模型训练与测试-----pytorch和keras的软融合----GAP与全连接的作用
最近因为项目需要做细粒度,需要将POI的全局特征,和OCR的文字特征进行融合,然后进行分类从而让模型具有区分细粒度的特点。 POI模型是pytorch,但是OCR那边的模型是keras, 因为实习时间有限,如果通过H5融合的话其实对于两个模型的后期调整非常麻烦,就是每次你都要调整,跑完全部数据,然后保存对应的全部H5,如果训练数据多的话,光是保存H5就需要时间了。而且OCR我们想提取哪一层特征也不是很明确,所以这样做的话时间会比较久。更新迭代的版本也是有限的,所以我决定尝试软融合,也就是我不通过保存H5,用pytorch作为主体框架,用keras模型部分,作为pytorch的一部分。选择用pytorch,第一是我可能不太了解tf,但是tf之前做过,但是感觉tensorflow可拓展性不是很强,而且里面涉及到了graph和session的概念,所以我还是用了pytorch.比如pytorch可以自己去定义一些层用nn.module只要将反向传播写好了就可以。pytorch的灵活性体现在它可以任意拓展我们所需要的内容
Tensorflow学习资料
https://zhuanlan.zhihu.com/p/47136826
https://zhuanlan.zhihu.com/p/45476929
pytorch灵活性的资料:
https://blog.csdn.net/weixin_37721058/article/details/97167620
pytorch的debug日记
https://blog.csdn.net/weixin_37721058/article/details/97146452
– NCHW 还是 NHWC
首先是pytorch 和keras 的tensor本身的排布是不一样的,这里是需要注意的,避免在后面混合的时候出问题。
def ocr_feature(self, x):
#input pytorch type: (B,C,H,W) NCHW
out_feature = x.permute(0,2,3,1).contiguous()
#input keras type:(B,H,W,C)
ocr_feature = ocr_model(out_feature) NHWC
#output keras :(B,H,W,C)
out_feature = ocr_feature.permute(0,3,1,2).contiguous()
#output pytorch (B,C,H,W) NCHW
return out_feature
上面的代码可以看出我们是先pytorch的tensor作为输入到keras 但是pytorch的tensor的布局是#input pytorch type: (B,C,H,W) , 而keras的布局是#input keras type:(B,H,W,C),准确来说是tensorflow的
。所以我们需要进行第一步的转换。接着tensor进入到了keras 中进行模型的特征提取,最后作为输出。这里需要注意的是输出的仍然是keras的排布,所以我们又再一次的转换,让他变成了pytorch的排布。
这里的链接提到了,为什么tensorflow 是NHWC ,因为早期的CPU就是这样的结构。而tensorflow的时间更高。https://blog.csdn.net/weixin_37801695/article/details/86614566
-提高速度小技巧:
**[NCHW]是在NVIDIA GPU上使用cuDNN训练时可以使用的最佳顺序。**所以无论是pytorch还是tensorflow如果用GPU其实这样的分布更好。最佳实践:设计网络时充分考虑两种格式,最好能灵活切换,在 GPU 上训练时使用 NCHW 格式,在 CPU 上做预测时使用 NHWC 格式。
– 数据格式转换
关于格式问题,主要需要解决什么?第一个是 batch 的计算,其实如果是单独一张张图的测试,那么我们的融合会非常方便,因为只要注意tensor和numpy的转换就好了。但是我们训练。都是一个batch 一个batch来训练的,所以不太可能这么做。如果我们用单GPU,可以一个Batch,但是如果是多GPU那么就是一个batch可能被拆分然后并行运算提高速度,但是两个框架如何对应起来呢?还有就是我们用GPU训练,那么就存在cuda和cpu的转换。
关于Batch的问题:这里目前只能用单GPU运算,多GPU的话,会出现pytorch在将tensor输入到模型中的时候,回并行进入。比如(8,C, H, W)会被并行成了(4,C,H,W)两个。但是这样输入到keras中,会报错。因为我们keras用的是测试。批测试的话可以有batch的形式进入,但是不能并行进入。所以不确定该如何多GPU测试的情况下,我们选择了单GPU,这里就是keras的模型输入部分,用的是批测试。然后输入前我们需要将pytorch的tensor这样转换:
首先是pytorch在训练中,不能在GPU将tensor转换乘Numpy必须切换到CPU的模型的格式,所以这里我们先切换乘GPU然后转换成Numpy。接着Numpy在转换成tensorflow的tensor, 至于批训练的话,我们这里就对应的批测试,tensorflow是提供这样的操作的。最后将输出的结果再次转换成torch的tensor,这次就不麻烦了,直接就可以转了。然后在变成了cuda 对应的即可。接着出来的话就可以concat然后进行运算了
pytorch Tensor gpu ---- CPU ----- Numpy ---- tensorflow Tensor
X = tf.convert_to_tensor(X.cpu().numpy())
y_pred =layer_model.predict_on_batch(X)
y_pred = torch.tensor(y_pred).cuda()
输出的部分就是:
tensorflow Tensor ----- pytorch Tensor gpu
△ GAP与全连接的作用
下面是另一部分的学习:全连接和GAP的区别。
先说下全连接的作用,虽然现在大家都用了卷积代替全连接,但是我觉得还是值得在思考看看的。
全连接的作用是什么和缺点?
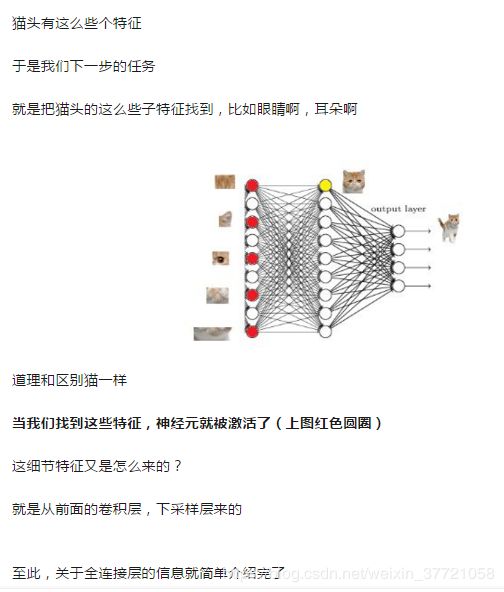
1.全连接层(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。
在卷积神经网络尚未火热的年代,人们使用haar/lbp + adaboost级连的组合方式检测人脸,hog+svm的组合方式检测行人。这种传统的目标检测方法一个认知上的优势就是: 模块的功能明确,划分得很清晰,符合人们的理解方式。其中,haar,lbp,hog等手工设计的特征提取算子用于提取特征,adaboost,svm用于对提取的特征分类。而早期的全连接神经网络,就是属于用于对提取的特征进行分类的模块,我们也可以同样将神经网络替换掉adaboost,svm用于分类。
但是全连接的参数过于庞大,因为全连接其实也相当于卷积的过程。可以看到是如下的:比如我们卷积层是7x7x512的输出,为了的得到4096的全连接点,则可用卷积核为7x7x512x4096的全局卷积来实现这一全连接运算过程。巨大让我害怕。。。。。下面是操作的例子,这个例子也可以让我们更好知道如何计算模型训练的参数计算,知道了这个我们也可以顺带理解了1*1卷积核是如何减少模型参数的:
以VGG-16为例,对224x224x3的输入,最后一层卷积可得输出为7x7x512,如后层是一层含4096个神经元的FC,则可用卷积核为7x7x512x4096的全局卷积来实现这一全连接运算过程,其中该卷积核参数如下:
“filtersize = 7, padding = 0, stride = 1, D_in = 512, D_out =4096”
经过此卷积操作后可得输出为1x1x4096。如需再次叠加一个2048的FC,则可设定参数为“filter size = 1,padding = 0, stride = 1, D_in = 4096, D_out = 2048”的卷积层操作。
竟然可以用卷积代替全连接,人们就提出了用GAP替代全连接。
△ GAP在操作
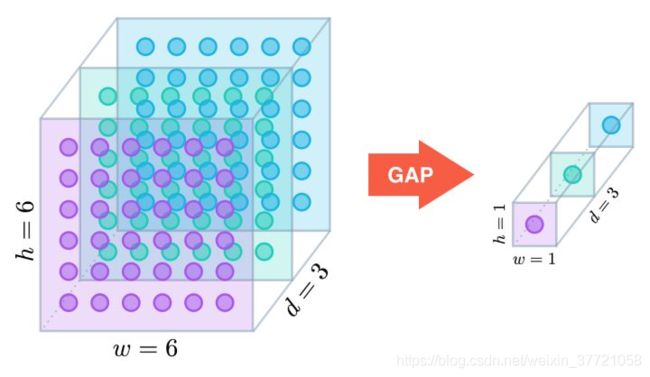
全局平均池化层:通过降低模型的参数数量来最小化过拟合效应。类似最大池化层,GAP层可以用来降低三维张量的空间维度。通过GAP 可以将你的特征图降低到你想要的大小,而这里如果是用作替代全连接的作用的话就是 :一个h × w × d的张量会被降维至1 × 1 × d。GAP层通过取平均值映射每个h × w的特征映射至单个数字。
在最早使用GAP的网络结构中,最大池化层的输出传入到了GAP层中,GAP层生成一个向量,这个向量相当于全连接层,起到了前面讲的分类作用。接着应用softmax激活函数生成每个分类的预测概率。好吧,你是全连接没错了。而在我接触的模型中有个resnet50. ResNet-50模型没这么激进;并没有完全移除密集层,而是在GAP层之后加上一个带softmax激活函数的密集层,生成预测分类。

注意,和VGG-16模型不同,并非大部分可训练参数都位于网络最顶上的全连接层中。
网络最后的Activation、AveragePooling2D、Dense层是我们最感兴趣的(上图高亮部分)。实际上AveragePooling2D层是一个GAP层!
我们从Activation层开始。这一层包含2048个7 × 7维的激活映射。让我们用fk表示第k个激活映射,其中k ∈{1,…,2048}。
接下来的AceragePooling2D层,也就是GAP层,通过取每个激活映射的平均值,将前一层的输出大小降至(1,1,2048)。接下来的Flatten层只不过是扁平化输入,没有导致之前GAP层中包含信息的任何变动。
ResNet-50预测的每个目标类别对应最终的Dense层的每个节点,并且每个节点都和之前的Flatten层的各个节点相连。让我们用wk表示连接Flatten层的第k个节点和对应预测图像类别的输出节点的权重。
全连接的补充
关于全连接需要再品味下,可以更好的了解网络的处理。虽然GAP可以用来替代全连接,但是更好的了解全连接的本质才可以更好的进行替代。
第一句话:
分布式特征representation映射到样本标记空间,将不同位置的特征最后整合成一个数值,如果是1000类,那么最后就有1000类的特征,1000个数值。放到softmax中就可以分类出1000个。每个数值都有一个概率,概率高的则别归为该类。
因为空间结构特性被忽略了,所以全连接层不适合用于在方位上找Pattern的任务,比如segmentation。
打破空间的性,模型自己去寻找类别的特征,进行全连接,然后用softmax 加 损失函数促进学习即可。多层以上的全连接,可以分布式特征之间的解决非线性问题。