mmdetection训练自己的数据并评估mAP
用mmdetection做目标检测的训练还是比较简单的,但是目前代码尚不稳定,其中也有很多的坑,下面简单讲解一下如何用mmdetetection在VOC的数据集上进行模型的训练,算是对mmdetection的简单入门。
1. 制作VOC数据集
mmdetection支持VOC和COCO标注格式的数据集,本次我们使用VOC2007格式数据集,我这里数据集已经制作好了,目录如下:
├── Datasets
│ │ ├── VOC2007
│ │ │ ├── Annotations
│ │ │ ├── JPEGImages
│ │ │ ├── ImageSets
│ │ │ │ ├── Main
│ │ │ │ │ ├── test.txt
│ │ │ │ │ ├── trainval.txt
|—— val.txt
数据集中收集了各种车辆以及一些安全隐患图片,我们需要对图像中的车辆目标以及隐患目标进行检测,总共有26种检测目标 。
上面的数据集并不在mmdetection数据目录下,因此我们需要软连接到mmdetection数据目录下,mmdetection建议将数据集根符号链接到mmdetection/data目录下,目录结构如下:
mmdetection
├── mmdet
├── tools
├── configs
├── data
│ ├── coco
│ │ ├── annotations
│ │ ├── train2017
│ │ ├── val2017
│ │ ├── test2017
│ ├── VOCdevkit
│ │ ├── VOC2007
│ │ ├── VOC2012因此,我们在mmdetection目录下执行如下命令新建目录:
mkdir -p data/VOCdevkit
将制作好的VOC2007数据集软链接到上述新建目录:
cd data/VOCdevkit
ln -s /home/你的路径/Datasets/VOC2007/ ./
2. 选择一个网络模型,并对该模型的配置文件进行修改
这里使用的模型是Libra R-CNN,它是2019年CVPR一篇论文提出的模型,作者来自浙大和商汤,代码开源在mmdetection。
执行如下命令,切换到对应的配置文件目录下:
cd mmdetection/configs/libra_rcnn/
vi libra_faster_rcnn_x101_64x4d_fpn_1x.py
目录下有多个不同网络版本的配置文件,我们选择libra_faster_rcnn_x101_64x4d_fpn_1x.py进行配置,这里面有很多的参数可供配置,我们只选择一些必要的参数,能够使得我们的模型能够跑起来,进行数据的训练。
1)修改分类器的类别数量
因为自己制作的数据集包含26种目标,需要对这个26个目标进行检测,另外加上所有的背景算作一个目标,所有我们的类别数量为27,因此修改num_classes = 27
2)配置数据集
mmdetection默认的是coco数据集,而我们本次使用的是VOC数据集,因此我们需要对数据集进行配置,配置比较简单,就是指明数据集的类型,路径,以及各个训练集、测试集文件路径即可:
原始配置文件:
# dataset settings
dataset_type = 'CocoDataset'
data_root = 'data/coco/'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
data = dict(
imgs_per_gpu=2,
workers_per_gpu=2,
train=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_train2017.json',
img_prefix=data_root + 'train2017/',
img_scale=(1333, 800),
img_norm_cfg=img_norm_cfg,
size_divisor=32,
flip_ratio=0.5,
with_mask=False,
with_crowd=True,
with_label=True),
val=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
img_scale=(1333, 800),
img_norm_cfg=img_norm_cfg,
size_divisor=32,
flip_ratio=0,
with_mask=False,
with_crowd=True,
with_label=True),
test=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
img_scale=(1333, 800),
img_norm_cfg=img_norm_cfg,
size_divisor=32,
flip_ratio=0,
with_mask=False,
with_label=False,
test_mode=True))修改后的配置文件:
dataset_type = 'VOCDataset'
data_root = 'data/VOCdevkit/'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
data = dict(
imgs_per_gpu=1,
workers_per_gpu=2,
train=dict(
type=dataset_type,
ann_file=data_root + 'VOC2007/ImageSets/Main/trainval.txt',
img_prefix=data_root + 'VOC2007/',
img_scale=(1333, 800),
img_norm_cfg=img_norm_cfg,
size_divisor=32,
flip_ratio=0.5,
with_mask=False,
with_crowd=True,
with_label=True),
val=dict(
type=dataset_type,
ann_file=data_root + 'VOC2007/ImageSets/Main/val.txt',
img_prefix=data_root + 'VOC2007/',
img_scale=(1333, 800),
img_norm_cfg=img_norm_cfg,
size_divisor=32,
flip_ratio=0,
with_mask=False,
with_crowd=True,
with_label=True),
test=dict(
type=dataset_type,
ann_file=data_root + 'VOC2007/ImageSets/Main/test.txt',
img_prefix=data_root + 'VOC2007/',
img_scale=(1333, 800),
img_norm_cfg=img_norm_cfg,
size_divisor=32,
flip_ratio=0,
with_mask=False,
with_label=False,
test_mode=True))上面两个文件对比一下,只是修改了dataset_type、data_root、ann_file、img_prefix变量的值。
3) 修改数据集文件voc.py
该文件中有检测目标的配置,默认已经存在了一些检测目标,我们需要修改我们自己的数据集需要训练的检测目标,原始文件如下:
from .xml_style import XMLDataset
class VOCDataset(XMLDataset):
CLASSES = ('aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car',
'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train',
'tvmonitor')
def __init__(self, **kwargs):
super(VOCDataset, self).__init__(**kwargs)
if 'VOC2007' in self.img_prefix:
self.year = 2007
elif 'VOC2012' in self.img_prefix:
self.year = 2012
else:
raise ValueError('Cannot infer dataset year from img_prefix')注释掉原来的CLASSES元组,添加我们自己的CLASSES元组:
from .xml_style import XMLDataset
class VOCDataset(XMLDataset):
# CLASSES = ('aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car',
# 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse',
# 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train',
# 'tvmonitor')
CLASSES = ('towercrane', 'crane',
'crane_lifting', 'pumper', 'pumper_stretch',
'digger', 'dozer', 'roller', 'forklift',
'piledriver', 'ballgrader', 'grab',
'insulatedarmcar', 'othercars', 'truck',
'hangings', 'dustproofnet', 'reflectivefilm',
'smoke', 'fire', 'tower', 'scaffold',
'nest', 'person', 'car', 'bus')
def __init__(self, **kwargs):
super(VOCDataset, self).__init__(**kwargs)
if 'VOC2007' in self.img_prefix:
self.year = 2007
elif 'VOC2012' in self.img_prefix:
self.year = 2012
else:
raise ValueError('Cannot infer dataset year from img_prefix')我们新添加的CLASSES元组有26个元素,也就是说我们需要对26个目标进行检测,26个目标加上背景也就是之前修改的分类器的类别数量27。
4)运行环境的配置
在配置文件的末尾有如下参数:
total_epochs = 20 # 训练最大的epoch数
dist_params = dict(backend='nccl') # 分布式参数,目前用不到
log_level = 'INFO' # 输出信息的完整度级别
work_dir = './work_dirs/libra_faster_rcnn_x101_64x4d_fpn_1x' # log文件和模型文件存储路径
load_from = None # 加载模型的路径,None表示从预训练模型加载
resume_from = None # 恢复训练模型的路径,None表示不进行训练模型的恢复
workflow = [('train', 1)] # 训练与验证策略,[('train', 1)]表示只训练,不验证;[('train', 2), ('val', 1)] 表示2个epoch训练,1个epoch验证
可根据自己的需要进行修改,不修改使用默认参数也不会报错。
至此,配置文件就修改完毕了。
特别注意:修改完成后需要重新编译框架,执行
./compile.sh
python setup.py develop即可进行重新安装,使voc.py的修改生效。
3. 执行命令进行训练
mmdetection训练的命令格式如下:
python tools/train.py --gpus --work_dir CUDA_VISIBLE_DEVICES: 指定本次训练可以使用的GPU设备编号
CONFIG_FILE: 配置文件
GPU_NUM: 训练使用的GPU数量
WORK_DIR: 日志和模型文件存放目录
执行训练:
python tools/train.py configs/libra_rcnn/libra_faster_rcnn_x101_64x4d_fpn_1x.py --gpus 2
上面的--gpus 2表示使用两块GPU进行训练,如果你的是单GPU可以不加--gpus 2选项
以上执行如果不报错的话,训练就开始了...
4. 查看训练日志
在配置文件中work_dir变量配置了训练日志和模型配置文件的路径,开始训练后我们可以到目录下查看训练情况:
cd work_dirs/libra_faster_rcnn_x101_64x4d_fpn_1x
![]()
上面的.log、.log.json文件就是训练的日志文件,每训练完一个epoch后目录下还会有对应的以epoch_x.pth的模型文件,最新训练的模型文件命名为latest.pth。
.log文件的内容如下:
![]()
.log.json文件内容如下:
![]()
上面的文件内容大同小异,有当前时间、epoch次数,迭代次数(配置文件中默认设置50个batch输出一次log信息),学习率、损失函数loss、准确率等信息,可以根据上面的训练信息进行模型的评估与测试,另外可以通过读取.log.json文件进行可视化展示,方便调试。
5. 计算mAP
训练结束后需要评估指标,也就是计算mAP.
(1) 修改voc_eval.py文件中的voc_eval函数
注释如下代码:
if hasattr(dataset, 'year') and dataset.year == 2007:
dataset_name = 'voc07'
else:
dataset_name = dataset.CLASSES在eval_map上面添加:
dataset_name = dataset.CLASSES修改后的voc_eval函数代码如下:
def voc_eval(result_file, dataset, iou_thr=0.5):
det_results = mmcv.load(result_file)
gt_bboxes = []
gt_labels = []
gt_ignore = []
for i in range(len(dataset)):
ann = dataset.get_ann_info(i)
bboxes = ann['bboxes']
labels = ann['labels']
if 'bboxes_ignore' in ann:
ignore = np.concatenate([
np.zeros(bboxes.shape[0], dtype=np.bool),
np.ones(ann['bboxes_ignore'].shape[0], dtype=np.bool)
])
gt_ignore.append(ignore)
bboxes = np.vstack([bboxes, ann['bboxes_ignore']])
labels = np.concatenate([labels, ann['labels_ignore']])
gt_bboxes.append(bboxes)
gt_labels.append(labels)
if not gt_ignore:
gt_ignore = None
# if hasattr(dataset, 'year') and dataset.year == 2007:
# dataset_name = 'voc07'
# else:
# dataset_name = dataset.CLASSES
dataset_name = dataset.CLASSES
eval_map(
det_results,
gt_bboxes,
gt_labels,
gt_ignore=gt_ignore,
scale_ranges=None,
iou_thr=iou_thr,
dataset=dataset_name,
print_summary=True)(2)用测试模型
执行如下命令:
python tools/test.py configs/libra_rcnn/libra_faster_rcnn_x101_64x4d_fpn_1x.py work_dirs/cascade_rcnn_hrnetv2p_w32/latest.pth --out results.pkl测试结束后生成results.pkl文件。
(3)采用voc标准计算mAP
执行如下命令:
python tools/voc_eval.py results.pkl configs/libra_rcnn/libra_faster_rcnn_x101_64x4d_fpn_1x.py生成如下结果:
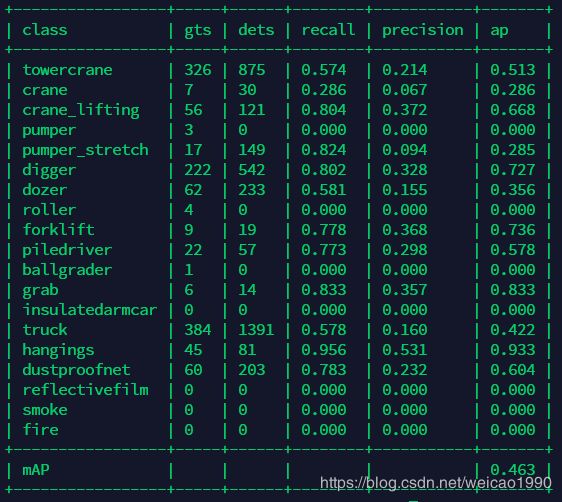
注:如果不修改voc_eval.py文件,则会采用VOC默认的目标类型进行评估,而不是我们自己数据集的目标类型。