Sktime:用于时间序列机器学习的Python库
全文共4701字,预计学习时长12分钟

图源:unsplash
在Python中使用时间序列来解决数据科学问题是非常有挑战性的,现有的工具并不适合时间序列任务,也不容易集成。
Scikiti -learn包中的方法假设数据是表格格式结构,每一列为独立同分布——这些假设不适用于时间序列数据。包含时间序列学习模块的程序包,例如状态模型,不能很好地集成。此外,现有的Python包不支持许多基本的时间序列操作,比如将数据分成不同时间的训练集和测试集。
Sktime就是为了解决这一问题应运而生的。Sktime是一个使用时间序列进行机器学习的开源Python工具箱。这是一个由英国经济与社会研究理事会、消费者数据研究中心和艾伦·图灵研究所资助的社区驱动的基金项目。
Sktime将Scikit-learn应用程序接口扩展到时间序列任务。它提供了必要的算法和转换工具,能有效地解决时间序列回归、预测和分类任务。该库包括其他通用类库没有的、专用的时间序列学习算法和转换方法。
Sktime的设计可以与Scikiti -learn互操作,轻松适应相关时间序列任务的算法,并构建复合模型。具体怎么操作呢?许多时间序列任务是相关联的,能够解决一项任务的算法通常可以用来解决相关的任务,这个概念叫做还原。
例如,时间序列回归模型(使用序列来预测输出值)可用于时间序列预测任务(预测的输出值是终值)。

sktime库标志 | 图源:Github
其宗旨是:“Sktime使可理解和可组合的机器学习具有时间序列,为支持清晰学习任务分类Scikiti -learn兼容算法和模型组合工具提供了具有启发性的文档和友好的社群。”
本文将重点介绍sktime的一些特性。

适合时间序列的数据模型
Sktime针对pandas数据帧中的时间序列使用了嵌套数据结构。
典型数据框架中的每一行都包含独立同分布观测值,列代表不同的变量。对于Sktime方法,Pandas数据帧中的每个单元格包含整个时间序列。这种格式对于多变量、面板和异构数据很灵活,允许重用Pandas和Scikit-learn中的方法。在下表中,每一行都是一个观察值,X列中包含一个时间序列数组,y列包含一个组值。

本机时间序列数据结构,与sktime兼容
在下表中,按照Scikit-learn的方法要求,X列中的每个元素被分为单个列,251列的维数非常高。此外,表格学习算法忽略了列的时间顺序(但用于时间序列分类和回归算法)。
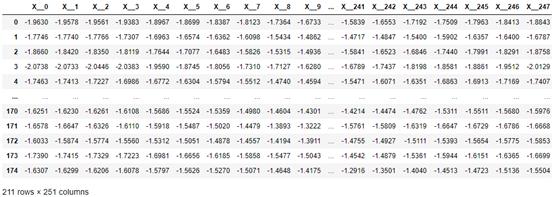
scikit-learn所需时间序列数据结构
对于建模多个同时出现的系列的问题,本机系列数据结构兼容的Sktime显然是最好的,Scikiti -learn表格格式数据结构训练的模型会淹没在众多特性中。
sktime能做什么?
根据Github页面介绍,sktime目前提供:
· 模型调优。
· 转换器和模型流水线技术。
· 最先进的时间序列分类、回归和预测算法(来自基于java的tsml工具包)。
· 用于时间序列的转换器:单序列变换(例如去趋势或去周期),序列作为特征变换(例如特征提取器),以及组成不同转换器的工具。
· 模型集合——例如用于时间序列分类和回归的可完全定制的随机森林;多变量问题的集合。
sktime应用程序接口
如上所述,Sktime遵循基本的Scikit-learn应用程序接口以及拟合、预报和变换类方法。对于估计量(即模型)类,Sktime提供了一个拟合方法用于模型训练,以及一个预报方法用于生成新的预测;Sktime中的估计量将Scikit-learn的回归器和分类器扩展到对应的时间序列;Sktime还包括特定于时间序列任务的新的估计器。

图源:unsplash
对于转换器类,sktime提供了拟合和转换方法来转换系列数据。有几种可用的类型转换:
· 表格式数据转换器,例如PCA,可以在独立同分布实例上操作。
· 序列到基元转换器,将每一行的时间序列转换为基元数字(例如,特征事务)。
· 序列到序列转换器将序列转换为不同的序列(如序列的傅里叶变换)。
· 去趋势转换器返回与输入序列在同一域中的去趋势时间序列(例如去周期)。

代码示例
时间序列预测
下面的例子改编自Github上的预测教程,本例中的系列(博克思-詹金斯法航空数据集)显示了1949-1960年期间每月国际航空公司乘客的数量。
首先,加载数据并将其分为训练集、测试集和图表。sktime提供了两个方便的函数来轻松完成此任务——temporal_train_test_splitfor按时间分割数据集,plot_ys用于绘制训练和测试序列值。
from sktime.datasets import load_airline
fromsktime.forecasting.model_selection import temporal_train_test_split
fromsktime.utils.plotting.forecasting import plot_ys
y =load_airline()
y_train,y_test =temporal_train_test_split(y)
plot_ys(y_train,y_test, labels=["y_train", "y_test"])
在创建复杂的预测之前,将预测与一个简单的基线进行比较会很有帮助——一个好的模型必须超过这个值。sktime提供NaiveForecaster方法,采用不同的“策略”生成基线预测。
下面的代码和图表展示了两个天真预测。strategy = " last "预测器会预测序列的最后观察值。strategy = " seasonal_last "预测器预测给定季节中观察到的序列最后一个值。本例中的周期指定为“sp=12”,即12个月。
from sktime.forecasting.naive importNaiveForecaster
naive_forecaster_last =NaiveForecaster(strategy="last")
naive_forecaster_last.fit(y_train)
y_last=naive_forecaster_last.predict(fh)
naive_forecaster_seasonal =NaiveForecaster(strategy="seasonal_last",sp=12)
naive_forecaster_seasonal.fit(y_train)
y_seasonal_last=naive_forecaster_seasonal.predict(fh)
plot_ys(y_train,y_test, y_last, y_seasonal_last, labels=["y_train", "y_test", "y_pred_last", "y_pred_seasonal_last"]);
smape_loss(y_last, y_test)
>>0.231957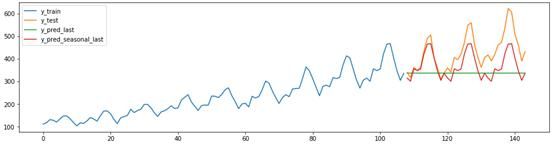
下一个预测片段显示了如何用最小的工作量轻松、正确地调整现有的sklearn回归器来完成预测任务。下方,Sktime的ReducedRegressionForecaste方法使用sklearnRandomForestRegressor模型对序列进行预测。在内部,Sktime将训练数据分割成长度为12的窗口,以便回归器进行训练。
from sktime.forecasting.compose importReducedRegressionForecaster
fromsklearn.ensemble importRandomForestRegressor
fromsktime.forecasting.model_selection import temporal_train_test_split
fromsktime.performance_metrics.forecasting import smape_loss
regressor =RandomForestRegressor()
forecaster=ReducedRegressionForecaster(regressor,window_length=12)
forecaster.fit(y_train)
y_pred= forecaster.predict(fh)
plot_ys(y_train,y_test, y_pred, labels=['y_train', 'y_test', 'y_pred'])
smape_loss(y_test, y_pred)
sktime还包含本地预测方法,如AutoArima。
from sktime.forecasting.arima importAutoARIMA
forecaster=AutoARIMA(sp=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_ys(y_train,y_test, y_pred, labels=["y_train", "y_test", "y_pred"]);
smape_loss(y_test, y_pred)
>>0.07395319887252469
想要更全面地了解Sktime的预测功能,请查看Sktime预测教程。

时间序列的分类
最后,Sktime可以用于将时间序列划分为不同的序列组。在下面的代码示例中,单个时间序列的分类和scikit-learn中的分类一样简单,唯一的区别在于上面讨论的嵌套时间序列数据结构。
from sktime.datasets import load_arrow_head
fromsktime.classification.compose importTimeSeriesForestClassifier
fromsklearn.model_selection import train_test_split
from sklearn.metricsimport accuracy_score
X, y =load_arrow_head(return_X_y=True)
X_train, X_test, y_train,y_test =train_test_split(X, y)
classifier=TimeSeriesForestClassifier()
classifier.fit(X_train, y_train)
y_pred= classifier.predict(X_test)
accuracy_score(y_test, y_pred)
>>0.8679245283018868来源: https://pypi.org/project/sktime/

数据传输至TimeSeriesForestClassifier.
关于时间序列和sktime的基本介绍就到这里啦,如果想要更全面地了解时间序列分类,请查看sktime单变量和多变量分类教程。

一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”
(添加小编微信:dxsxbb,加入读者圈,一起讨论最新鲜的人工智能科技哦~)