pointpillars代码阅读-----架构篇
Brief
目前已经理论知识丰富,但是实践很少,因此决定在这两周内,做以下两件事:
- 阅读pointpillars代码,侧重点在理解怎么在nuscence上进行多目标检测的。并写笔记。
- 完成以下网络的搭建:(也即是是voxel的检测)
这一部分主要是大体架构,后续的博客是针对细节的博客。
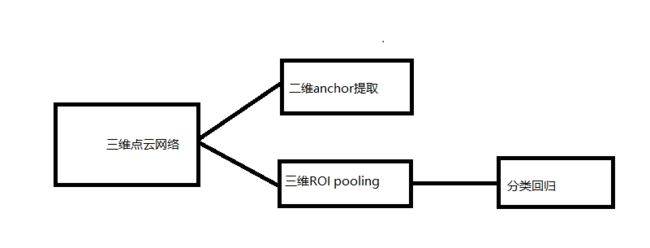
1 pointpillars代码
1.1 简单介绍
这里是 pytorch的版本
这个版本已经升级到了V2.0,也就是加入了nuscence的检测任务,同时SECOND的稀疏卷积也改变成作者的写法。
kitti数据集在官网上下载就行了;
nuscence的数据在 这里。
所有的代码如下:其中second是最重要的,核心代码在second/pytorch下面
1.2 代码阅读
- 写在前面
(1)博主从未自己搭过网络,下面的理解仅仅是个人的思考,如果有问题,希望大家指出。
(2)博主目前想要研究该代码是如何进行多类检测任务的,因此选择的config文件为:all.fhd.config
- 运行程序:
python create_data.py kitti_data_prep --data_path=KITTI_DATASET_ROOT
然后开始debug:
- 部分1:创建模型保存地址,读取预处理后的数据形式:
model_dir = str(Path(model_dir).resolve())
if create_folder:
if Path(model_dir).exists():
model_dir = torchplus.train.create_folder(model_dir)
model_dir = Path(model_dir)
if not resume and model_dir.exists():
raise ValueError("model dir exists and you don't specify resume.")
model_dir.mkdir(parents=True, exist_ok=True)
if result_path is None:
result_path = model_dir / 'results'
config_file_bkp = "pipeline.config"
if isinstance(config_path, str):
# directly provide a config object. this usually used
# when you want to train with several different parameters in
# one script.
config = pipeline_pb2.TrainEvalPipelineConfig()
with open(config_path, "r") as f:
proto_str = f.read()
text_format.Merge(proto_str, config)
else:
config = config_path
proto_str = text_format.MessageToString(config, indent=2)
with (model_dir / config_file_bkp).open("w") as f:
f.write(proto_str)
input_cfg = config.train_input_reader
eval_input_cfg = config.eval_input_reader
model_cfg = config.model.second
train_cfg = config.train_config
- 第二部分:建立网络
net = build_network(model_cfg, measure_time).to(device)
- 第三部分:加载检测目标文件和voxel生成器
target_assigner = net.target_assigner
voxel_generator = net.voxel_generator
这里的分类目标包括有 [ c a r , p e d e s t r a i n , c y c l i s t , v a n ] [car,pedestrain,cyclist,van] [car,pedestrain,cyclist,van],同时的四类检测问题,以前分别对一种做检测时,需要设置同一种的anchor_size,然后只需要做二分类任务,如果是多类检测,应该需要如上四种不同类别的anchor和不同的size,在随后的检测时需要输出其对应的类别。
- 第四部分:设置优化器和损失函数
optimizer_cfg = train_cfg.optimizer
loss_scale = train_cfg.loss_scale_factor
fastai_optimizer = optimizer_builder.build(
optimizer_cfg,
net,
mixed=False,
loss_scale=loss_scale)
损失函数是multi-loss的形式,包含了回归损失和分类损失,分类损失采用的是focal-loss
- 第五部分:输入数据的准备
dataset = input_reader_builder.build(
input_cfg,
model_cfg,
training=True,
voxel_generator=voxel_generator,
target_assigner=target_assigner,
multi_gpu=multi_gpu)
dataloader = torch.utils.data.DataLoader(
dataset,
batch_size=input_cfg.batch_size * num_gpu,
shuffle=True,
num_workers=input_cfg.preprocess.num_workers * num_gpu,
pin_memory=False,
collate_fn=collate_fn,
worker_init_fn=_worker_init_fn,
drop_last=not multi_gpu)
输出:remain number of infos: 3712;在前面预处理中,作者把训练数据和验证数据差不多55分;
- 第六部分:训练
for example in dataloader:
lr_scheduler.step(net.get_global_step())
。。。
(1)example 数据包括以下的内容。其中batch_size=3,很多shape前面的3也就是batch_size。
| 元素 | shape | 含义 |
|---|---|---|
| voxels | [54786,5,4] | 最大含有54786个voxels(54786是3个batch所有点的个数),每个点中最多5个点,每个点4个维度信息 |
| num_points | [54786,] | 一个batch中所有点的个数 |
| coordinates | [54786,4] | 每一个点对应的voxel坐标,4表示的是[bs,x,y,z] |
| num_voxels | [3,1] | 稀疏矩阵的参数[41,1280,1056] |
| metrics | list类型,长度为3,[gen_time,prep_time] | 衡量时间 |
| calib | dict类型,长度为3,[rect,Trv2c,P2] | 二维到点云变换矩阵 |
| anchors | [3,168960,7] | 3是bs,168960=1601328*4,7是回归维度 |
| gt_names | [67,] | 这里的67的含义是在这个batch中有67个gt,names={car,cyslist,pedestrain,car} |
| labels | [3,168960] | 每一个anchor的lable |
| reg_targes | [3,168960,7] | reg所对应的真实的gt |
| importance | [3,1689660] | |
| metadata | list,长度为3 |
解释一下16980的含义,最终经过中间层后提取的feature_map 大小是 [ 3 , 8 , 130 , 132 ] [3,8,130,132] [3,8,130,132]这里的8表示两个方向*4个类别,然后每一种anchor预测得到一个回归值和一个分类值,然后也就是 8 × 130 × 132 = 168960 8\times 130 \times 132=168960 8×130×132=168960;就是说,这个值是预先设定好的。
一些重要的函数如下
example_torch = example_convert_to_torch(example, float_dtype)
上面的函数把加载的example数据都转到gpu上,内容和变量
example是一样的。
ret_dict = net_parallel(example_torch)
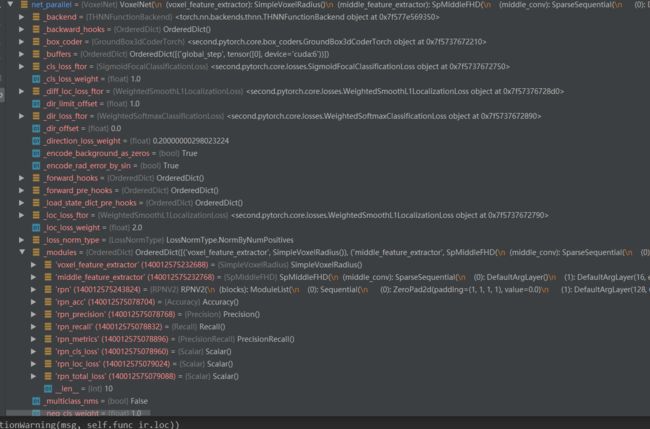
上述函数net_parallel是一个net,结构复杂,内容截图如下,重要的部分
(1)在models中,包含了特征提取层,特征中间层,rpn等一些loss
(2)上诉的这一句应该就是经过了一次这个网络。得到了ret_dict。
(3)ret_dict的内容如下图所示,可以看到含有很多的loss。做成表格看一下对应的shape如下:
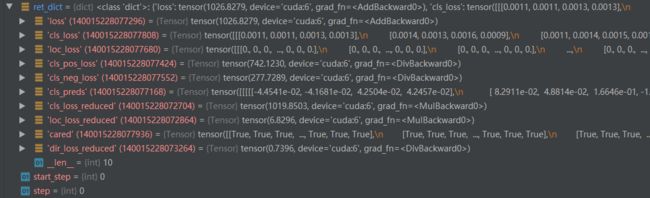
| attributes | shape | 含义 |
|---|---|---|
| loss | [,] | 一个float,总损失的和 |
| cls_loss | [3,168960,4] | 每一个anchor的预测分类损失,一共有4类 |
| loc_loss | [3,168960,7] | anchor的回归损失,维度损失? |
| cls_pos_loss | [,] | pos的anchor的损失 |
| cls_neg_loss | [,] | neg的anchor的损失 |
| cls_preds | [3,8,160,132,4] | 160 ×132 ×8=168960,表示每一个分类的得分 |
| cls_loss_reduced | [,] | 总损失/batch_size |
| cared | [3.168960] | 猜测是被判定为pos的anchor |
| loc_loss_reduced | [,] | |
| dir_loss_reduced | [,] | 方向预测损失 |
(4)然后从得到的这个dict中拿出对应的损失:
cls_preds = ret_dict["cls_preds"]
loss = ret_dict["loss"].mean()
cls_loss_reduced = ret_dict["cls_loss_reduced"].mean()
loc_loss_reduced = ret_dict["loc_loss_reduced"].mean()
cls_pos_loss = ret_dict["cls_pos_loss"].mean()
cls_neg_loss = ret_dict["cls_neg_loss"].mean()
loc_loss = ret_dict["loc_loss"]
cls_loss = ret_dict["cls_loss"]
labels = example_torch["labels"]
应该是取labels,shape[3,168960]对应着每一个anchor的label,应该和gt存在多大的IOU就会被认为是label为1的这种操作。
loss.backward()
反向传播。作者在代码中采用了
torch.nn.utils.clip_grad_norm_(net.parameters(), 10.0)使得最小的梯度至少都是10.采用optimizer.step()进行参数更新,
-
net_metrics = net.update_metrics(cls_loss_reduced,loc_loss_reduced, cls_preds, labels, cared)

可以看到,大致包含了两部分,其一是loss,其二是准确率
1.3 细节代码
从上面可以看出最重要的部分是net_parallel函数,因此第一个研读的就是这个网络架构
1.3.1 网络架构–net_parallel
反向追溯net_parallel网络的生成过程:
net_parallel→ \rightarrow →net→ \rightarrow →build_network(model_cfg, measure_time).to(device)→ \rightarrow →build→ \rightarrow →get_voxelnet_class
下面把build_network拿出来看一看:
def build_network(model_cfg, measure_time=False):
voxel_generator = voxel_builder.build(model_cfg.voxel_generator)
bv_range = voxel_generator.point_cloud_range[[0, 1, 3, 4]]
box_coder = box_coder_builder.build(model_cfg.box_coder)
target_assigner_cfg = model_cfg.target_assigner
target_assigner = target_assigner_builder.build(target_assigner_cfg,
bv_range, box_coder)
box_coder.custom_ndim = target_assigner._anchor_generators[0].custom_ndim
net = second_builder.build(
model_cfg, voxel_generator, target_assigner, measure_time=measure_time)
return net
依次讲一下觉得比较重要的函数:
voxel_generator = voxel_builder.build(model_cfg.voxel_generator)
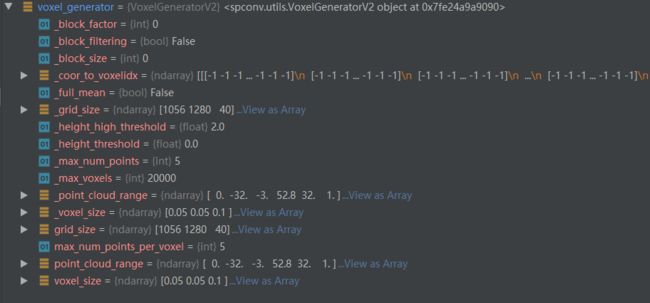
得到的
voxel_generator如下图所示,其中_coor_to_voxelidx的shape大小是[40,1280,1056],也就是对应的网格的size。整的来说,是第一步生成对应的voxel。
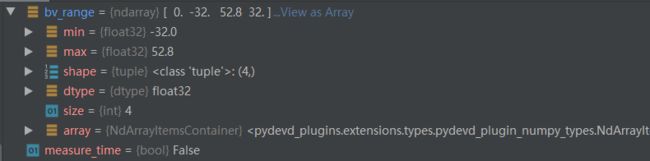
bv_range = voxel_generator.point_cloud_range[[0, 1, 3, 4]]
如下:
target_assigner = target_assigner_builder.build(target_assigner_cfg,bv_range, box_coder)
初始化一个“目标信息”的结构体:

net = second_builder.build(model_cfg, voxel_generator, target_assigner, measure_time=measure_time)
比较重要的一个生成网络的函数,second_builder.build函数如下:
(1)很大一堆配置信息,比如:网格size,分类类别,使用rotat_nms而不是mc_nms(区别在哪?)
vfe_num_filters = list(model_cfg.voxel_feature_extractor.num_filters)
vfe_with_distance = model_cfg.voxel_feature_extractor.with_distance
grid_size = voxel_generator.grid_size
dense_shape = [1] + grid_size[::-1].tolist() + [vfe_num_filters[-1]]
classes_cfg = model_cfg.target_assigner.class_settings
num_class = len(classes_cfg)
use_mcnms = [c.use_multi_class_nms for c in classes_cfg]
use_rotate_nms = [c.use_rotate_nms for c in classes_cfg]
。。。
(2)第二部分是Loss的权重参数:
losses = losses_builder.build(model_cfg.loss)
encode_rad_error_by_sin = model_cfg.encode_rad_error_by_sin
cls_loss_ftor, loc_loss_ftor, cls_weight, loc_weight, _ = losses
pos_cls_weight = model_cfg.pos_class_weight
neg_cls_weight = model_cfg.neg_class_weight
direction_loss_weight = model_cfg.direction_loss_weight
sin_error_factor = model_cfg.sin_error_factor
(3)硬核函数
get_voxelnet_class,最后被继承到函数voxelnet中
class VoxelNet(nn.Module):
def __init__(self,
output_shape,
num_class=2,
num_input_features=4,
vfe_class_name="VoxelFeatureExtractor",
vfe_num_filters=[32, 128],
with_distance=False,
middle_class_name="SparseMiddleExtractor",
middle_num_input_features=-1,
middle_num_filters_d1=[64],
middle_num_filters_d2=[64, 64],
rpn_class_name="RPN",
rpn_num_input_features=-1,
rpn_layer_nums=[3, 5, 5],
rpn_layer_strides=[2, 2, 2],
rpn_num_filters=[128, 128, 256],
rpn_upsample_strides=[1, 2, 4],
rpn_num_upsample_filters=[256, 256, 256],
use_norm=True,
use_groupnorm=False,
num_groups=32,
use_direction_classifier=True,
use_sigmoid_score=False,
encode_background_as_zeros=True,
use_rotate_nms=True,
multiclass_nms=False,
nms_score_thresholds=None,
nms_pre_max_sizes=None,
nms_post_max_sizes=None,
nms_iou_thresholds=None,
target_assigner=None,
cls_loss_weight=1.0,
loc_loss_weight=1.0,
pos_cls_weight=1.0,
neg_cls_weight=1.0,
direction_loss_weight=1.0,
loss_norm_type=LossNormType.NormByNumPositives,
encode_rad_error_by_sin=False,
loc_loss_ftor=None,
cls_loss_ftor=None,
measure_time=False,
voxel_generator=None,
post_center_range=None,
dir_offset=0.0,
sin_error_factor=1.0,
nms_class_agnostic=False,
num_direction_bins=2,
direction_limit_offset=0,
name='voxelnet'):
该函数按照顺序整理:
(1)一大推参数的获取:
self.name = name
self._sin_error_factor = sin_error_factor
self._num_class = num_class
self._use_rotate_nms = use_rotate_nms
self._multiclass_nms = multiclass_nms
self._nms_score_thresholds = nms_score_thresholds
self._nms_pre_max_sizes = nms_pre_max_sizes
self._nms_post_max_sizes = nms_post_max_sizes
self._nms_iou_thresholds = nms_iou_thresholds
。。。
(2)选择voxel_encoder,作者这里的采用的encode方式是
SimpleVoxelRadous,不是voxel的VFE也不是pointpillars的方式。
self.voxel_feature_extractor = voxel_encoder.get_vfe_class(vfe_class_name)(
num_input_features,
use_norm,
num_filters=vfe_num_filters,
with_distance=with_distance,
voxel_size=self.voxel_generator.voxel_size,
pc_range=self.voxel_generator.point_cloud_range,
)
(3)选择中间特征提取器,采用的是
SpMiddleFHD的方式
self.middle_feature_extractor = middle.get_middle_class(middle_class_name)(
output_shape,
use_norm,
num_input_features=middle_num_input_features,
num_filters_down1=middle_num_filters_d1,
num_filters_down2=middle_num_filters_d2)
(4)最后一个定义rpn网络,采用的是‘RPN2’
self.rpn = rpn.get_rpn_class(rpn_class_name)(
use_norm=True,
num_class=num_class,
layer_nums=rpn_layer_nums,
layer_strides=rpn_layer_strides,
num_filters=rpn_num_filters,
upsample_strides=rpn_upsample_strides,
num_upsample_filters=rpn_num_upsample_filters,
num_input_features=rpn_num_input_features,
num_anchor_per_loc=target_assigner.num_anchors_per_location,
encode_background_as_zeros=encode_background_as_zeros,
use_direction_classifier=use_direction_classifier,
use_groupnorm=use_groupnorm,
num_groups=num_groups,
box_code_size=target_assigner.box_coder.code_size,
num_direction_bins=self._num_direction_bins)
此后网络就建好了。。
1.3.2 三大网络
这一步剥丝抽茧,看看如何定义上面的三个网络:
SimpleVoxelRadius网络
这个好像非常简单,看它的forward,就知道在这里仅仅是做了一个局部信息cat,没有特征提取。
def forward(self, features, num_voxels, coors):
# features: [concated_num_points, num_voxel_size, 3(4)]
# num_voxels: [concated_num_points]
points_mean = features[:, :, :self.num_input_features].sum(
dim=1, keepdim=False) / num_voxels.type_as(features).view(-1, 1)
feature = torch.norm(points_mean[:, :2], p=2, dim=1, keepdim=True)
# z is important for z position regression, but x, y is not.
res = torch.cat([feature, points_mean[:, 2:self.num_input_features]],
dim=1)
SpMiddleFHD网络
看名字,应该是稀疏中间提取层。
(1)稀疏shape [ 41 , 1280 , 1056 ] [41,1280,1056] [41,1280,1056]和outshape [ 1 , 40 , 1280 , 1056 , 16 ] [1,40,1280,1056,16] [1,40,1280,1056,16]
sparse_shape = np.array(output_shape[1:4]) + [1, 0, 0]
self.voxel_output_shape = output_shape
(2)中间卷积层:
self.middle_conv = spconv.SparseSequential(
。。。
)
理解:
(1)作者没有VFE这种提取每一个voxel中的局部信息,而是直接采用了稀疏卷积作用在点云上。
(2)该部分包含了很多如下的block,第一个block域名是“subm0”:
SubMConv3d(num_input_features, 16, 3, indice_key="subm0"),
BatchNorm1d(16),
nn.ReLU(),
SubMConv3d(16, 16, 3, indice_key="subm0"),
BatchNorm1d(16),
nn.ReLU(),
SpConv3d(16, 32, 3, 2,
padding=1), # [1600, 1200, 41] -> [800, 600, 21]
BatchNorm1d(32),
其中第一个函数
SubMConv3d,完全继承了SparseConvolution,我们看看这个SparseConvolution,发现看不懂了,那么知道这个函数的意思就行了:理解成MLP吧,进去的是维度为3(不应该是7吗)的num_input_features,然后出来的是维度为16的特征。也就是:
[ 1600 , 1200 , 41 , 3 ] − > [ 1600 , 1200 , 41 , 16 ] − > [ 1600 , 1200 , 41 , 16 ] − > [ 800 , 600 , 21 , 32 ] [1600, 1200, 41,3] -> [1600, 1200, 41,16]-> [1600, 1200, 41,16]-> [800, 600, 21,32] [1600,1200,41,3]−>[1600,1200,41,16]−>[1600,1200,41,16]−>[800,600,21,32]
(3)接下来是第二个block ,tensor的变化如下:
[ 800 , 600 , 21 , 32 ] − > [ 800 , 600 , 21 , 32 ] − > [ 800 , 600 , 21 , 32 ] − > [ 400 , 300 , 11 , 64 ] [800, 600, 21,32] -> [800, 600, 21,32]-> [800, 600, 21,32]-> [400, 300, 11,64] [800,600,21,32]−>[800,600,21,32]−>[800,600,21,32]−>[400,300,11,64]
SubMConv3d(32, 32, 3, indice_key="subm1"),
BatchNorm1d(32),
nn.ReLU(),
SubMConv3d(32, 32, 3, indice_key="subm1"),
BatchNorm1d(32),
nn.ReLU(),
SpConv3d(32, 64, 3, 2,
padding=1), # [800, 600, 21] -> [400, 300, 11]
BatchNorm1d(64),
nn.ReLU(),
(4)接下来又是一个block:【一层sub+一层sub+一层sp】,也就是域名“subm2”:
SubMConv3d(64, 64, 3, indice_key="subm2"),
BatchNorm1d(64),
nn.ReLU(),
SubMConv3d(64, 64, 3, indice_key="subm2"),
BatchNorm1d(64),
nn.ReLU(),
SubMConv3d(64, 64, 3, indice_key="subm2"),
BatchNorm1d(64),
nn.ReLU(),
SpConv3d(64, 64, 3, 2,
padding=[0, 1, 1]), # [400, 300, 11] -> [200, 150, 5]
BatchNorm1d(64),
nn.ReLU(),
tensor的变化为: [ 400 , 300 , 11 , 64 ] − > [ [ 400 , 300 , 11 , 64 ] − > [ 800 , 600 , 21 , 64 ] − > [ 400 , 300 , 11 , 64 ] − > [ 200 , 150 , 5 , 64 ] [400, 300, 11,64]-> [[400, 300, 11,64]-> [800, 600, 21,64]-> [400, 300, 11,64]-> [200, 150, 5,64] [400,300,11,64]−>[[400,300,11,64]−>[800,600,21,64]−>[400,300,11,64]−>[200,150,5,64]
(6)接下来最后一个block:【一层sub+一层sub+一层sp】,也就是域名“subm3”:
SubMConv3d(64, 64, 3, indice_key="subm3"),
BatchNorm1d(64),
nn.ReLU(),
SubMConv3d(64, 64, 3, indice_key="subm3"),
BatchNorm1d(64),
nn.ReLU(),
SubMConv3d(64, 64, 3, indice_key="subm3"),
BatchNorm1d(64),
nn.ReLU(),
SpConv3d(64, 64, (3, 1, 1),
(2, 1, 1)), # [200, 150, 5] -> [200, 150, 2]
BatchNorm1d(64),
nn.ReLU(),
tensor的变化: [ 200 , 150 , 5 , 64 ] − > [ 200 , 150 , 5 , 64 ] − > [ 200 , 150 , 5 , 64 ] − > [ 200 , 150 , 5 , 64 ] − > [ 200 , 150 , 2 , 64 ] [200, 150, 5,64]->[200, 150, 5,64]-> [200, 150, 5,64]->[200, 150, 5,64]-> [200, 150, 2,64] [200,150,5,64]−>[200,150,5,64]−>[200,150,5,64]−>[200,150,5,64]−>[200,150,2,64],这一次最后的sp层的kernel是 [ ( 2 , 1 , 1 ) ] [(2,1,1)] [(2,1,1)],所以加上batch最后的tensior也就是 [ 3 , 200 , 150 , 2 , 64 ] [3,200,150,2,64] [3,200,150,2,64]
- ‘RPN2’网络
第一部分是首先下面是参数定义和获取:
super(RPNBase, self).__init__(
use_norm=use_norm,
num_class=num_class,
layer_nums=layer_nums,
layer_strides=layer_strides,
num_filters=num_filters,
。。。
self._num_anchor_per_loc = num_anchor_per_loc
self._num_direction_bins = num_direction_bins
self._num_class = num_class
self._use_direction_classifier = use_direction_classifier
self._box_code_size = box_code_size
第二部分是直接定义如下的最终操作,但是实际上因为这是一个继承函数,所以会先进行父类的操作。
self.conv_cls = nn.Conv2d(final_num_filters, num_cls, 1)
self.conv_box = nn.Conv2d(final_num_filters,
num_anchor_per_loc * box_code_size, 1)
self.conv_dir_cls = nn.Conv2d(
final_num_filters, num_anchor_per_loc * num_direction_bins, 1)
在
forward函数中,第一个是res = super().forward(x),所以看一看父类RPNNoHeadBase的结构:
for i, layer_num in enumerate(layer_nums):
block, num_out_filters = self._make_layer(
in_filters[i],
num_filters[i],
layer_num,
stride=layer_strides[i])
blocks.append(block)
大致知道这是一个很多个block组成的模块就可以了。
-
self.rpn_acc = metrics.Accuracy(dim=-1,encode_background_as_zeros=encode_background_as_zeros)
按名字,这应该是一个计算rpn准确率的模块。
同样,有如下的计算准确率和召回率和度量信息的模块:
self.rpn_precision = metrics.Precision(dim=-1)
self.rpn_recall = metrics.Recall(dim=-1)
self.rpn_metrics = metrics.PrecisionRecall(
dim=-1,
thresholds=[0.1, 0.3, 0.5, 0.7, 0.8, 0.9, 0.95],
use_sigmoid_score=use_sigmoid_score,
encode_background_as_zeros=encode_background_as_zeros)
1.3.3 voxelnet的forward函数
- forward三大层次结构
只写比较重要的函数,在net_forward函数中:
voxel_features = self.voxel_feature_extractor(voxels, num_points,coors)
spatial_features = self.middle_feature_extractor(voxel_features, coors, batch_size)
preds_dict = self.rpn(spatial_features)
return preds_dict
好精炼简介的表达,所以我准备用第一个debug一下,先去上课了0.0.
上课回来,准备debug:
(1)经过第一个函数得到的voxel_features内容如下,其对应的shape是 [ 53230 , 3 ] [53230,3] [53230,3],> 内部具体操作:(待补充)
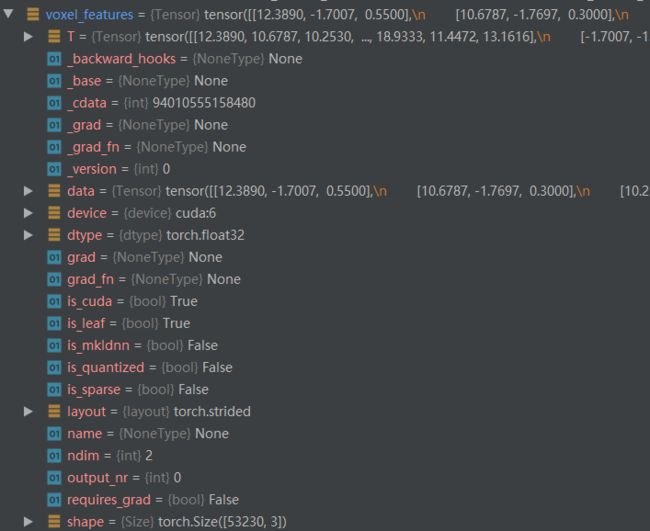
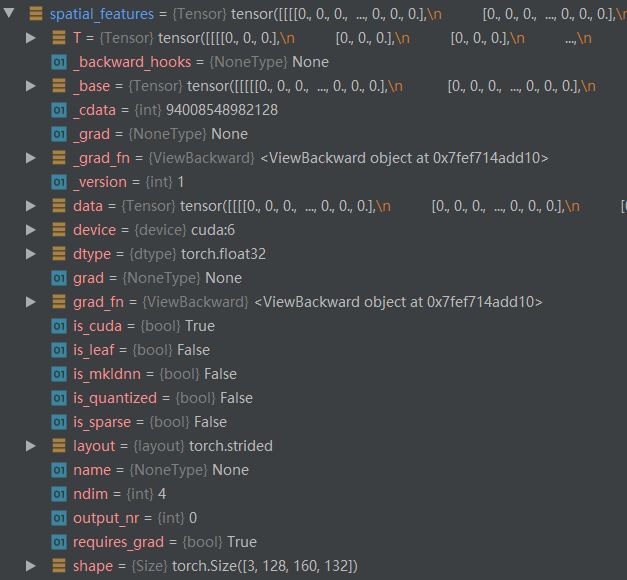
(2)经过第二个中间层得到的
spatial_features如下, 内部具体操作:(待补充)
(3)经过第三个rpn后得到的
preds_dict如下,内部具体操作:(待补充)
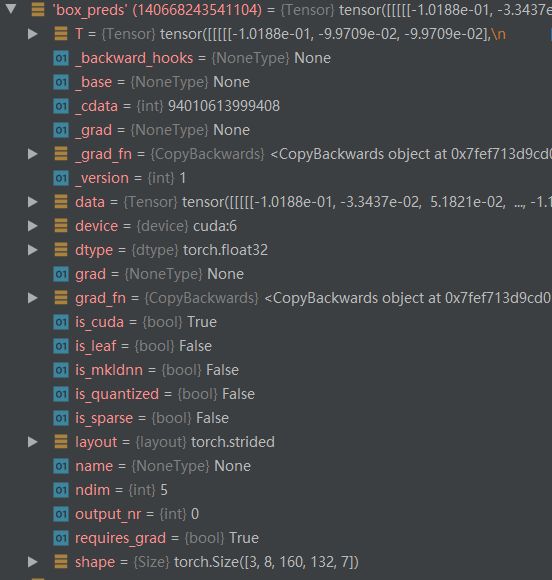
对box_preds,其对应的shape是: [ 3 , 8 , 160 , 132 , 7 ] [3,8,160,132,7] [3,8,160,132,7],也就是每一个anchor对应的回归框
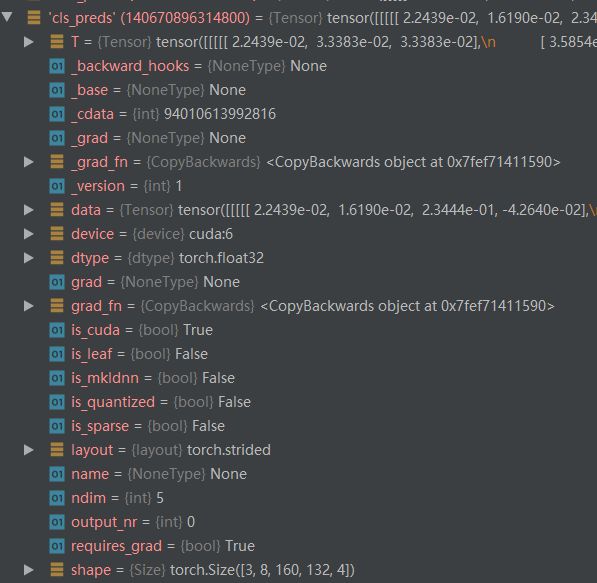
对cls_preds,也就对应着每一个anchor分类的类别信息
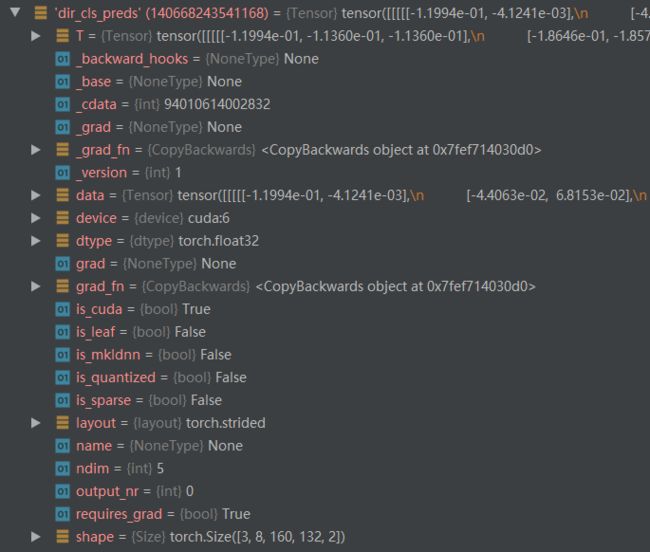
对dir_cls_preds,可能表示的是是否为前景或者背景的分类。

- 经过大体架构后面操作
(1)将
box_pred缩小为3维, [ 3 , 168960 , 7 ] [3,168960,7] [3,168960,7],计算一下:8×160×132=168960,这里就应当会有疑惑,按道理来说,anchor应该只在最底下一层才有,这为什么是voxel的个数?
box_preds = preds_dict["box_preds"].view(batch_size_dev, -1, self._box_coder.code_size)
(2)返回计算的loss:
return self.loss(example, preds_dict)
loss函数的定义如下,example是标准的真实gt,而
preds_dict是预测的结果,包括了以上的三个部分,分别是pred_box,cls_pred和前后背景预测。
def loss(self, example, preds_dict):
。。。
#取出预测得到的数据
box_preds = preds_dict["box_preds"]
cls_preds = preds_dict["cls_preds"]
#取出数据的gt
labels = example['labels']
reg_targets = example['reg_targets']
importance = example['importance']
#得到权重的加权系数-->cls_weights[3,168960].reg_weights-->[3,168960],cared-->[3,168960]
cls_weights, reg_weights, cared = prepare_loss_weights(
labels,
pos_cls_weight=self._pos_cls_weight,
neg_cls_weight=self._neg_cls_weight,
loss_norm_type=self._loss_norm_type,
dtype=box_preds.dtype)
#得到最后的cls_tragets:
cls_targets = labels * cared.type_as(labels)
cls_targets = cls_targets.unsqueeze(-1)
#
如上述代码中的过程,我们其中需要注意的权重系数:cls_weights[3,168960].reg_weights–>[3,168960],cared–>[3,168960](这一个内容是true和flase),最后为了得到
cls_targets,我们把cared加权到了labels上。
后面采用函数计算最终的loss:
loc_loss, cls_loss = create_loss(。。。)
如何计算loss,在上面这个函数之前进行很大一段铺垫,然后用下面这两个函数计算对应的损失值。
loc_losses = loc_loss_ftor(
box_preds, reg_targets, weights=reg_weights) # [N, M]
cls_losses = cls_loss_ftor(
cls_preds, one_hot_targets, weights=cls_weights) # [N, M]
(1)上面loc_loss_ftor是两个预先定义好的“计算器”。传入预测的结果“box_preds [ 3 , 168960 , 7 ] [3,168960,7] [3,168960,7]和reg_targets [ 3 , 168960 , 7 ] [3,168960,7] [3,168960,7]”和对应的每一个anchor的权重 [ 3 , 168960 ] [3,168960] [3,168960];得到的
loc_losses大小是 [ 3 , 168960 , 7 ] [3,168960,7] [3,168960,7]
(2)同样cls_loss_ftor传入的cls_preds [ 3 , 168960 , 4 ] [3,168960,4] [3,168960,4]和one_hot_targets(这个参数是真实的标签cls_targets–>独热编码) [ 3 , 168960 , 4 ] [3,168960,4] [3,168960,4];得到的cls_loss是 [ 3 , 168960 , 4 ] [3,168960,4] [3,168960,4].
如此就计算完了loss,但是具体的两个计算器(待补充)
- loss总览
res = {
"loss": loss,
"cls_loss": cls_loss,
"loc_loss": loc_loss,
"cls_pos_loss": cls_pos_loss,
"cls_neg_loss": cls_neg_loss,
"cls_preds": cls_preds,
"cls_loss_reduced": cls_loss_reduced,
"loc_loss_reduced": loc_loss_reduced,
"cared": cared,
}