使用Python中的OpenAI Gym进行深度Q-Learning的实践介绍
Introduction
我一直对游戏着迷。 看似无限的选择可以在紧迫的时间线下执行一个动作 - 这是一个惊心动魄的经历。 没有什么比得上它了。
因此,当我读到DeepMind想出的令人难以置信的算法(如AlphaGo和AlphaStar)时,我被迷住了。 我想学习如何在自己的机器上制作这些系统。 这使我进入深度强化学习的世界(Deep RL)。
即使您不参与游戏,Deep RL也很重要。 只需查看目前使用Deep RL进行研究的各种功能:

适合行业的应用程序呢? 好吧,这里有两个最常被引用的Deep RL用例:
- 谷歌的Cloud AutoML
- Facebook的Horizon Platform
Deep RL的范围是IMMENSE。 这是进入这一领域并从中创造事业的好时机。
在本文中,我的目标是帮助您迈出深度强化学习的第一步。 我们将使用RL中最流行的算法之一深度Q学习来了解RL的深度。 锦上添花? 我们将使用Python在一个很棒的案例研究中实现我们所有的学习。
Table of Contents
- The Road to Q-Learning
- Why ‘Deep’ Q-Learning?
- Introduction to Deep Q-Learning
- Challenges of Deep Reinforcement Learning as compared to Deep Learning
- Experience Replay
- Target Network
- Implementing Deep Q-Learning in Python using Keras & Gym
The Road to Q-Learning
在深入深层强化学习的深度之前,你应该注意一些概念。 别担心,我已经帮你了。
我之前写过关于强化学习的各种文章的各种文章,介绍了多臂强盗,动态规划,蒙特卡罗学习和时间差分等概念。 我建议按以下顺序浏览这些指南:
- Nuts & Bolts of Reinforcement Learning: Model-Based Planning using Dynamic Programming
- Reinforcement Learning Guide: Solving the Multi-Armed Bandit Problem from Scratch in Python
- Reinforcement Learning: Introduction to Monte Carlo Learning using the OpenAI Gym Toolkit
- Introduction to Monte Carlo Tree Search: The Game-Changing Algorithm behind DeepMind’s AlphaGo
- Nuts and Bolts of Reinforcement Learning: Introduction to Temporal Difference (TD) Learning
这些文章足以从一开始就详细了解基本RL。
但请注意,上面链接的文章绝不是读者理解Deep Q-Learning的先决条件。 在探索什么是深度Q-Learning及其实现细节之前,我们将快速回顾一下基本的RL概念。
RL Agent-Environment
强化学习任务是培训与其环境相互作用的代理。 代理通过执行操作到达称为状态的不同场景。 行动导致奖励可能是积极的和消极的。
代理人在这里只有一个目的 - 在一集中最大化其总奖励。 此剧集是环境中第一个州与最后一个或终端州之间发生的任何事情。 我们强化代理人以学习通过经验来执行最佳操作。 这是战略或政策。

让我们举一个极受欢迎的PubG游戏的例子:
- 士兵是这里与环境互动的代理人
- 状态正是我们在屏幕上看到的
- 一集是一个完整的游戏
- 动作是前进,后退,左,右,跳,鸭,射击等。
- 奖励是根据这些行动的结果确定的。 如果士兵能够杀死敌人,那么在被敌人射击时需要积极的奖励是负面的奖励
现在,为了杀死敌人或获得积极的奖励,需要采取一系列行动。 这就是延迟或延期奖励的概念发挥作用的地方。 RL的关键是学习如何执行这些序列并最大化奖励。
Markov Decision Process (MDP)
需要注意的重要一点 - 环境中的每个状态都是其先前状态的结果,而状态又是其先前状态的结果。 但是,即使对于短剧集的环境,存储所有这些信息也将变得不可行。
为了解决这个问题,我们假设每个状态都遵循Markov属性,即每个状态仅取决于先前的状态以及从该状态到当前状态的转换。 看看下面的迷宫,以更好地理解这是如何工作的直觉:
现在,有2个场景有2个不同的起点,并且代理遍历不同的路径以达到相同的倒数第二个状态。 现在,代理到达红色状态的路径无关紧要。 退出迷宫并到达最后状态的下一步是向右走。 显然,我们只需要关于红色/倒数第二个状态的信息来找出下一个最佳动作,这正是马尔可夫属性所暗示的。
Q Learning
假设我们知道每个步骤的每个动作的预期奖励。 这基本上就像是代理人的备忘单! 我们的代理人将确切知道要执行的操作。
它将执行最终将产生最大总奖励的一系列动作。 这个总奖励也被称为Q值,我们将我们的战略正式化为:
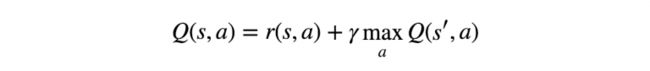
上述等式表明,处于状态s并且执行动作a的Q值是立即奖励r(s,a)加上可能来自下一状态s’的最高Q值。 这里的Gamma是折扣因素,它可以在未来进一步控制奖励的贡献。
Q(s’,a)再次取决于Q(s“,a),其将具有伽马平方的系数。 因此,Q值取决于未来状态的Q值,如下所示:
![]()
调整伽玛值将减少或增加未来奖励的贡献。
由于这是一个递归方程,我们可以从对所有q值进行任意假设开始。 凭借经验,它将汇聚到最优政策。 在实际情况中,这是作为更新实现的:
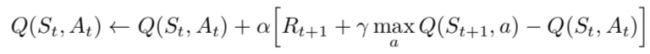
其中alpha是学习率或步长。这简单地确定了新获取的信息在多大程度上覆盖了旧信息。
##为什么’深入’Q-Learning?
Q-learning是一种简单但功能强大的算法,可以为我们的代理创建备忘单。这有助于代理确切地确定要执行的操作。
但如果这个备忘单太长了怎么办?想象一下,每个州拥有10,000个州和1,000个行动的环境。这将创建一个包含1000万个单元格的表。事情很快就会失控!
很明显,我们无法从已经探索过的状态推断新状态的Q值。这提出了两个问题:
- 首先,保存和更新该表所需的内存量会随着状态数量的增加而增加
- 其次,探索每个州创建所需Q表所需的时间是不现实的
这是一个想法 - 如果我们用机器学习模型(如神经网络)来近似这些Q值怎么办?嗯,这是DeepMind算法背后的想法,导致谷歌以5亿美元收购它!
Deep Q-Networks
在深度Q学习中,我们使用神经网络来近似Q值函数。给出状态作为输入,并且生成所有可能动作的Q值作为输出。 Q学习和深度Q学习之间的比较如下所示:

那么,使用深度Q学习网络(DQN)进行强化学习的步骤是什么?
- 所有过去的经验都由用户存储在内存中
- 下一个操作由Q网络的最大输出决定
- 这里的损失函数是预测的Q值和目标Q值 - Q *的均方误差。 这基本上是回归问题。 但是,由于我们正在处理强化学习问题,因此我们不知道目标或实际值。 回到从Bellman方程导出的Q值更新方程。 我们有:
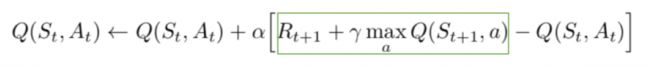
绿色部分代表目标。 我们可以争辩说它正在预测它自己的价值,但由于R是无偏见的真实奖励,网络将使用反向传播更新其梯度以最终收敛。
深度学习与深度学习相比的挑战
到目前为止,这一切看起来都很棒。 我们了解神经网络如何帮助代理人学习最佳行动。 然而,当我们将深度RL与深度学习(DL)进行比较时,存在挑战:
- 非静止或不稳定目标:让我们回到伪代码进行深度Q学习:

正如您在上面的代码中看到的那样,目标随着每次迭代而不断变化。在深度学习中,目标变量不会改变,因此训练是稳定的,这对于RL来说是不正确的。
总而言之,我们通常依靠强化学习中的政策或价值函数来抽样行动。然而,随着我们不断学习探索什么,这种情况经常发生变化。当我们玩游戏时,我们会更多地了解状态和动作的基本真值,因此输出也在变化。
因此,我们尝试学习映射以不断变化的输入和输出。但那么解决方案是什么?
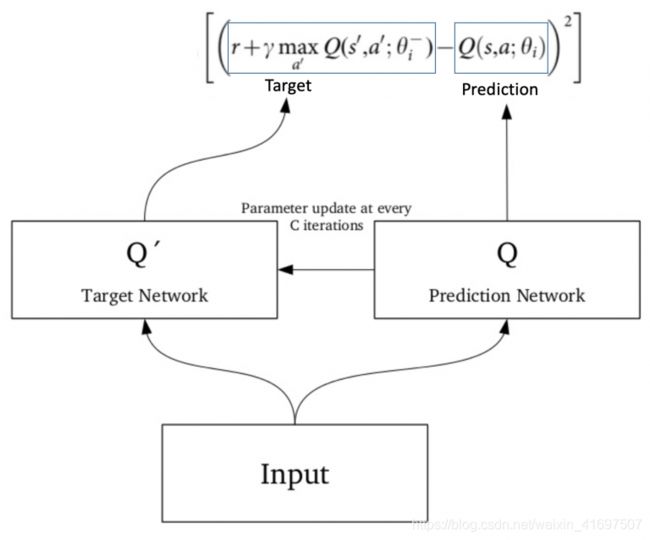
1目标网络
由于同一网络正在计算预测值和目标值,因此这两者之间可能存在很多分歧。因此,我们可以使用两个来代替使用1one神经网络进行学习。
我们可以使用单独的网络来估计目标。该目标网络具有与函数逼近器相同的架构,但具有冻结参数。对于每个C迭代(超参数),来自预测网络的参数被复制到目标网络。这导致更稳定的训练,因为它保持目标函数固定(一段时间):
2. Experience Replay
To perform experience replay, we store the agent’s experiences – ??=(??,??,??,??+1)
上述陈述是什么意思? 系统不会在模拟或实际体验期间对状态/动作对进行Q-learning,而是将[state,action,reward,next_state]发现的数据存储在一个大表中。
让我们用一个例子来理解这一点。
假设我们正在尝试构建一个视频游戏机器人,其中游戏的每个帧代表不同的状态。 在训练期间,我们可以从最后100,000帧中随机抽取64帧来训练我们的网络。 这将使我们成为一个子集,其中样本之间的相关性较低,并且还将提供更好的采样效率。
Putting it all Together
到目前为止我们学到了什么概念? 它们共同构成了深度Q学习算法,用于在Atari游戏中实现人类级别的性能(仅使用游戏的视频帧)。
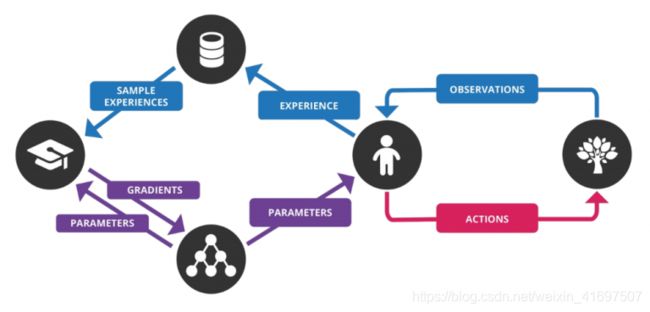
我在下面列出了深度Q网络(DQN)中涉及的步骤:
- 预处理并将游戏屏幕(状态s)提供给我们的DQN,这将返回该州所有可能操作的Q值
- 使用epsilon-greedy策略选择一个操作。 利用概率epsilon,我们选择随机动作a并且概率为1-epsilon,我们选择具有最大Q值的动作,例如a = argmax(Q(s,a,w))
- 在状态s中执行此操作并移至新状态s’以获得奖励。 该状态s’是下一个游戏屏幕的预处理图像。 我们将这个转换作为
- 接下来,从重放缓冲区中对一些随机批次的转换进行采样并计算损失
- 众所周知:
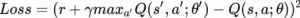
这只是目标Q和预测Q之间的平方差
- 根据我们的实际网络参数执行梯度下降,以最大限度地减少这种损失
- 在每次C迭代之后,将我们的实际网络权重复制到目标网络权重
- 对M个剧集重复这些步骤
Implementing Deep Q-Learning in Python using Keras & OpenAI Gym
好吧,所以我们对深度Q学习的理论方面有了扎实的把握。 现在看到它在行动怎么样? 那是对的 - 让我们开启我们的Python笔记本!
我们将制作一款可以玩CartPole游戏的代理商。 我们也可以使用Atari游戏,但培训代理人需要一段时间(从几个小时到一天)。 我们的方法背后的想法将保持不变,因此您可以在您的机器上的Atari游戏上尝试此操作。
CartPole是OpenAI健身房(游戏模拟器)中最简单的环境之一。 正如您在上面的动画中所看到的,CartPole的目标是平衡与移动车顶部的一个关节连接的杆。
代替像素信息,由状态给出的信息有四种(例如杆的角度和推车的位置)。 代理可以通过执行0或1的一系列操作来移动购物车,向左或向右推动购物车。
我们将在这里使用keras-rl库,这样我们就可以实现深入的Q-learning。
Step 1: Install keras-rl library
从终端,运行以下代码块:
git clone https://github.com/matthiasplappert/keras-rl.git
cd keras-rl
python setup.py install
Step 2: Install dependencies for the CartPole environment
假设您已安装pip,则需要安装以下库:
pip install h5py
pip install gym
Step 3: Let’s get started!
首先,我们必须导入必要的模块:
import numpy as np
import gym
from keras.models import Sequential
from keras.layers import Dense, Activation, Flatten
from keras.optimizers import Adam
from rl.agents.dqn import DQNAgent
from rl.policy import EpsGreedyQPolicy
from rl.memory import SequentialMemory
然后,设置相关变量:
ENV_NAME = 'CartPole-v0'
# Get the environment and extract the number of actions available in the Cartpole problem
env = gym.make(ENV_NAME)
np.random.seed(123)
env.seed(123)
nb_actions = env.action_space.n
接下来,我们将构建一个非常简单的单隐层神经网络模型:
model = Sequential()
model.add(Flatten(input_shape=(1,) + env.observation_space.shape))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(nb_actions))
model.add(Activation('linear'))
print(model.summary())
现在,配置并编译我们的代理。 我们将策略设置为Epsilon Greedy,将我们的记忆设置为顺序记忆,因为我们希望存储我们执行的操作的结果以及我们为每个操作获得的奖励。
policy = EpsGreedyQPolicy()
memory = SequentialMemory(limit=50000, window_length=1)
dqn = DQNAgent(model=model, nb_actions=nb_actions, memory=memory, nb_steps_warmup=10,
target_model_update=1e-2, policy=policy)
dqn.compile(Adam(lr=1e-3), metrics=['mae'])
# Okay, now it's time to learn something! We visualize the training here for show, but this slows down training quite a lot.
dqn.fit(env, nb_steps=5000, visualize=True, verbose=2)
测试我们的强化学习模型:
dqn.test(env, nb_episodes=5, visualize=True)
这将是我们模型的输出:

不错! 恭喜您建立了您的第一个深度Q学习模型。?
End Notes
OpenAI健身房提供了几个融合Atari游戏DQN的环境。 那些使用计算机视觉问题的人可能直观地理解这一点,因为这些是每个时间步的游戏的直接帧,该模型包括基于卷积神经网络的架构。
还有一些更先进的Deep RL技术,例如Double DQN Networks,Dueling DQN和Prioritized Experience重播,可以进一步改善学习过程。 这些技术使用更少数量的剧集为我们提供更好的分数。 我将在以后的文章中介绍这些概念。
我鼓励您在CartPole以外的至少一个环境中尝试DQN算法来练习并了解如何调整模型以获得最佳结果。