利用神经网络来解决鸢尾花分类任务(附实验结果和代码)
前言
本篇文章使用自己亲手搭建的神经网络模型来解决鸢尾花数据集的分类任务,读者们可以通过该简单的任务进一步理解神经网络,并且可以自己动手去搭建神经网络。
鸢尾花数据集的介绍
https://archive.ics.uci.edu/ml/index.php
大家可以通过这个网站下载鸢尾花数据集,里面有各种经典数据集供大家使用。附:本来想给大家具体讲一讲的,但发现网站里面讲的已经很详细了,大家想用的自己去了解就好了,看不懂英文可以转成中文哦(ゝ∀・)。
神经网络结构的介绍+实验结果
这个部分来简单介绍一下我的神经网络,我构造的比较简单,设置了两个隐层,每层都使用了ReLU激活函数,然后损失函数使用的是交叉熵损失函数,优化方法使用的是Adam,这就是我搭建的神经网络的基本信息,给各位先看一下实验结果:
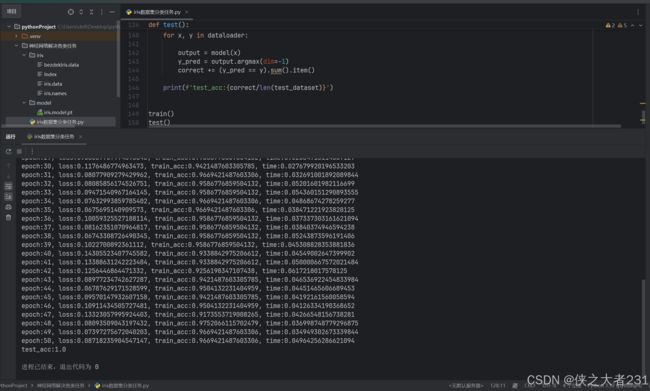
补充:在神经网络整体结构不变的情况下,我尝试过很多优化,该配置所实现的结果可以说已经是相当不错了,当然大家也可以继续对我的神经网络结构进行进一步的优化,可以优化的空间还有很多(*´∀`)~♥。
代码部分:
import pandas as pd
import torch
import torch.nn as nn
from sklearn.preprocessing import LabelEncoder
import numpy as np
from sklearn.model_selection import train_test_split
from torch.utils.data import TensorDataset
from torch import optim
from torch.utils.data import DataLoader
import time
def create_dataset():
# 加载鸢尾花数据集
data = pd.read_csv('iris/iris.data', names=['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'class'])
# 获取x, y值
x, y = data.iloc[:, 0:4], data.iloc[:, 4]
x = x.astype(np.float32) # 转换成float32是一般张量在gpu中的运算都是使用float32格式实现硬件加速
# print(x.values) # pandas数据结构的.values是Numpy数据结构
# 初始化编码器(将类别映射为数字)
encoder = LabelEncoder()
y = encoder.fit_transform(y) # 转化为数据结构为numpy的数组,值分别为0,1,2
y = y.astype(np.int64)
# print(y)
# 数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.8, random_state=0, stratify=y)
# print(type(x_train), type(x_test), type(y_train), type(y_test))
# 构建Pytorch数据集对象
train_dataset = TensorDataset(torch.from_numpy(x_train.values), torch.from_numpy(y_train))
test_dataset = TensorDataset(torch.from_numpy(x_test.values), torch.from_numpy(y_test))
# 返回训练数据集,测试数据集,特征维度,标签数量
return train_dataset, test_dataset, x.shape[1], len(np.unique(y))
class IrisModel(nn.Module):
def __init__(self, input_size, output_size):
super(IrisModel, self).__init__()
self.fc1 = nn.Linear(input_size, 128)
self.fc2 = nn.Linear(128, 256)
self.fc3 = nn.Linear(256, output_size)
self.relu1 = nn.ReLU()
self.relu2 = nn.ReLU()
def forward(self, x):
# 输入层到第一个隐层
x = self.fc1(x)
x = self.relu1(x)
# 第一个隐层到第二个隐层
x = self.fc2(x)
x = self.relu2(x)
# 第二个隐层到输出层
output = self.fc3(x)
return output
train_dataset, test_dataset, input_size, output_size = create_dataset()
def train():
# 固定随机数种子
torch.manual_seed(0)
# 初始化模型
model = IrisModel(input_size, output_size)
# 损失函数
criterion = nn.CrossEntropyLoss()
# 优化方法
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 训练轮数
num_epochs = 50
for epoch_idx in range(num_epochs):
# 初始化数据加载器
dataloader = DataLoader(train_dataset, batch_size=6, shuffle=True)
# 训练时间
start = time.time()
# 计算损失
total_loss = 0
total_num = 1
# 准确率
correct = 0
for x, y in dataloader:
output = model(x)
# print(output)
y_pred = output.argmax(dim=-1) # 一维数组
# print(y_pred)
# print(y)
# print(y_pred == y)
# 计算损失
loss = criterion(output, y) # 得到的是batch_size个样本的平均损失
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
# 累计总损失
total_loss += loss.item() * len(y)
# 累计总样本数量
total_num += len(y)
# 累计预测正确的样本数量
correct += (y_pred == y).sum().item()
print(f'epoch:{epoch_idx+1}, loss:{total_loss/total_num}, train_acc:{correct/total_num}, time:{time.time() - start}')
# 模型保存
torch.save(model.state_dict(), 'model/iris.model.pt') # 这里只保存模型的参数
def test():
# 加载模型
model = IrisModel(input_size, output_size)
model.load_state_dict(torch.load('model/iris.model.pt', weights_only=True))
# 启用模型的评估模式
model.eval()
# 构建加载器
dataloader = DataLoader(test_dataset, batch_size=6, shuffle=True)
# 评估测试集
correct = 0
for x, y in dataloader:
output = model(x)
y_pred = output.argmax(dim=-1)
correct += (y_pred == y).sum().item()
print(f'test_acc:{correct/len(test_dataset)}')
train()
test()结语:如果觉得本次的内容对你有帮助,别忘了一键三连哦(*´∀`)~♥(*´∀`)~♥。有问题欢迎在评论区留言或者加我qq3125295956与我细聊,我看到了会积极回复和解决你们的问题的!(*´∀`)~♥