###豪豪豪豪######2020 推荐系统技术演进趋势了解
读知乎文章《推荐系统技术演进趋势:从召回到排序再到重排》笔记:
《推荐系统技术演进趋势:从召回到排序再到重排》这篇文章主要说了下最近两年,推荐系统技术的一些比较明显的技术发展趋势。主要从以下几个方面介绍:
推荐系统整体架构
召回技术演进趋势
排序模型技术演进趋势
重排技术演进趋势
一、推荐系统整体架构
推荐系统宏观架构:

推荐系统宏观结构
细分四阶段:

推荐系统细分四阶段
二、召回技术演进趋势
1、传统:多路召回(每一路召回相当于单特征排序结果)

传统召回
2、未来:模型召回(引入多特征,把单特征排序拓展成多特征排序的模型)
(1)模型召回
根据用户物品Embedding,采用类似Faiss等高效Embedding检索工具,快速找出和用户兴趣匹配的物品,这样就等于做出了利用多特征融合的召回模型了。
理论上来说,任何你能见到的有监督模型,都可以用来做这个召回模型,比如FM/FFM/DNN等,常说的所谓“双塔”模型,指的其实是用户侧和物品侧特征分离分别打Embedding的结构而已,并非具体的模型。
值得注意的一点是:如果在召回阶段使用模型召回,理论上也应该同步采用和排序模型相同的优化目标,尤其是如果排序阶段采用多目标优化的情况下,召回模型也应该对应采取相同的多目标优化。同理,如果整个流程中包含粗排模块,粗排也应该采用和精排相同的多目标优化,几个环节优化目标应保持一致。因为召回和粗排是精排的前置环节,否则,如果优化目标不一致,很可能会出现高质量精排目标,在前置环节就被过滤掉的可能,影响整体效果。

通用模型召回
(2)用户行为序列召回

用户行为序列召回
核心在于:这个物品聚合函数Fun如何定义的问题。这里需要注意的一点是:用户行为序列中的物品,是有时间顺序的。理论上,任何能够体现时序特点或特征局部性关联的模型,都比较适合应用在这里,典型的比如CNN、RNN、Transformer、GRU(RNN的变体模型)等,都比较适合用来集成用户行为序列信息。
在召回阶段,如何根据用户行为序列打embedding,可以采取有监督的模型,比如Next Item Prediction的预测方式即可;也可以采用无监督的方式,比如物品只要能打出embedding,就能无监督集成用户行为序列内容,例如Sum Pooling。
(3)用户多兴趣拆分(利用用户行为物品序列,打出用户兴趣Embedding的做法)

用户兴趣多embedding拆分
(4)知识图谱融合召回
根据用户的兴趣实体,通过知识图谱的实体Embedding化表达后(或者直接在知识图谱节点上外扩),通过知识外扩或者可以根据Embedding相似性,拓展出相关实体。
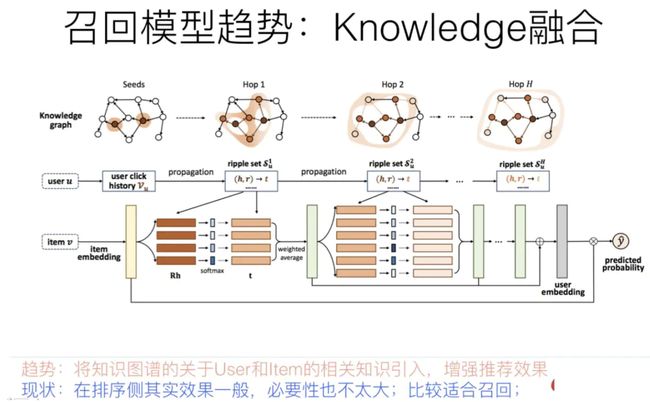
知识图谱融合召回
(5)图神经网络模型召回

图计算召回
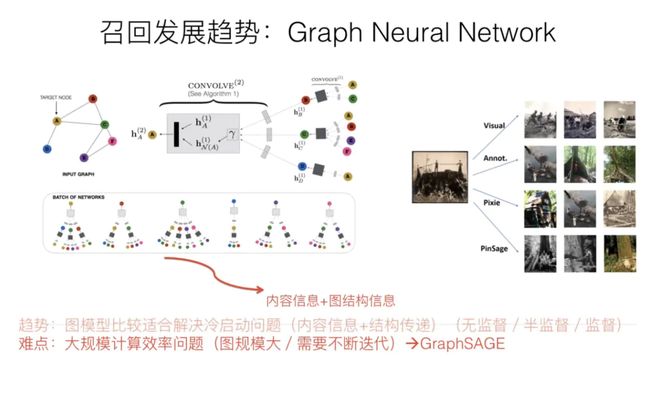
CONVOLVE图示
图神经网络的最终目的是要通过一定技术手段,获得图中节点的embedding编码。最常用的embedding聚合工具是CNN,对于某个图节点来说,它的输入可以有两类信息,一类是自身的属性信息,比如上面举的微博的例子;另外一类是图结构信息,就是和当前节点有直接边关联的其它节点信息。通过CNN,可以对两类信息进行编码和聚合,形成图节点的embedding。通过CNN等信息聚合器,在图节点上进行计算,并反复迭代更新图节点的embedding,就能够最终获得可靠的图节点embedding信息,而这种迭代过程,其实体现的是远距离的节点将信息逐步通过图结构传递信息的过程,所以图结构是可以进行知识传递和补充的。
我们可以进一步思考下,图节点因为可以带有属性信息,比如物品的Content信息,所以明显这对于解决物品侧的冷启动问题有帮助;而因为它也允许知识在图中远距离进行传递,所以比如对于用户行为比较少的场景,可以形成知识传递和补充,这说明它也比较适合用于数据稀疏的推荐场景;另外一面,图中的边往往是通过用户行为构建的,而用户行为,在统计层面来看,本质上是一种协同信息,比如我们常说的“A物品协同B物品”,本质上就是说很多用户行为了物品A后,大概率会去对物品B进行行为;所以图具备的一个很好的优势是:它比较便于把协同信息、用户行为信息、内容属性信息等各种异质信息在一个统一的框架里进行融合,并统一表征为embedding的形式,这是它独有的一个优势,做起来比较自然。另外的一个特有优势,就是信息在图中的传播性,所以对于推荐的冷启动以及数据稀疏场景应该特别有用。
早期的图神经网络做推荐,因为需要全局信息,所以计算速度是个问题,往往图规模都非常小,不具备实战价值。而GraphSAGE则通过一些手段比如从临近节点进行采样等减少计算规模,加快计算速度,很多后期改进计算效率的方法都是从这个工作衍生的;而PinSage在GraphSAGE基础上(这是同一拨人做的),进一步采取大规模分布式计算,拓展了图计算的实用性,可以计算Pinterest的30亿规模节点、180亿规模边的巨型图,并产生了较好的落地效果。所以这两个工作可以重点借鉴一下。
总体而言,图模型召回,是个很有前景的值得探索的方向。
三、排序模型技术演进趋势

排序技术发展趋势
模型优化目标则体现了我们希望推荐系统去做好什么,往往跟业务目标有关联,这里我们主要从技术角度来探讨,而多目标优化以及ListWise最优是目前最常见的技术进化方向,ListWise优化目标在排序阶段和重排阶段都可采用,我们把它放到重排部分去讲,这里主要介绍多目标优化;
模型表达能力代表了模型是否具备充分利用有效特征及特征组合的能力,其中显示特征组合、新型特征抽取器、增强学习技术应用以及AutoML自动探索模型结构是这方面明显的技术进化方向;
从特征和信息角度,如何采用更丰富的新类型特征,以及信息和特征的扩充及融合是主要技术进化方向,用户长短期兴趣分离、用户行为序列数据的使用、图神经网络以及多模态融合等是这方面的主要技术趋势。
1.1 模型优化目标-多目标优化
推荐系统的多目标优化(点击,互动,时长等多个目标同时优化)严格来说不仅仅是趋势,而是目前很多公司的研发现状。对于推荐系统来说,不同的优化目标可能存在互相拉后腿的现象,多目标旨在平衡不同目标的相互影响,而如果多目标优化效果好,对于业务效果的推动作用也非常大。总而言之,多目标优化是值得推荐系统相关研发人员重点关注的技术方向。
从技术角度讲,多目标优化最关键的有两个问题。第一个问题是多个优化目标的模型结构问题;第二个问题是不同优化目标的重要性如何界定的问题(超参如何寻优)。
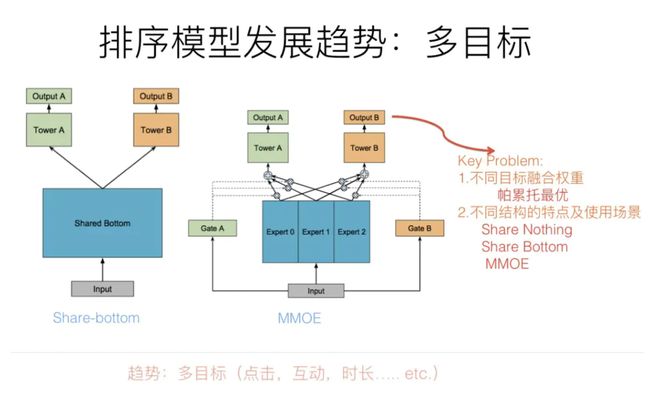
多目标模型架构
2.1 模型表达能力-显式特征组合

排序模型发展史-特征工程发展史
如果归纳下工业界CTR模型的演化历史的话,你会发现,特征工程及特征组合的自动化,一直是推动实用化推荐系统技术演进最主要的方向,而且没有之一。最早的LR模型,基本是人工特征工程及人工进行特征组合的,简单有效但是费时费力;再发展到LR+GBDT的高阶特征组合自动化,以及FM模型的二阶特征组合自动化;再往后就是DNN模型的引入,纯粹的简单DNN模型本质上其实是在FM模型的特征Embedding化基础上,添加几层MLP隐层来进行隐式的特征非线性自动组合而已。

显示特征组合发展趋势
2.2 模型表达能力-特征抽取器的进化
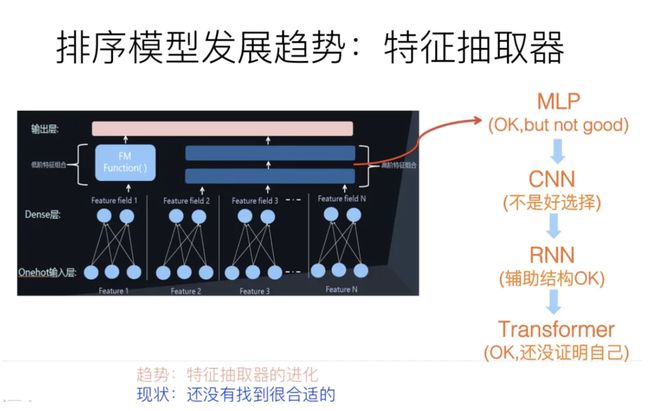
特征抽取器
从特征抽取器的角度来看,目前主流的DNN 排序模型,最常用的特征抽取器仍然是MLP结构,图像领域的CNN、NLP领域的RNN和Transformer。
MLP结构通常是两层或者三层的MLP隐层。目前也有理论研究表明:MLP结构用来捕获特征组合,是效率比较低下的。
CNN捕获局部特征关联是非常有效的结构,但是并不太适合做纯特征输入的推荐模型,因为推荐领域的特征之间,在输入顺序上并无必然的序列关系,CNN的捕获远距离特征关系能力差的弱点,以及RNN的不可并行处理、所以速度慢的劣势等。
Transformer作为NLP领域最新型也是最有效的特征抽取器,从其工作机制来说,其实是非常适合用来做推荐的。为什么这么说呢?核心在于Transformer的Multi-Head Self Attention机制上。MHA结构在NLP里面,会对输入句子中任意两个单词的相关程度作出判断,而如果把这种关系套用到推荐领域,就是通过MHA来对任意特征进行特征组合,而上文说过,特征组合对于推荐是个很重要的环节,所以从这个角度来说,Transformer是特别适合来对特征组合进行建模的,一层Transformer Block代表了特征的二阶组合,更多的Transformer Block代表了更高阶的特征组合。但是,实际上如果应用Transformer来做推荐,其应用效果并没有体现出明显优势,甚至没有体现出什么优势,基本稍微好于或者类似于典型的MLP结构的效果。这意味着,可能我们需要针对推荐领域特点,对Transformer需要进行针对性的改造,而不是完全直接照搬NLP里的结构。
截一张张老师其他关于Transformer的图,足以说明Transformer的意义,但现在还不是很懂,哈哈~

Transformer
2.3 AutoML在推荐的应用
AutoML在17年初开始出现,最近三年蓬勃发展,在比如图像领域、NLP领域等都有非常重要的研究进展,在这些领域,目前都能通过AutoML找到比人设计的效果更好的模型结构。

DNN Ranking Model基本算子
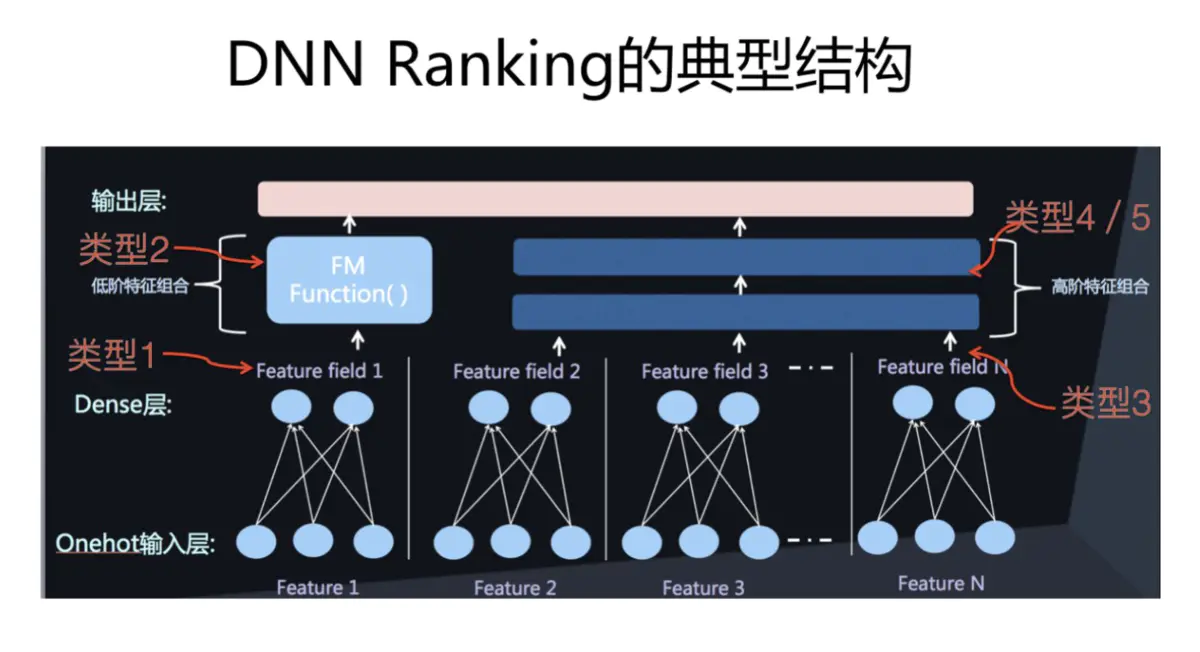
ranking模型对应类型模型结构所在

高效神经架构搜索(Efficient Neural Architecture Search)神经网络架构的搜索空间可以表示成有向无环图(DAG),一个神经网络架构可以表示成DAG的一个子图
2.4 增强学习在推荐的应用
增强学习其实是比较吻合推荐场景建模的。一般而言,增强学习有几个关键要素:状态、行为以及回报。在推荐场景下,我们可以把状态St定义为用户的行为历史物品集合;推荐系统可选的行为空间则是根据用户当前状态St推荐给用户的推荐结果列表,这里可以看出,推荐场景下,用户行为空间是巨大无比的,这制约了很多无法对巨大行为空间建模的增强学习方法的应用;而回报呢,则是用户对推荐系统给出的列表内容进行互动的行为价值,比如可以定义点击了某个物品,则回报是1,购买了某个物品,回报是5….诸如此类。有了这几个要素的场景定义,就可以用典型的增强学习来对推荐进行建模。

增强学习在推荐系统的应用
3.1 多模态信息融合
多模态融合,从技术手段来说,本质上是把不同模态类型的信息,通过比如Embedding编码,映射到统一的语义空间内,使得不同模态的信息,表达相同语义的信息完全可类比。比如说自然语言说的单词“苹果”,和一张苹果的图片,应该通过一定的技术手段,对两者进行信息编码,比如打出的embedding,相似度是很高的,这意味着不同模态的知识映射到了相同的语义空间了。这样,你可以通过文本的苹果,比如搜索包含苹果的照片。
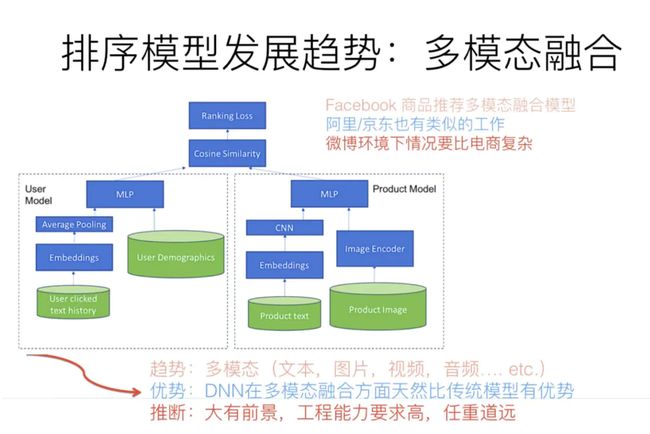
多模态融合
3.2 长期兴趣/短期兴趣分离
对于推荐系统而言,准确描述用户兴趣是非常重要的。目前常用的描述用户兴趣的方式主要有两类。一类是以用户侧特征的角度来表征用户兴趣,也是最常见的;另外一类是以用户发生过行为的物品序列作为用户兴趣的表征。

长短期兴趣分离
四、重排技术演进趋势
关于List Wise重排序,可以从两个角度来说,一个是优化目标或损失函数;一个是推荐模块的模型结构。

rerank发展趋势:List Wise
推荐系统里Learning to Rank做排序,我们知道常见的有三种优化目标:Point Wise、Pair Wise和List Wise。所以我们首先应该明确的一点是:List Wise它不是指的具体的某个或者某类模型,而是指的模型的优化目标或者损失函数定义方式,理论上各种不用的模型都可以使用List Wise损失来进行模型训练。最简单的损失函数定义是Point Wise,就是输入用户特征和单个物品特征,对这个物品进行打分,物品之间的排序,就是谁应该在谁前面,不用考虑。明显这种方式无论是训练还是在线推理,都非常简单直接效率高,但是它的缺点是没有考虑物品直接的关联,而这在排序中其实是有用的。Pair Wise损失在训练模型时,直接用两个物品的顺序关系来训练模型,就是说优化目标是物品A排序要高于物品B,类似这种优化目标。其实Pair Wise的Loss在推荐领域已经被非常广泛得使用,比如BPR损失,就是典型且非常有效的Pair Wise的Loss Function,经常被使用,尤其在隐式反馈中,是非常有效的优化目标。List Wise的Loss更关注整个列表中物品顺序关系,会从列表整体中物品顺序的角度考虑,来优化模型。在推荐中,List Wise损失函数因为训练数据的制作难,训练速度慢,在线推理速度慢等多种原因,尽管用的还比较少,但是因为更注重排序结果整体的最优性,所以也是目前很多推荐系统正在做的事情。
从模型结构上来看。因为重排序模块往往是放在精排模块之后,而精排已经对推荐物品做了比较准确的打分,所以往往重排模块的输入是精排模块的Top得分输出结果,也就是说,是有序的。而精排模块的打分或者排序对于重排模块来说,是非常重要的参考信息。于是,这个排序模块的输出顺序就比较重要,而能够考虑到输入的序列性的模型,自然就是重排模型的首选。我们知道,最常见的考虑时序性的模型是RNN和Transformer,所以经常把这两类模型用在重排模块,这是很自然的事情。一般的做法是:排序Top结果的物品有序,作为RNN或者Transformer的输入,RNN或者Transformer明显可以考虑在特征级别,融合当前物品上下文,也就是排序列表中其它物品,的特征,来从列表整体评估效果。RNN或者Transformer每个输入对应位置经过特征融合,再次输出预测得分,按照新预测的得分重新对物品排序,就完成了融合上下文信息,进行重新排序的目的。
参考资料:
1、推荐系统技术演进趋势:从召回到排序再到重排
https://zhuanlan.zhihu.com/p/100019681
2、模型召回典型工作:
FM模型召回:推荐系统召回四模型之:全能的FM模型
DNN双塔召回:Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations
3、用户行为序列召回典型工作:
GRU:Recurrent Neural Networks with Top-k Gains for Session-based Recommendations
CNN:Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding
Transformer: Self-Attentive Sequential Recommendation
4、知识图谱融合召回典型工作:
KGAT: Knowledge Graph Attention Network for Recommendation
RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems
5、图神经网络模型召回典型工作:
GraphSAGE: Inductive Representation Learning on Large Graphs
PinSage: Graph Convolutional Neural Networks for Web-Scale Recommender Systems
6、模型多目标优化典型工作:
MMOE:Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
帕累托最优:A Pareto-Efficient Algorithm for Multiple Objective Optimization in E-Commerce Recommendation
7、显式特征组合典型工作:
Deep& Cross: Deep & Cross Network for Ad Click Predictions
XDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems
8、特征抽取器典型工作:
AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks
DeepFM: An End-to-End Wide & Deep Learning Framework for CTR Prediction
9、对比CNN\RNN\特征抽取器:https://zhuanlan.zhihu.com/p/54743941
10、AutoML在推荐的应用典型工作:
ENAS结构搜索:AutoML在推荐排序网络结构搜索的应用
双线性特征组合: FiBiNET: Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction
11、增强学习在推荐的应用典型工作:
Youtube: Top-K Off-Policy Correction for a REINFORCE Recommender System
Youtube: Reinforcement Learning for Slate-based Recommender Systems: A Tractable Decomposition and Practical Methodology
12、多模态融合典型工作:
DNN召回:Collaborative Multi-modal deep learning for the personalized product retrieval in Facebook Marketplace
排序:Image Matters: Visually modeling user behaviors using Advanced Model Server
13、长短期兴趣分离典型工作:
1. Neural News Recommendation with Long- and Short-term User Representations
2. Sequence-Aware Recommendation with Long-Term and Short-Term Attention Memory Networks
14、List Wise重排序典型工作:
1.Personalized Re-ranking for Recommendation
2.Learning a Deep Listwise Context Model for Ranking Refinement
作者:是黄小胖呀
链接:
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。