CVPR 2016|商汤科技论文解析:行为识别与定位
论文:A Key Volume Mining Deep Framework for Action Recognition
论文作者:Wangjiang Zhu, Jie Hu, Gang Sun, Xudong Cao, Yu Qiao
Tsinghua University(清华大学),Shenzhen Institutes of Advanced Technology, CAS, China(中国科学院深圳先进技术研究院)、SenseTime Group Limited(商汤科技)
本文作者:朱望江
CVPR:IEEE Conference on Computer Vision and Pattern Recognition,即 IEEE 国际计算机视觉与模式识别会议。该会议是计算机视觉和模式识别领域的顶级会议,在中国计算机学会推荐国际学术会议的排名中,CVPR 为人工智能领域的 A 类会议。
商汤科技会在 CVPR 2016 上提交多篇论文,商汤科技的技术专家将在机器之心发布系列文章,对论文进行解读。本文为此系列文章的第二篇,点击「CVPR 2016|商汤科技论文解析:人脸检测中级联卷积神经网络的联合训练」查看第一篇论文解析。
在智能手机普及度极高、网络带宽不断提升的条件下,人们拍摄视频的需求越来越多。如何像处理文字那样高效地理解、归类、检索视频变得越来越重要。而视频理解的一个重要课题就是识别视频中人的动作或者行为(Action Recognition)。
Action Recognition 是计算机视觉中比较难的一个问题。因为:
-
不同人完成同一种动作的方式有很大差异。比如同样是挥手,有些人举得很高幅度很大,有些人动作很矜持;
-
同一种动作往往会有很多亚类。收集数据时候,很难为每一个亚类都收集足够的训练样本。比如拳击就可以包括上勾拳,平勾拳,斜勾拳等众多亚类。
-
数据很难收集。这是因为视频的精细标注(标注每个动作发生的时空位置)工作量远大于图像标注,目前学术界研究 Action Recognition 的数据集要么太小,要么标注太粗糙,甚至完全是基于文本关键词自动归类的,而没有人工的检验。
灵感来源
目前 Action Recognition 比较好的做法是 two-stream 的思路。即对 RGB image 和 optical flow (光流)分别训练分类模型,在测试阶段两个 stream 的预测结果取平均。
我们发现即便是 trimmed video (例如 UCF101 数据集),实际的动作发生的时空位置也是非常不确定的:我们既不知道做动作的人在什么空间位置,也不知道真正的动作发生的精确时间位置。更糟糕的是,和动作类别直接相关的,具有区分性的 (discriminative)key volume 往往占比非常小,这在 flow stream 上表现得尤为突出。
于是我们就想能否先把这些 key volume 找出来,直接用以训练分类器,这样可以免受噪声数据的干扰,更加聚焦在动作本质上。但实际上,在得到一个好的分类器之前我们是很难自动地将 key volume 挑出来的。于是我们陷入了一个鸡生蛋,蛋生鸡的困境。
借鉴 Multiple Instance Learning 的思想,我们把鸡和蛋的问题放在一起来优化解决:在训练分类器的同时,挑选 key volume;并用挑出来的 key volume 更新分类器的参数。这两个过程无缝地融合到了 CNN (卷积神经网络)的网络训练的 forward 和 backward 过程中,使得整个训练过程非常优雅、高效。
实验发现,key volume 基本上就对应于动作时间发生的时空区间。这意味着我们不仅能对动作进行分类,还能粗略地在视频中找到动作发生的实际时空位置。
算法概要
不同于以往的神经网络训练,我们从一段视频中截取了多个 3D volumes 作为神经网络的输入。经过 CNN 之后,每个 volume 会得到一个预测向量,表示该 volume 属于每一个动作类别的概率。
借鉴 Multiple Instance Learning 的思想,网络的 loss function 要求第 i 类视频中的所有volume在非 i 类的分类器上的响应较小;同时鼓励第i类视频中至少有一个 volume 在第 i 类的分类器上响应较高。
当网络训练到一定的程度之后,神经网络训练的 Forward 阶段对每个 volume 的打分可以用来挑选 key volume;这些 key volume 会在 Backward 阶段影响到神经网络参数的调整。使用 key volume 来更新网络参数避免了随机 volume 引入的噪声,从而得到更好地网络参数。
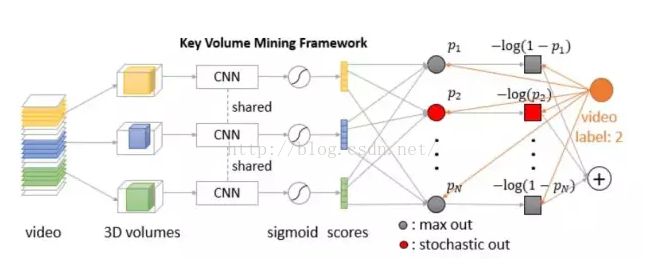
除了网络设计上的贡献,1)该文章还提出了 Stochastic out 用来鼓励选取多模态的 key volume,而不是很快收敛到一个 dominant 模态。2)该文章使用 key volume proposal(类似于图像中的object proposal)来缩小 key volume 的搜索范围。
基于该方法,我们将 UCF101 数据集的分类正确率做到了 93.1%,据我们所知,这是目前学术界最高性能。
下图给出了 key volume 分布的热度图,可以发现,key volume 基本上对应于实际动作发生的时空位置。

工业界的应用
Action Recognition 在监控中可以用来实时监控甚至预测一些诸如打架头殴、恐怖袭击等危险行为。还可以对海量的监控视频进行分类检索,可以省去很大一部分人力,快速定位到事件发生的时间点。
Action Recognition 对人机交互也很有意义。目前 Kinect 摄像头需要用比较昂贵的深度摄像头来分析人的体态和行为,基于 RGB 视频的 Action Recognition 可以使用廉价的硬件来构建解决方案。
个人简介:
朱望江,现任商汤科技见习研发工程师。清华-MSRA(微软亚洲研究院)联合培养五年级博士生。读博期间发表 CVPR论文两篇,ECCV论文一篇。研究领域:Action Recognition, Salient Object Detection。
论文:笔记本D盘最新行为识别论文集合A Key Volume Mining Deep Framework for Action Recognition
投诉