Flink笔记03——一文了解DataStream
前言
在前面的博客Flink笔记01——入门篇中,我们提到了Flink 常用的API,如下图所示:

这篇博客,南国主要讲述一下Flink的DataStream。
DataStream的编程模型
DataSTream的编程模型包括4个部分:Environment,DataSource,Transformation,SInk。
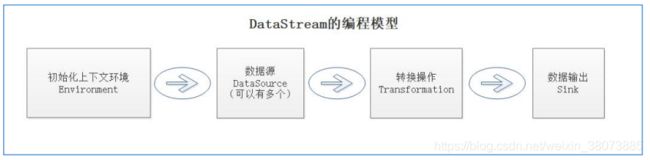
构建上下文环境Environment 比较简单,而且之前南国也说过了,主要分为构建DataStream 实时计算和DataSet做批计算。
DataStream的数据源
基于文件的Source
这里还可以分为读取本地文件系统的数据和基于HDFS中的数据,一般而言我们会把数据源放在HDFS中。
为了内容的全面,南国这里简单写了个读取本地文件的demo:
def main(args: Array[String]): Unit = {
//1.初始化flink 流计算的环境
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//2.导入隐式转换
import org.apache.flink.streaming.api.scala._
//3.读取数据
val stream = streamEnv.readTextFile("/wordcount.txt")
//DataStream类同于sparkStreaming中的DStream
//4.转换和处理数据
val result = stream.flatMap(_.split(" "))
.map((_, 1))
.keyBy(0) //分组算子 0或者1代表前面DataStream的下标,0代表单词 1代表出现的次数
.sum(1) //聚合累加
//5.打印结果
result.print("结果")
//6.启动流计算程序
streamEnv.execute("wordcount")
}
关于读取HDFS的数据源,首先需要再项目工程文件中加入Hadoop相关的依赖:
org.apache.hadoop
hadoop-common
${hadoop.version}
org.apache.hadoop
hadoop-client
${hadoop.version}
demo:
def main(args: Array[String]): Unit = {
//1.初始化flink 流计算的环境
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//2.导入隐式转换
import org.apache.flink.streaming.api.scala._
//3.读取数据
val stream = streamEnv.readTextFile("hdfs://hadoop101:9000/wc.txt")
//DataStream类同于sparkStreaming中的DStream
//4.转换和处理数据
val result = stream.flatMap(_.split(" "))
.map((_, 1))
.keyBy(0) //分组算子 0或者1代表前面DataStream的下标,0代表单词 1代表出现的次数
.sum(1) //聚合累加
//5.打印结果
result.print("结果")
//6.启动流计算程序
streamEnv.execute("wordcount")
}
看完 大家是否发现 基于文件的数据源的代码几乎一样,只是在stream.readTextFile(“path”),更改了path。
基于集合的source
def main(args: Array[String]): Unit = {
//初始化Flink的Streaming(流计算)上下文执行环境
val streamEnv = StreamExecutionEnvironment.getExecutionEnvironment
//导入隐式转换,
import org.apache.flink.streaming.api.scala._ //读取数据
var dataStream =streamEnv.fromCollection(Array(
new StationLog("001","186","189","busy",1577071519462L,0),
new StationLog("002","186","188","busy",1577071520462L,0),
new StationLog("003","183","188","busy",1577071521462L,0),
new StationLog("004","186","188","success",1577071522462L,32)
))
dataStream.print()
streamEnv.execute()
}
简单来说,就是在代码中手动创建集合来作为DataStream的数据源 进行测试。
基于kafka的数据源
首先添加Kafka的相关依赖:
org.apache.flink
flink-connector-kafka_2.11
1.9.1
1.读取kafka中的string类型数据
package com.flink.primary.DataSource
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.kafka.common.serialization.StringDeserializer
/**
* 读取kafka中的普通数据 String
* flink连接kafka比较 sparkStreaming来说更加简单(SparkStreaming来凝结kafka有Receiver Direct两种模式等等)
* @author xjh 2020.4.5
*/
object kafka_Source_String {
def main(args: Array[String]): Unit = {
//1.初始化flink 流计算的环境
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//2.导入隐式转换
import org.apache.flink.streaming.api.scala._
//连接kafka
val properties = new Properties()
properties.setProperty("bootstrap.servers", "m1:9092,m2:9092,m3:9093")
properties.setProperty("groupid", "Flink_project")
properties.setProperty("key.deserializer", classOf[StringDeserializer].getName)
properties.setProperty("value.deserializer", classOf[StringDeserializer].getName)
properties.setProperty("auto.offset.reset", "latest")
//设置kafka数据源,这里kafka中的数据是String
val stream = streamEnv.addSource(new FlinkKafkaConsumer[String]("t_test", new SimpleStringSchema(), properties))
stream.print()
streamEnv.execute()
}
}
2.读取kafka中的键值对数据
package com.flink.primary.DataSource
import java.util.Properties
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer, KafkaDeserializationSchema}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.flink.streaming.api.scala._
/**
* 读取kafka中的key/value数据
* @author xjh 2020.4.6
*/
object kafka_Source_keyValue {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
//连接kafka
val properties = new Properties()
properties.setProperty("bootstrap.servers", "m1:9092,m2:9092,m3:9093")
properties.setProperty("groupid", "Flink_project")
properties.setProperty("key.deserializer", classOf[StringDeserializer].getName)
properties.setProperty("value.deserializer", classOf[StringDeserializer].getName)
properties.setProperty("auto.offset.reset", "latest")
val stream = environment.addSource(new FlinkKafkaConsumer[(String, String)](
"t_topic", new MyKafkaReader, properties
))
stream.print()
environment.execute("Kafka_keyValue")
}
}
package com.flink.primary.DataSource
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.streaming.api.scala.{createTuple2TypeInformation, createTypeInformation}
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema
import org.apache.kafka.clients.consumer.ConsumerRecord
/**
* 自定义一个用于读取kafka中key value数据的flink程序输入源
* @author xjh 2020.4.6
*/
class MyKafkaReader extends KafkaDeserializationSchema[(String, String)] {
//流是否结束
override def isEndOfStream(t: (String, String)): Boolean = false
//反序列化
override def deserialize(consumerRecord: ConsumerRecord[Array[Byte], Array[Byte]]): (String, String) = {
if (consumerRecord != null) {
var key = ""
var value = ""
if (consumerRecord.key() != null) {
key = new String(consumerRecord.key(), "utf-8")
}
if (consumerRecord.value() != null) {
value = new String(consumerRecord.value(), "utf-8")
}
(key, value)
} else {
// 如果kafka中的数据为空,择返回一个固定的二元组
("", "")
}
}
//指定类型
override def getProducedType: TypeInformation[(String, String)] = {
createTuple2TypeInformation(createTypeInformation[String], createTypeInformation[String])
//指定Key value都是String
}
}
自定义数据源
除非上述提到的集种数据源,开发者还可以自定义数据源,有两种方式实现:
- 通过实现 SourceFunction 接口来自定义无并行度(也就是并行度只能为 1)的 Source。
- 通过实现 ParallelSourceFunction 接口或者继承 RichParallelSourceFunction 来自 定义有并行度的数据源。
这里,我们写了一个实现SourceFunction接口的demo。
package com.flink.primary.DataSource
import java.util.Random
import org.apache.flink.streaming.api.functions.source.SourceFunction
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
/**
* 用户自定义数据源
* 自定义的source。需求是每隔两秒钟,生成10条随机基站通话日志数据
* @author xjh 2020.4.6
*/
class MyCustomerSource extends SourceFunction[StationLog] {
var flag = true
override def cancel(): Unit = {
flag = false
}
/**
* 启动一个Source,并从中返回数据
* @param sourceContext
*/
override def run(sourceContext: SourceFunction.SourceContext[StationLog]): Unit = {
val random = new Random()
var types = Array("fail", "busy", "barring", "success")
while (flag) {
1.to(10).map(i => {
var callOut = "1320000%04d".format(random.nextInt(10000)) //主叫号码
var callIn = "1860000%04d".format(random.nextInt(10000)) //主叫号码
//生成一条数据
new StationLog(sid = "station_" + random.nextInt(), callOut, callIn, types(random.nextInt(4)), System.currentTimeMillis(), random.nextInt(10))
})
.foreach(sourceContext.collect(_)) //发送数据到流
Thread.sleep(2000)
}
}
//终止数据流
override def cancel(): Unit = {
flag=false
}
}
object CustomerSource {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.streaming.api.scala._
val stream = environment.addSource(new MyCustomerSource)
stream.print()
environment.execute()
}
}
DataStream的转换算子
转换算子transformation表示通过一个或者多个DataStream生成新的DataStream的过程,理解上其实和RDD中的转换操作是一样的。
DataStream在转换过程中,每种操作类型被定义为不同的 Operator,Flink 程序能够将多个 Transformation 组成一个 DataFlow 的拓扑。
map和flatMap算子
这两个算子的功能作用和Spark RDD中是一样的。
对于map,源码中如下所示:
/**
* Creates a new DataStream by applying the given function to every element of this DataStream.
*/
def map[R: TypeInformation](fun: T => R): DataStream[R] = {
if (fun == null) {
throw new NullPointerException("Map function must not be null.")
}
val cleanFun = clean(fun)
val mapper = new MapFunction[T, R] {
def map(in: T): R = cleanFun(in)
}
map(mapper)
}
调 用 用 户 定 义 的 MapFunction 对 DataStream[T] 数 据 进 行 处 理 , 形 成 新 的 DataStream[R],其中数据格式可能会发生变化,常用作对数据集内数据的清洗和转换。
对于flatMap,源码如下:
/**
* Creates a new DataStream by applying the given function to every element and flattening
* the results.
*/
def flatMap[R: TypeInformation](fun: T => TraversableOnce[R]): DataStream[R] = {
if (fun == null) {
throw new NullPointerException("FlatMap function must not be null.")
}
val cleanFun = clean(fun)
val flatMapper = new FlatMapFunction[T, R] {
def flatMap(in: T, out: Collector[R]) { cleanFun(in) foreach out.collect }
}
flatMap(flatMapper)
}
该算子主要应用处理输入一个元素产生一个或者多个元素的计算场景,比较常见的是在 经典例子 WordCount 中,将每一行的文本数据切割,生成单词序列如在图所示,对于输入 DataStream[String]通过 FlatMap 函数进行处理,字符串数字按逗号切割,然后形成新的整 数数据集。
需要注意的是,这里提到的map和flatMap的源码函数只是一些重写函数中的一个。也就是说相同函数名 根据他参数的不同 有多个函数。推荐大家再看源码的时候,结合自己平时经常使用的那个来进行分析。
filter算子
该算子将按照条件对输入数据集进行筛选操作,将符合条件的数据集输出,将不符合条 件的数据过滤掉。例如:val filter= dataStream.filter { _ % 2 == 0 }
源码如下:
/**
* Creates a new DataStream that contains only the elements satisfying the given filter predicate.
*/
def filter(fun: T => Boolean): DataStream[T] = {
if (fun == null) {
throw new NullPointerException("Filter function must not be null.")
}
val cleanFun = clean(fun)
val filterFun = new FilterFunction[T] {
def filter(in: T) = cleanFun(in)
}
filter(filterFun)
}
keyBy算子
源码如下:
/**
* Groups the elements of a DataStream by the given key positions (for tuple/array types) to
* be used with grouped operators like grouped reduce or grouped aggregations.
*/
def keyBy(fields: Int*): KeyedStream[T, JavaTuple] = asScalaStream(stream.keyBy(fields: _*))
该算子根据指定的 Key 将输入的 DataStream[T]数据格式转换为 KeyedStream[T],也就 是在数据集中执行 Partition 操作,将相同的 Key 值的数据放置在相同的分区中。
该算子的功能和RDD中的groupByKey很类似。
举了例子如下:
val dataStream = env.fromElements((1, 5),(2, 2),(2, 4),(1, 3))
//指定第一个字段为分区Key
val keyedStream: KeyedStream[(String,Int), Tuple] = dataStream.keyBy(0)
Reduce算子
我们首先找一个reduce的源码来看:
/**
* Creates a new [[DataStream]] by reducing the elements of this DataStream
* using an associative reduce function. An independent aggregate is kept per key.
*/
def reduce(fun: (T, T) => T): DataStream[T] = {
if (fun == null) {
throw new NullPointerException("Reduce function must not be null.")
}
val cleanFun = clean(fun)
val reducer = new ReduceFunction[T] {
def reduce(v1: T, v2: T) : T = { cleanFun(v1, v2) }
}
reduce(reducer)
}
该算子和MapReduce Spark中的原理基本一致,主要目的是将输入的 DataStream 通过 关联的Reduce Function 进 行数据聚合处理,其中定义的 ReduceFunciton 必须满足运算结合律和交换律。通过源码可以看到reduce算子的特点是DataStream的类型不变,得到的返回值类型也是 DataStream[T]。它可用于实时聚合。
下面的样例对传入DataStream中相同的key值的数据独立进行求和运算,得到每个 key 所对应的求和值。
val dataStream =streamEnv.fromElements(("a", 3), ("d", 4), ("c", 2), ("c",5), ("a", 5)) //指定第一个字段为分区Key
val keyedStream= dataStream.keyBy(0) //滚动对第二个字段进行reduce相加求和
val reduceStream = keyedStream.reduce { (t1, t2) => (t1._1, t1._2 + t2._2) }.print("reduce result:")
Aggregation算子
Aggregations 是 KeyedDataStream 接口提供的聚合算子,根据指定的字段进行聚合操 作,滚动地产生一系列数据聚合结果。其实是将 Reduce 算子中的函数进行了封装,封装的聚合操作有sum,min,max 等,这样就不需要用户自己定义 Reduce 函数。
如下代码所示,指定数据集中第一个字段作为 key,用第二个字段作为累加字段,然后滚动 地对第二个字段的数值进行累加并输出。
val KeyedStream=dataStream.keyBy(0)
val sumRes=KeyedStream.sum(1)
sumRes.print()
Union算子
Union 算子主要是将两个或者多个输入的数据集合并成一个数据集,需要保证两个数据 集的格式一致,输出的数据集的格式和输入的数据集格式保持一致。
//创建不同的数据集
val dataStream1: DataStream[(String, Int)] = env.fromElements(("a", 3), ("d", 4), ("c", 2), ("c", 5), ("a", 5)) val dataStream2: DataStream[(String, Int)] = env.fromElements(("d", 1), ("s", 2), ("a", 4), ("e", 5), ("a", 6)) val dataStream3: DataStream[(String, Int)] = env.fromElements(("a", 2), ("d", 1), ("s", 2), ("c", 3), ("b", 1)) //合并两个DataStream数据集
val unionStream = dataStream1.union(dataStream_02)
//合并多个DataStream数据集
val allUnionStream = dataStream1.union(dataStream2, dataStream3)
Cnnect CoMap CoFlatMap
Connect 算子主要是为了合并两种或者多种不同数据类型的数据集,合并后会保留原来 数据集的数据类型。例如:dataStream1 数据集为(String, Int)元祖类型,dataStream2 数据集为 Int 类型,通过 connect 连接算子将两个不同数据类型的流结合在一起,形成格式 为 ConnectedStreams 的数据集,其内部数据为[(String, Int), Int]的混合数据类型,保 留了两个原始数据集的数据类型。
//创建不同数据类型的数据集
val dataStream1: DataStream[(String, Int)] = env.fromElements(("a", 3), ("d", 4), ("c", 2), ("c", 5), ("a", 5)) val dataStream2: DataStream[Int] = env.fromElements(1, 2, 4, 5, 6)
//连接两个DataStream数据集
val connectedStream: ConnectedStreams[(String, Int), Int] = dataStream1.connect(dataStream2)
需要注意的是,对于ConnectedStreams 类型的数据集不能直接进行类似 Print()的操 作,需要再转换成 DataStream 类型数据集,在 Flink中ConnectedStreams 提供的 map()方法和flatMap()
object ConnectTransformation{
def main(args: Array[String]): Unit = {
//初始化Flink的Streaming(流计算)上下文执行环境
val streamEnv = StreamExecutionEnvironment.getExecutionEnvironment
//导入隐式转换
import org.apache.flink.streaming.api.scala._
//创建不同数据类型的数据集
val dataStream1: DataStream[(String, Int)] = streamEnv.fromElements(("a", 3), ("d", 4), ("c", 2), ("c", 5), ("a", 5))
val dataStream2: DataStream[Int] = streamEnv.fromElements(1, 2, 4, 5, 6)
//连接两个DataStream数据集
val connectedStream: ConnectedStreams[(String, Int), Int] = dataStream1.connect(dataStream2) //coMap函数处理
val result: DataStream[(Any, Int)] = connectedStream.map(
//第一个处理函数
t1 => {
(t1._1, t1._2)
},
//第二个处理函数
t2 => {
(t2, 0)
}
)
result.print()
streamEnv.execute()
}
}
注意Union和Cnnect的区别:
- Union 之前两个流的类型必须是一样,Connect 可以不一样,在之后的 coMap 中再去调 整成为一样的。
- Connect 只能操作两个流,Union 可以操作多个。
Split 和 select
Split 算子是将一个 DataStream 数据集按照条件进行拆分,形成两个数据集的过程, 也是 union 算子的逆向实现。每个接入的数据都会被路由到一个或者多个输出数据集中。
在使用 split 函数中,需要定义 split 函数中的切分逻辑,通过调用 split 函数,然后指定条件判断函数。
demo:将根据第二个字段的奇偶性将数据集标记出来,如 果是偶数则标记为 even,如果是奇数则标记为 odd,然后通过集合将标记返回,最终生成格 式 SplitStream 的数据集。
//创建数据集
val dataStream1: DataStream[(String, Int)] = env.fromElements(("a", 3), ("d", 4), ("c", 2), ("c", 5), ("a", 5)) //合并两个DataStream数据集
val splitedStream: SplitStream[(String, Int)] = dataStream1.split(t => if (t._2 % 2 == 0) Seq("even") else Seq("odd"))
split 函数本身只是对输入数据集进行标记,并没有将数据集真正的实现切分,因此需 要借助 Select 函数根据标记将数据切分成不同的数据集。如下代码所示,通过调用 SplitStream 数据集的 select()方法,传入前面已经标记好的标签信息,然后将符合条件的 数据筛选出来,形成新的数据集。
//筛选出偶数数据集
val evenStream: DataStream[(String, Int)] = splitedStream.select("even")
//筛选出奇数数据集
val oddStream: DataStream[(String, Int)] = splitedStream.select("odd")
//筛选出奇数和偶数数据集
val allStream: DataStream[(String, Int)] = splitedStream.select("even", "odd")
函数类和富函数类
上一小节中提到的算子几乎都可以自定义为一个函数类、富函数类。下面是关于二者的简单对比:
| 函数接口 | 富函数接口 |
|---|---|
| MapFunction | RichMapFunction |
| FlatMapFunction | RichFlatMapFunction |
| ReduceFunction | RichFilterFunction |
| … | … |
富函数接口它其他常规函数接口的不同在于:可以获取运行环境的上下文,在上下文环境中可以管理状态,并拥有一些生命周期方法,所以可以实现更复杂的功能。
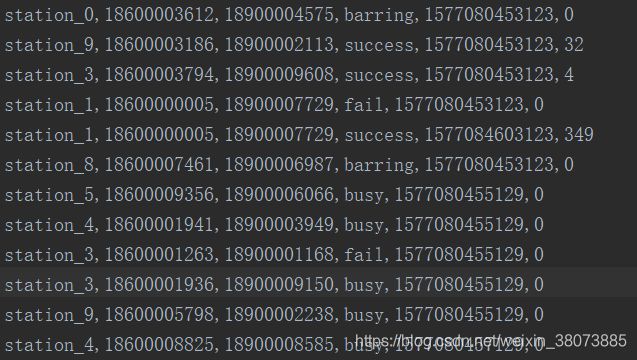
1.普通函数demo:按照指定的时间格式输出每个通话的拨号时间和结束时间
数据如下所示:
//按照指定的时间格式输出每个通话的拨号时间和结束时间
object FunctionClassTransformation {
def main(args: Array[String]): Unit = {
//初始化Flink的Streaming(流计算)上下文执行环境
val streamEnv: StreamExecutionEnvironment =StreamExecutionEnvironment.getExecutionEnvironment
//导入隐式转换
import org.apache.flink.streaming.api.scala._ //读取文件数据
val data =streamEnv.readTextFile(getClass.getResource("/station.log").getPath)
.map(line=>{
var arr =line.split(",")
new StationLog(arr(0).trim,arr(1).trim,arr(2).trim,arr(3).trim,arr(4).trim.toLong,arr(5).trim.to Long) })
//定义时间输出格式
val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
//过滤那些通话成功的
data.filter(_.callType.equals("success"))
.map(new CallMapFunction(format))
.print()
streamEnv.execute()
}
//自定义的函数类
class CallMapFunction(format: SimpleDateFormat) extends MapFunction[StationLog,String]{
override def map(t: StationLog): String = {
var strartTime=t.callTime; var endTime =t.callTime + t.duration*1000 "主叫号码:"+t.callOut +",被叫号码:"+t.callIn+",呼叫起始时 间:"+format.format(new Date(strartTime))+",呼叫结束时间:"+format.format(new Date(endTime))
}
}
}
2.富函数类demo:把呼叫成功的通话信息转化成真实的用户姓名,通话用户对应的用户表 (在 Mysql 数据中)为:
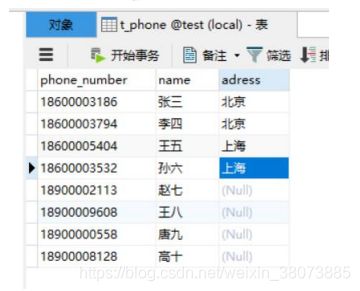
由于需要从数据库中查询数据,就需要创建连接,创建连接的代码必须写在生命周期的 open 方法中。所以需要使用富函数类。
Rich Function 有一个生命周期的概念。典型的生命周期方法有:
- open()方法是 rich function 的初始化方法,当一个算子例如 map 或者 filter 被调用 之前 open()会被调用。
- close()方法是生命周期中的最后一个调用的方法,做一些清理工作。
- getRuntimeContext()方法提供了函数的 RuntimeContext 的一些信息,例如函数执行的 并行度,任务的名字,以及 state 状态
//转换电话号码的真实姓名
object RichFunctionClassTransformation {
def main(args: Array[String]): Unit = {
//初始化Flink的Streaming(流计算)上下文执行环境
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//导入隐式转换
import org.apache.flink.streaming.api.scala._
//读取文件数据
val data = streamEnv.readTextFile(getClass.getResource("/station.log").getPath)
.map(line=>{
var arr =line.split(",")
new StationLog(arr(0).trim,arr(1).trim,arr(2).trim,arr(3).trim,arr(4).trim.toLong,arr(5).trim.to Long)
})
//过滤那些通话成功的
data.filter(_.callType.equals("success"))
.map(new CallRichMapFunction())
.print()
streamEnv.execute()
}
//自定义的富函数类
class CallRichMapFunction() extends RichMapFunction[StationLog,StationLog]{
var conn:Connection =_ var pst :PreparedStatement =_
//生命周期管理,初始化的时候创建数据连接
override def open(parameters: Configuration): Unit = {
conn=DriverManager.getConnection("jdbc:mysql://localhost/test","root","123123")
pst=conn.prepareStatement("select name from t_phone where phone_number=?")
}
override def map(in: StationLog): StationLog = {
//查询主叫用户的名字
pst.setString(1,in.callOut) val set1: ResultSet = pst.executeQuery() if(set1.next()){ in.callOut=set1.getString(1) }
//查询被叫用户的名字
pst.setString(1,in.callIn)
val set2: ResultSet = pst.executeQuery()
if(set2.next()){
in.callIn=set2.getString(1)
}
in
}
//关闭连接
override def close(): Unit = {
pst.close()
conn.close()
}
}
}
数据输出Sink
Flink 针对 DataStream 提供了大量的已经实现的数据目标(Sink),包括文件、Kafka、 Redis、HDFS、Elasticsearch 等等。
基于HDFS的Sink
首先配置支持Hadoop FileSystem的依赖
org.apache.flink
flink-connector-filesystem_2.11
1.9.1
Streaming File Sink 能把数据写入 HDFS 中,还可以支持分桶写入,每一个分桶就对应HDFS中的一个目录。默认按照小时来分桶,在一个桶内部,会进一步将输出基于滚动策略切分成更小的文件。这有助于防止桶文件变得过大。滚动策略也是可以配置的,默认 策 略会根据文件大小和超时时间来滚动文件,超时时间是指没有新数据写入部分文件(part file)的时间。
我们来看下面这个demo
package com.flink.primary.Sink
import com.flink.primary.DataSource.{MyCustomerSource, StationLog}
import com.typesafe.sslconfig.ssl.ClientAuth.Default
import org.apache.flink.api.common.serialization.SimpleStringEncoder
import org.apache.flink.core.fs.Path
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
/**
* 将自定义的Source作为数据源,把基站入职数据写入HDFS并且每两秒钟生成一个文件
* @author xjh 2020.4.6
*/
object HDFS_Sink {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.streaming.api.scala._
//读取数据
val stream = environment.addSource(new MyCustomerSource)
//分桶:默认一个小时一个目录
//设置一个滚动策略
val builder: DefaultRollingPolicy[StationLog, String] = DefaultRollingPolicy.create()
.withInactivityInterval(2000) //不活动的分桶事件
.withRolloverInterval(2000) //每个两秒钟生成一个文件
.build() //创建
//创建HDFS的Sink
val hdfsSink = StreamingFileSink.forRowFormat[StationLog](
new Path("hdfs://m1:9000/textSink001/"),
new SimpleStringEncoder[StationLog]("utf-8"))
.withBucketCheckInterval(2000) //检查间隔时间
.build()
stream.addSink(hdfsSink)
environment.execute()
}
}
基于Redis的Sink
首先配置Redis的依赖:
org.apache.bahir
flink-connector-redis_2.11
1.0
将单词技术的结果写入键值数据库Redis中:
def main(args: Array[String]): Unit = {
//初始化Flink的Streaming(流计算)上下文执行环境
val streamEnv= StreamExecutionEnvironment.getExecutionEnvironment
streamEnv.setParallelism(1)
//导入隐式转换
import org.apache.flink.streaming.api.scala._
//读取数据
val stream = streamEnv.socketTextStream("hadoop101",8888)
//转换计算
val result = stream.flatMap(_.split(",")) .map((_, 1)) .keyBy(0) .sum(1)
//连接redis的配置
val config = new FlinkJedisPoolConfig.Builder()
.setDatabase(1).setHost("hadoop101").setPort(6379).build()
//写入redis
result.addSink(new RedisSink[(String, Int)](config,new RedisMapper[(String, Int)] {
override def getCommandDescription = new RedisCommandDescription(RedisCommand.HSET,"t_wc")
override def getKeyFromData(data: (String, Int)) = { data._1 //单词
}
override def getValueFromData(data: (String, Int)) = {
data._2+"" //单词出现的次数
}
}))
streamEnv.execute()
}
基于kafka的sink
demo1:
package com.flink.primary.Sink
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer
/**
* 把netcat数据源中每个单词(String)写入kafka中
* @author xjh 2020.4.6
*/
object kafka_Sink_String {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.streaming.api.scala._
val stream = environment.socketTextStream("m1", 8888)
val wc= stream.flatMap(_.split(" "))
wc.addSink(new FlinkKafkaProducer[String]("m1:9092,m2:9092,m3:9092","t_2020",new SimpleStringSchema()))
environment.execute("kafka_sink")
}
}
demo2:
package com.flink.primary.Sink
import java.lang
import java.util.Properties
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaProducer, KafkaSerializationSchema}
import org.apache.kafka.clients.producer.ProducerRecord
/**
* 把netcat作为输入源,将每个单词的统计结果(key/value)写入kafka中
* @author xjh 2020.4.6
*/
object kafka_sink_keyvalue {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.streaming.api.scala._
val stream = environment.socketTextStream("m1", 8888)
val result= stream.flatMap(_.split(" ")).map((_,1)).keyBy(0).sum(1)
//创建连接kafka的属性
val properties = new Properties()
properties.setProperty("bootstrap.servers","m1:9092,m2:9092,m3:9092")
//创建一个sink
val sink = new FlinkKafkaProducer[(String, Int)](
"t_topic",
new KafkaSerializationSchema[(String, Int)] { //自定义的匿名内部类
override def serialize(t: (String, Int), aLong: lang.Long): ProducerRecord[Array[Byte], Array[Byte]] = {
new ProducerRecord("t_topic", t._1.getBytes, (t._2 + "").getBytes())
}
},
properties,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE //精确一次
)
result.addSink(sink)
environment.execute("kafka_keyValue")
}
}
自定义的sink
定义 Sink有两种实现方式:1、实现 SinkFunction 接口。2、实现 RichSinkFunction 类。
后者增加了生命周期的管理功能。比如需要在 Sink 初始化的时候创 建连接对象,则最好使用第二种。
案例需求:把 StationLog 对象写入 Mysql 数据库中。
首先还是要添加相应的依赖:
mysql
mysql-connector-java
5.1.6
demo:
package com.flink.primary.Sink
import java.sql.{Connection, DriverManager, PreparedStatement}
import com.flink.primary.DataSource.{MyCustomerSource, StationLog}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
/**
* 随机生成stationLog对象,写入mysql数据库中
* @author xjh 2020.4.6
*/
object CustomerJDBCSink {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.streaming.api.scala._
val stream = environment.addSource(new MyCustomerSource)
//数据写入mysql 需要创建一个自定义的sink
stream.addSink(new MyCustomerJDBCSink)
environment.execute("JDBC_sink")
}
}
/**
* 自定义一个Sink写入MySQL
*/
class MyCustomerJDBCSink extends RichSinkFunction[StationLog]{
var conn:Connection =_
var pst :PreparedStatement =_
//生命周期管理,在Sink初始化的时候调用
override def open(parameters: Configuration): Unit = {
conn=DriverManager.getConnection("jdbc:mysql://localhost:3305/xjh","root","123456")
pst=conn.prepareStatement("insert into t_station_log " +
"(sid,call_out,call_in,call_type,call_time,duration) values (?,?,?,?,?,?)") //这里的?是占位符,invoke函数用于给他赋值
}
//把StationLog 写入到表t_station_log
override def invoke(value: StationLog, context: SinkFunction.Context[_]): Unit = {
pst.setString(1,value.sid)
pst.setString(2,value.callOut)
pst.setString(3,value.callIn)
pst.setString(4,value.callType)
pst.setLong(5,value.callTime)
pst.setLong(6,value.duration)
pst.executeUpdate()
}
override def close(): Unit = {
pst.close()
conn.close()
}
}
参考资料:
1.尚学堂大数据技术Flink教案