这个作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339。
首先,我是分析B站最火番剧剧迷们的评论,也就是我前面的文章------爬虫大作业分析的数据。下面开始进行HIVE分析。
1.数据导入。因为我是用自己的数据进行分析,不免就要进行csv导出,其中用到了pandas,具体代码加入到爬虫数据中即可。

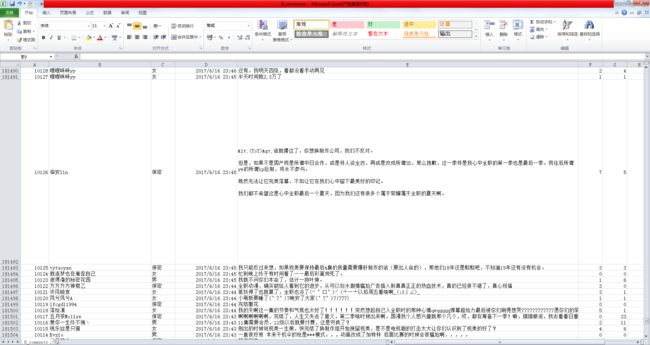
这是我自己的excel数据:
将自己的csv导入到bigdatacase里面,下载后直接移动和粘贴即可。然后测试一下自己是否导入成功,看看自己的路径下面是否有自己的csv文件。我的路径是 /usr/local/bigdatacase。

预处理,创建一个脚本文件pre_deal.sh,文件内容如下:

将文件另存为txt格式,并为bigdatacase授权。最后查询数据,同时对以前的数据进行对比。

具体的学习可以去http://www.runoob.com/linux/linux-comm-awk.html,awk处理文本文件的语言。
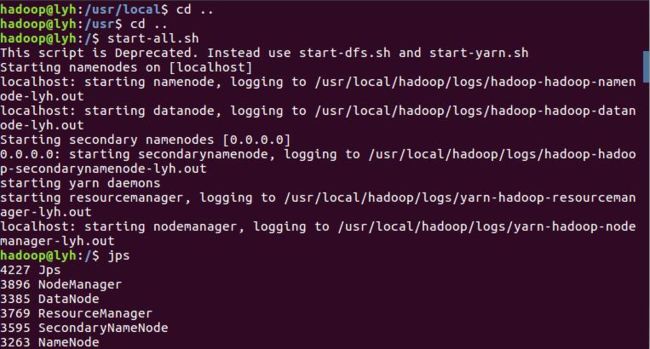
接下来开启HDFS:
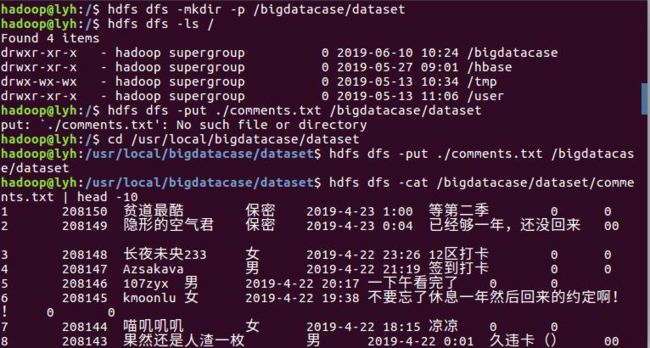
 在HDFS上建立bigdatabasecase/dataset。将bcomments.txt存入到hdfs的路径中,最后进行验证。
在HDFS上建立bigdatabasecase/dataset。将bcomments.txt存入到hdfs的路径中,最后进行验证。
启动MySQL数据库、Hadoop和Hive:
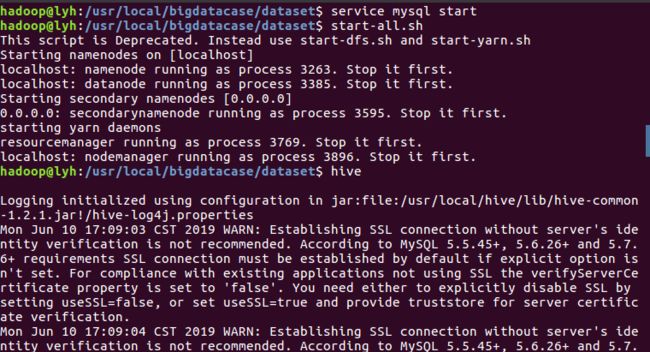
创建数据库dblab,并通过命令“use dblab”打开和使用数据库:
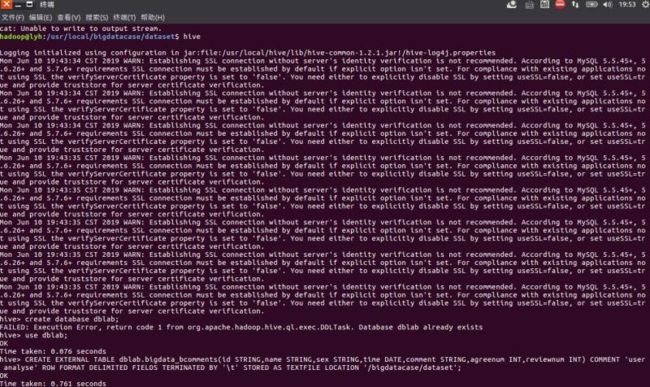
创建外部表bdlab.bigdata_bcomments,并且把‘/bigdatacase/dataset’目录下的数据加载到数据仓库Hive中。(注意:里面的列类,都是根据自己的实际需求进行更改。如果熟悉数据语言,可进行相应的修改。)

最后,通过select语句查询数据库前10条数据和某一列的数据,检查前面创建的表是否有问题。
2.数据分析。通过创建的数据库表对大数据进行查询和分析。
查询剧迷性别,由此判断B站最受欢迎番剧的受众人群性别:

查询剧迷评论,了解剧迷对这部番据的评价和观后感。同时,查询用户评论时间了解剧迷们聚集观剧的时间。
查询某个B站用户评论的点赞数和回复数:
向数据库表重写数据,覆盖之前表里的数据,排除因预处理环境导致的数据库表出现问题:
insert overwrite table bigdata_bcomment select * from bigdata_bcomment where id is not null;

查询数据一共有多少条:
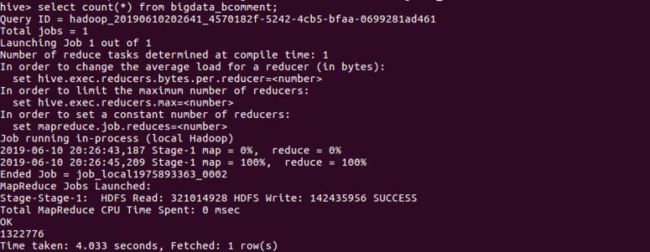
查询用户们的name属性是否相同,来进行检验:

3.总结。
总的来说,这次的项目其实贯通了半个学期以来学习到的知识点,比如爬虫大作业的爬数据、Hadoop的基础运用、HDFS的运用、HIVE的运用和数据分析等等。所以整个项目,将所学知识的串联到了一起。学习到了许多,花了很多时间做这个作业,认认真真写,但是遇到的问题也是有以下:
a.自己挖掘的数据量很庞大,而且中文内容很多,因此在导入linux系统时出现了中文乱码。
b.对于其中的很多知识点不懂,比如sed、awk都没有理解和学习,因此在对数据文件进行预处理时出现了有些行或列为null的情况。
c.数据存入数据库表前就出现了问题,那么在进行数据库表内容查询时会出现一些非预期的错误。
最后,嗯~受益匪浅。