贪心科技机器学习训练营(二)
来源:贪心学院,https://www.zhihu.com/people/tan-xin-xue-yuan/activities
写文章交作业
这次训练营的讲的是knn
我先找下文章回忆下
KNN算法
KNN实现“手写识别”
GridSearchCV和交叉熵
机器学习的回归算法
sklearn模型的训练(上)
近邻算法分类
[机器学习认识聚类(KMeans算法)]
这些都是我写的吗???怎么没啥印象了?????


确定k值
from sklearn.cluster import KMeans
wcss = []
for k in range(1,15):
kmeans = KMeans(n_clusters=k)
kmeans.fit(x)
wcss.append(kmeans.inertia_)
plt.plot(range(1,15),wcss)
plt.xlabel("k values")
plt.ylabel("WCSS")
plt.show()
---------------------
作者:毛利学python
来源:CSDN
原文:https://blog.csdn.net/weixin_44510615/article/details/92021326
版权声明:本文为博主原创文章,转载请附上博文链接!
数据采用的是经典的iris数据,是三分类问题
# 读取相应的库
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
# 读取数据 X, y
iris = datasets.load_iris()
X = iris.data
y = iris.target
print (X, y)
# 把数据分成训练数据和测试数据
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=2003)
# 构建KNN模型, K值为3、 并做训练
clf = KNeighborsClassifier(n_neighbors=3)
clf.fit(X_train, y_train)
# 计算准确率
from sklearn.metrics import accuracy_score
correct = np.count_nonzero((clf.predict(X_test)==y_test)==True)# 35
#accuracy_score(y_test, clf.predict(X_test))
print ("Accuracy is: %.3f" %(correct/len(X_test))) # 35/38
np.count_nonzero是来数组的0的总数

自己手下一个knn
- 计算两个样本的欧式距离
- 得到最大k个的距离再投票计数
from sklearn import datasets
from collections import Counter # 为了做投票
from sklearn.model_selection import train_test_split
import numpy as np
# 导入iris数据
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=2003)
def euc_dis(instance1, instance2):
"""
计算两个样本instance1和instance2之间的欧式距离
instance1: 第一个样本, array型
instance2: 第二个样本, array型
"""
# TODO
dist = np.sqrt(sum((instance1 - instance2)**2))
return dist
def knn_classify(X, y, testInstance, k):
"""
给定一个测试数据testInstance, 通过KNN算法来预测它的标签。
X: 训练数据的特征
y: 训练数据的标签
testInstance: 测试数据,这里假定一个测试数据 array型
k: 选择多少个neighbors?
"""
# TODO 返回testInstance的预测标签 = {0,1,2}
distances = [euc_dis(x, testInstance) for x in X])
# 排序
kneighbors = np.argsort(distances)[:k]
# count是一个字典
count = Counter(y[kneighbors])
# count.most_common()[0][0])是票数最多的
return count.most_common()[0][0]
>>> x = np.array([3, 1, 2])
>>> np.argsort(x)
array([1, 2, 0])
Counter不会的看
python标准库 collections


# 预测结果。
predictions = [knn_classify(X_train, y_train, data, 3) for data in X_test]
correct = np.count_nonzero((predictions==y_test)==True)
#accuracy_score(y_test, clf.predict(X_test))
print ("Accuracy is: %.3f" %(correct/len(X_test)))
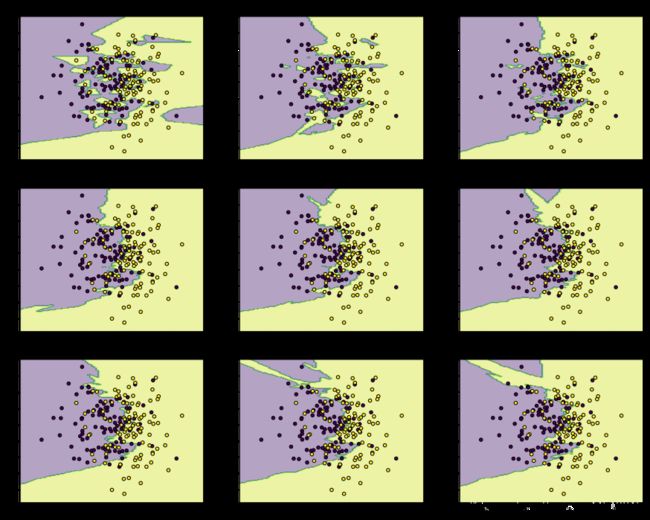
KNN的决策边界


import matplotlib.pyplot as plt
import numpy as np
from itertools import product
# knn分类
from sklearn.neighbors import KNeighborsClassifier
# 生成一些随机样本
n_points = 100
# 多元高斯分布
X1 = np.random.multivariate_normal([1,50], [[1,0],[0,10]], n_points)
X2 = np.random.multivariate_normal([2,50], [[1,0],[0,10]], n_points)
X = np.concatenate([X1,X2])
y = np.array([0]*n_points + [1]*n_points)
print (X.shape, y.shape) # (200, 2) (200,)

# KNN模型的训练过程
clfs = []
neighbors = [1,3,5,9,11,13,15,17,19]
for i in range(len(neighbors)):
clfs.append(KNeighborsClassifier(n_neighbors=neighbors[i]).fit(X,y))
# 可视化结果
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
f, axarr = plt.subplots(3,3, sharex='col', sharey='row', figsize=(15, 12))
for idx, clf, tt in zip(product([0, 1, 2], [0, 1, 2]),
clfs,
['KNN (k=%d)'%k for k in neighbors]):
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
axarr[idx[0], idx[1]].contourf(xx, yy, Z, alpha=0.4)
axarr[idx[0], idx[1]].scatter(X[:, 0], X[:, 1], c=y,
s=20, edgecolor='k')
axarr[idx[0], idx[1]].set_title(tt)
plt.show()