thisip['ipaddr'])
request.meta['proxy'] = 'http://'+thisip['ipaddr']
class UserAgentMiddleware(object):
logger = logging.getLogger(__name__)
def __init__(self,ua=''):
self.ua = ua
def process_request(self,request,spider):
thisua = random.choice(UAPOOL)
self.logger.debug('Using Agent')
print("当前使用的UA是:"+thisua)
request.headers.setdefault('User-Agent',thisua)7.运行
上面的代码都码好之后,可以试着运行一下了,在terminal中输入
scrapy crawl gauzi
之后就可以到数据库中看我们爬下来的信息了
8.总结
由于时间和网速的问题,我这里只爬了差不多2千条信息就让它停下来了,这里并没有使用多进程,所以有点慢.而且没有进行很好的异常处理,所以会有一些粗糙.(毕竟刚入scrapy的坑不久)
相应的代码已经上传到GitHub了,如果有兴趣可以去clone下来看看
GitHub地址:https://github.com/stormdony/scarpydemo/tree/master/guazi_car
后面将会对这些信息进行初步的清洗和可视化处理,如果有兴趣可以关注我后面的博客,谢谢<~_^>