关于python爬虫lxml方式下对text函数提取空值的研究
在对网页爬虫时候,我们常常会遇到空值,有时候我们需要提取到文本中,但是今天我爬虫时候遇到小麻烦,解决了奖金一个小时!
本文主要讲的是lxml模式下的对空值处理。
我所爬虫的网页中有很多class=“el”并且每个el下呢,还有相同的class="t4"的标签。
第一段代码:(我截取部分代码,只阐述问题与解决方法)
prices = selector.xpath('//div[@id="resultList"]/div[starts-with(@class,"el")]/span[@class="t4"]')
for i in range(50):
pr=prices[i]
print(pr.text)
此时结果:
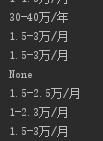
第二段代码:
prices = selector.xpath('//div[@id="resultList"]/div[starts-with(@class,"el")]/span[@class="t4"]/text()')
print(prices)
结果:
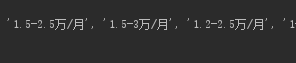
有没有发现,此时的空值(None)不见了!
我从网上找了半天,也没发现相关的文档,很纳闷!
我猜想,是不是text()自己忽略空值,只提取非空值到prices列表中去了呢?!
各位朋友如果有好的解释,请评论我,谢谢,大家一起进步!