Hive笔记之------------基础&&实例操作(sogou 500w数据,创建一张表sogou_20111230....)
一Hive简介
Hive实质为SQL的引擎,是对SQL语句的封装,本身不存储任何数据
进入Hive环境shell命令
cd apache-hive-0.13.1-bin/bin/hive
如下
hive>
>
>
结束hive 分号 即是 >;
二 hive下数据库的操作
创建数据库
create database 数据库名;
查看
show databases;
创建表格:
use 数据库名;
create tables 表格名;
查看表格:
show tables;
删除表
drop table if exists 表格名;
删除空数据库
drop database 数据库名;
删除非空数据库
drop database 数据库名 cascade;
数据库详情:
describe database 数据库;
查看数据库默认路径:
hadoop fs -ls /user/hive/warehouse
三 实例操作
e1:
sogou 500w数据,创建一张表sogou_20111230,这张表在sogou这个数据库中,注意,6个字段的数据类型.
e2:
把sogou 500w的数据放到表中,并执行下面的查询,
查询前100行数据
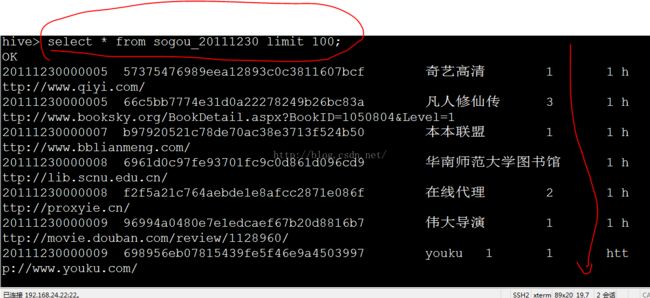
select * from sogou_20111230 limit 100;
思路:
第一步:在Hive环境
在hive中创建数据库 如
1.默认数据库存放路径 /user/hive/warehouse
查看 进入hadoop环境下
hadoop fs -ls /user/hive/warehouse
2.自定义路径
create database test location '/my/path';意为在hadoop根目录下my目录中
查看 进入hadoop环境
hadoop fs -ls /my/path
需要注意的是:自定义路径不显示改路径下的数据库名 ,
但是当在该数据库中创建表时,会自动将表自动放入自定义的路径下 如图:![]()
进入该数据库:
use test;
方式一(默认数据路径)
在数据库中创建表
create table sogou_20111230
(date string, uid string, keyword string, rank int, count int, url string)
row format delimited
fields terminated by '\t' ;
数据库 表 字段 创建完毕后下一步开始将数据输入到字段中 这里采用搜狗500w数据
hadoop端
将该文件放入数据库表中
a 进入数据库默认存放路径
hadoop fs -ls /user/hive/warehouse
b 找到对应数据库
/user/hive/warehouse/test.db
c 将数据输入表中
cd /home/zkpk/resources/sogou-data/500w/
hadoop fs -put sogou.500w.utf8 /user/hive/warehouse/test.db/sogou_20111230
方式二(自定义数据路径)
在hadoop集群下创建sogou500w文件
hadoop fs -mkdir /sogou500w
将数据放入该目录下
hadoop fs -put /home/zkpk/resources/sogou-data/500w/sogou.500w.utf8 /sogou500w
创建表并自定义数据路径
create table sogou_20111230
(date string, uid string, keyword string, rank int, count int, url string)
row format delimited
fields terminated by '\t'
location '/sougou500w';(此文件位于hadoop集群下)
(数据库语句具体解释:
create table sogou_20111230 为要创建的表名
(date string, uid string, keyword string, rank int, count int, url string) 表中的字段
row format delimited 表中数据行的格式
fields terminated by '\t' 表中数据分隔符
LOCATION '/test'数据存放的位置 )
此步是方式一 二共用
回到 Hive端:
查找前100行数据
select * from sogou_20111230 limit 100;(前提是必须在该表下操作)
否则:
use test;
select * from sogou_20111230 limit 100;
显示结果如图: