LDA 鸢尾花
参考来源https://cloud.tencent.com/developer/article/1065006,在学习过程中有所增减
导语
在模式分类和机器学习实践中,线性判别分析(Linear Discriminant Analysis, LDA)方法常被用于数据预处理中的降维(dimensionality reduction)步骤。LDA在保证良好的类别区分度的前提下,将数据集向更低维空间投影,以求在避免过拟合(“维数灾难”)的同时,减小计算消耗。
Ronald A. Fisher 在1936年(The Use of Multiple Measurements in Taxonomic Problems)提出了线性判别(Linear Discriminant)方法,它有时也用来解决分类问题。最初的线性判别适用于二分类问题,后来在1948年,被C. R. Rao(The utilization of multiple measurements in problems of biological classification)推广为“多类线性判别分析”或“多重判别分析”。
一般意义上的LDA与主成分分析(Principal Component Analysis,PCA)十分相似,但不同于PCA寻找使全部数据方差最大化的坐标轴成分,LDA关心的是能够最大化类间区分度的坐标轴成分。
一言蔽之,LDA将特征空间(数据集中的多维样本)投影到一个维度更小的 k 维子空间中( k≤n−1),同时保持区分类别的信息。 通常情况下,降维不仅降低了分类任务的计算量,还能减小参数估计的误差,从而避免过拟合。
主成分分析 vs. 线性判别分析
线性判别分析(LDA)与主成分分析(PCA)都是常用的线性变换降维方法。PCA是一种“无监督”算法,它不关心类别标签,而是致力于寻找数据集中最大化方差的那些方向(亦即“主成分”);LDA则是“有监督”的,它计算的是另一类特定的方向(或称线性判别“器”)——这些方向刻画了最大化类间区分度的坐标轴。
虽然直觉上听起来,在已知类别信息时,LDA对于多分类任务要优于PCA,但实际并不一定。
比如,比较经过PCA或LDA处理后图像识别任务的分类准确率,如果样本数比较少,PCA是要优于LDA的(PCA vs. LDA, A.M. Martinez et al., 2001)。联合使用LDA和PCA也并不罕见,例如降维时先用PCA再做LDA。

LDA的五个步骤
Linear Discriminant Analysis(线性判别分析),而不是Latent Dirichlet Allocation(隐狄利克雷分布)
1. 计算数据集中不同类别数据的 d 维均值向量。
2. 计算散布矩阵,包括类间、类内散布矩阵。
3. 计算散布矩阵的特征向量 e1,e2,…,ed 和对应的特征值 λ1,λ2,…,λd。
4. 将特征向量按特征值大小降序排列,然后选择前 k 个最大特征值对应的特征向量,组建一个 d×k 维矩阵——即每一列就是一个特征向量。
5. 用这个 d×k-维特征向量矩阵将样本变换到新的子空间。这一步可以写作矩阵乘法 Y=X×W 。 X 是 n×d 维矩阵,表示 n 个样本; y 是变换到子空间后的 n×k 维样本。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
# 列名
cols = [
'sepal length in cm',
'sepal width in cm',
'petal length in cm',
'petal width in cm',
'class label'
]
df = pd.read_csv(r"...\data\iris.data", names=cols)
X = df[['sepal length in cm', 'sepal width in cm', 'petal length in cm', 'petal width in cm']].values
# 标签映射
# from sklearn.preprocessing import LabelEncoder
# enc = LabelEncoder()
# y = enc.fit_transform(y) + 1
mapping = {"Iris-setosa": 1, "Iris-versicolor": 2, "Iris-virginica": 3}
y = df['class label'].map(mapping).values
第1步 计算均值向量
np.set_printoptions(precision=4) # 输出精度
# 每类样本均值
mean_vectors = []
for cl, i in enumerate(np.unique(y)):
mean_vectors.append(X[y == i].mean(axis=0))
print('Mean Vector class %s: %s\n' %(cl+1, mean_vectors[cl]))
Mean Vector class 1: [5.006 3.418 1.464 0.244]
Mean Vector class 2: [5.936 2.77 4.26 1.326]
Mean Vector class 3: [6.588 2.974 5.552 2.026]
第2步 计算散布矩阵
类内散布矩阵
S W = ∑ i = 1 c S i S_W = \sum\limits_{i=1}^c S_i SW=i=1∑cSi
S i = ∑ x ∈ D i n ( x − m i ) ( x − m i ) T S_i = \sum\limits_{x\in D_i}^n (x-m_i)(x-m_i)^T Si=x∈Di∑n(x−mi)(x−mi)T
m i = 1 n i ∑ x ∈ D i n x k m_i = \frac{1}{n_i} \sum\limits_{x\in D_i}^n x_k mi=ni1x∈Di∑nxk
S_W = np.zeros((4, 4))
for cl, m in enumerate(mean_vectors, 1):
class_sc_mat = np.zeros((4, 4)) # 每一类的散布矩阵
for row in X[y == cl]:
m_ = (row - m).reshape(-1, 1)
class_sc_mat += m_.dot(m_.T)
S_W += class_sc_mat
print("within-class Scatter Matrix:\n", S_W)
within-class Scatter Matrix:
[[38.9562 13.683 24.614 5.6556]
[13.683 17.035 8.12 4.9132]
[24.614 8.12 27.22 6.2536]
[ 5.6556 4.9132 6.2536 6.1756]]
类间散布矩阵
S B = ∑ i = 1 c N i ( m i − m ) ( m i − m ) T S_B = \sum\limits_{i=1}^c N_i (m_i-m)(m_i-m)^T SB=i=1∑cNi(mi−m)(mi−m)T
- m: 全局平均
- mi: 每类样本均值
- Ni: 每类样本数
# 全局均值
all_mean = np.mean(X, axis=0)
S_B = np.zeros((4, 4)) # 初始化零矩阵
for i, m in enumerate(mean_vectors, 1):
n = X[y==i].shape[0]
m_ = (m - all_mean).reshape(-1, 1)
S_B += n * m_.dot(m_.T)
print("between-class Scatter Matrix:\n", S_B)
between-class Scatter Matrix:
[[ 63.2121 -19.534 165.1647 71.3631]
[-19.534 10.9776 -56.0552 -22.4924]
[165.1647 -56.0552 436.6437 186.9081]
[ 71.3631 -22.4924 186.9081 80.6041]]
第3步 特征值、特征向量
特征值 = S W − 1 S B S_W^{-1}S_B SW−1SB
-
特征值:特征向量的重要程度
-
特征向量:映射方向
# 特征值, 特征向量 = np.linalg.eig()
eig_vals, eig_vecs = np.linalg.eig(np.linalg.inv(S_W).dot(S_B))
for i in range(len(eig_vals)):
eigvec_sc = eig_vecs[:, [i]]
print('\nEigenvector {}:\n{}'.format(i+1, eigvec_sc.real))
print('Eigenvalue {}: {:.2e}'.format(i+1, eig_vals[i].real))
Eigenvector 1:
[[-0.2049]
[-0.3871]
[ 0.5465]
[ 0.7138]]
Eigenvalue 1: 3.23e+01
Eigenvector 2:
[[-0.009 ]
[-0.589 ]
[ 0.2543]
[-0.767 ]]
Eigenvalue 2: 2.78e-01
Eigenvector 3:
[[-0.8844]
[ 0.2854]
[ 0.258 ]
[ 0.2643]]
Eigenvalue 3: 3.42e-15
Eigenvector 4:
[[-0.2234]
[-0.2523]
[-0.326 ]
[ 0.8833]]
Eigenvalue 4: 1.15e-14
检查运算是否满足等式
A v = λ v Av = \lambda v Av=λv
A = S W − 1 S B A = S_W^{-1}S_B A=SW−1SB
v : E i g e n v e c t o r v: Eigenvector v:Eigenvector
λ : E i g e n v a l u e \lambda: Eigenvalue λ:Eigenvalue
for i in range(len(eig_vals)):
eigv = eig_vecs[:, [i]]
np.testing.assert_array_almost_equal(
np.linalg.inv(S_W).dot(S_B).dot(eigv),
eig_vals[i] * eigv
) # 正确返回None
第4步 选择线性判别“器”构成新的特征子空间
1. 按特征值排序特征向量
# [(特征值1, 特征向量1), (特征值2, 特征向量2), ...]
eig_pairs = [(np.abs(eig_vals[i]), eig_vecs[:, i]) for i in range(len(eig_vals))]
# 按特征值排序
eig_pairs = sorted(eig_pairs, key=lambda k: k[0], reverse=True)
# 打印验证
print('Eigenvalues in decreasing order:\n')
for i in eig_pairs:
print(i[0])
Eigenvalues in decreasing order:
32.27195779972981
0.27756686384003953
1.1483362279322388e-14
3.422458920849769e-15
print('Variance explained:\n')
eigv_sum = sum(eig_vals)
for i, j in enumerate(eig_pairs):
print('eigenvalue {0:}: {1:.2%}'.format(i+1, (j[0]/eigv_sum).real))
Variance explained:
eigenvalue 1: 99.15%
eigenvalue 2: 0.85%
eigenvalue 3: 0.00%
eigenvalue 4: 0.00%
2. 选择 k 个最大特征值对应的特征向量
组建 k×d-维特征向量矩阵 W
这样就从最初的4维特征空间降到了2维的特征空间
W = np.hstack((eig_pairs[0][1].reshape(4,1), eig_pairs[1][1].reshape(4,1)))
print('Matrix W:\n', W.real)a
Matrix W:
[[-0.2049 -0.009 ]
[-0.3871 -0.589 ]
[ 0.5465 0.2543]
[ 0.7138 -0.767 ]]
第5步 将样本变换到新的子空间中
使用上一步刚刚计算出的 4×2-维矩阵 W, 将样本变换到新的特征空间上:
Y = X × W Y = X \times W Y=X×W
X X X: n × \times × d维矩阵,n个样本
Y Y Y: 变换后新子空间的 n × \times × k维矩阵
X_lda = X.dot(W)
assert X_lda.shape == (150,2), "The matrix is not 150x2 dimensional."
from matplotlib import pyplot as plt
label_dict = {1: "Iris-setosa", 2: "Iris-versicolor", 3: "Iris-virginica"}
def plot_step_lda():
ax = plt.subplot(111) # 创建subplot,隐藏边线
for label, marker, color in zip(range(1, 4), ('^', 's', 'o'), ('b', 'r', 'g')):
plt.scatter(x=X_lda[y==label, 0],
y=X_lda[y==label, 1],
marker=marker,
color=color,
alpha=0.5,
label=label_dict[label]
)
plt.xlabel('LD1')
plt.ylabel('LD2')
leg = plt.legend(loc='upper right', fancybox=True)
leg.get_frame().set_alpha(0.5)
plt.title('LDA: Iris projection onto the first 2 linear discriminants')
# 隐藏刻度线
plt.tick_params(bottom=False, top=False, left=False, right=False)
# 隐藏边线
ax.spines["top"].set_visible(False)
ax.spines["right"].set_visible(False)
ax.spines["bottom"].set_visible(False)
ax.spines["left"].set_visible(False)
plt.grid()
plt.show()
plot_step_lda()

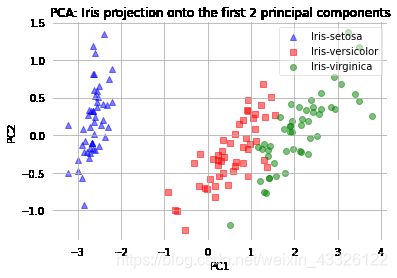
PCA 和 LDA 的对比
from sklearn.decomposition import PCA as sklearnPCA
sklearn_pca = sklearnPCA(n_components=2)
X_pca = sklearn_pca.fit_transform(X)
def plot_pca():
ax = plt.subplot(111)
for label,marker,color in zip(
range(1,4),('^', 's', 'o'),('blue', 'red', 'green')):
plt.scatter(x=X_pca[y==label, 0],
y=X_pca[y==label, 1],
marker=marker,
color=color,
alpha=0.5,
label=label_dict[label]
)
plt.xlabel('PC1')
plt.ylabel('PC2')
leg = plt.legend(loc='upper right', fancybox=True)
leg.get_frame().set_alpha(0.5)
plt.title('PCA: Iris projection onto the first 2 principal components')
# 隐藏刻度线
plt.tick_params(bottom=False, top=False, left=False, right=False)
# 隐藏边线
ax.spines["top"].set_visible(False)
ax.spines["right"].set_visible(False)
ax.spines["bottom"].set_visible(False)
ax.spines["left"].set_visible(False)
plt.grid()
plt.show()
plot_pca()
plot_step_lda()

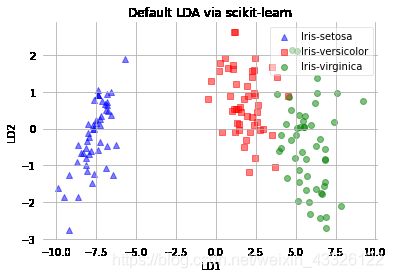
使用 scikit-learn 中的 LDA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
sklearn_lda = LDA(n_components=2)
X_lda_sklearn = sklearn_lda.fit_transform(X, y) * -1 # 180度翻转图形
def plot_scikit_lda(X):
ax = plt.subplot(111) # 创建subplot,隐藏边线
for label, marker, color in zip(range(1, 4), ('^', 's', 'o'), ('b', 'r', 'g')):
plt.scatter(x=X[y==label, 0],
y=X[y==label, 1],
marker=marker,
color=color,
alpha=0.5,
label=label_dict[label]
)
plt.xlabel('LD1')
plt.ylabel('LD2')
leg = plt.legend(loc='upper right', fancybox=True)
leg.get_frame().set_alpha(0.5)
plt.title('Default LDA via scikit-learn')
# 隐藏刻度线
plt.tick_params(bottom=False, top=False, left=False, right=False)
# 隐藏边线
ax.spines["top"].set_visible(False)
ax.spines["right"].set_visible(False)
ax.spines["bottom"].set_visible(False)
ax.spines["left"].set_visible(False)
plt.grid()
plt.show()
plot_step_lda()
plot_scikit_lda(X_lda_sklearn)

规范化
规范化就是把数据用均值做中心化、用标准差做单位化: x s t d = x − μ x σ X x_{std} = \frac{x-\mu_x}{\sigma X} xstd=σXx−μx
不管做不做尺度变化,特征值是一样的。除了成分轴的尺度不太一样,以及图形做了中心对称翻转,最后的投影结果基本没有区别。
y, X = df.iloc[:, 4].values, df.iloc[:, 0:4].values
X_cent = X - X.mean(axis=0)
X_std = X_cent / X.std(axis=0)
sklearn使用代码
LDA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
sklearn_lda = LDA(n_components=2)
X_lda = sklearn_lda.fit_transform(X, y) * -1
PCA
from sklearn.decomposition import PCA
sklearn_pca = PCA(n_components=2)
X_pca = sklearn_pca.fit_transform(X)