Linux系统下安装Python爬虫环境+模拟浏览器插件
一、服务器版本
Centos7以上版本
二、配置python环境
1、安装依赖包
yum -y install gcc gcc-c++
yum -y install zlib zlib-devel
yum -y install bzip2 bzip2-devel
yum -y install ncurses ncurses-devel
yum -y install readline readline-devel
yum -y install openssl openssl-devel
yum -y install openssl-static
yum -y install xz lzma xz-devel
yum -y install sqlite sqlite-devel
yum -y install gdbm gdbm-devel
yum -y install tk tk-devel2、下载anaconda
下载anaconda安装包命令如下:
$ wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-5.0.1-Linux-x86_64.sh
安装过程可参考:https://blog.csdn.net/zhaoyoulin2016/article/details/80776198
- 首先通过xftp将下载好的Anaconda3_linux源文件放到/usr/local文件夹内;
- cd /usr/local 执行如下代码:bash Anaconda3-5.2.0-Linux-x86_64.sh
- 根据提示输入ENTER
如果报错如下:
Anaconda3安装过程中遇到“Anaconda3-5.1.0-Linux-x86_64.sh:行350: bunzip2: 未找到命令 tar: 它似乎不像是一个 tar 归档文件 tar: 由于前次错误,将以上次的错误状态退出”
Anaconda3-5.1.0-Linux-x86_64.sh:行350: bunzip2: 未找到命令 tar: 它似乎不像是一个 tar 归档文件 tar: 由于前次错误,将以上次的错误状态退出
解决办法:
安装bzip2即可解决
yum install -y bzip2
- 输入yes
- 安装完后增加环境变量
vim /root/.bashrc
# added by Anaconda3 4.4.0 installer
export PATH="/root/anaconda3/bin:$PATH"
- 重启环境变量配置
source /root/.bashrc
- 安装完成之后,命令行输入python,查看python版本是否是3.6,如果是则安装成功。如下。

3、安装所需要的python包
涉及到如下的python库:
| 环境 |
版本 |
| Python |
Python3.6 版本 |
| re |
Python自带(2.2.1) |
| time |
Python自带 |
| warnings |
Python自带 |
| psycopg2 |
2.7.7 |
| requests |
2.18.4 |
| pandas |
0.23.4 |
| BeautifulSoup |
4.6.3 |
| impala |
0.14.1 |
| python-Levenshtein(Levenshtein) |
0.12.0 |
| selenium |
3.141.0 |
| zhconv |
|
3.1、首先安装python库
使用pip安装。
pip install --upgrade pip
pip install beautifulsoup4
pip install selenium
pip install psycopg2
pip install requests
pip install pandas
pip install Levenshtein
pip install zhconv导入安装的python库,并测试psycopg2是否可以连接数据库,使用本地的一个数据库进行测试。测试代码如下。
import requests
import re
import pandas as pd
from bs4 import BeautifulSoup
import selenium
import psycopg2
import Levenshtein
import zhconv
conn = psycopg2.connect(database="zjsm", user="postgres", password="root", host="192.168.0.12", port="5432")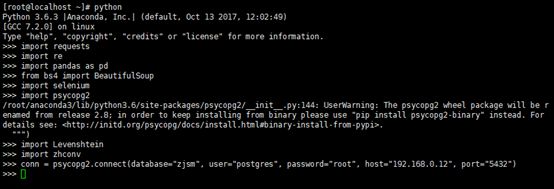
3.2、impala的安装
由于本项目的数据需要与hive数据库连接,故安装impala库。先下载所需的安装包。
pip install pure_sasl==0.5.1
pip install thrift==0.9.3
pip install bitarray==0.8.3
pip install thrift_sasl==0.2.1
pip install thriftpy==0.3.9
pip install impyla==0.14.1若出现问题,可参考https://blog.csdn.net/wx0628/article/details/86550582
测试是否安装成功,可以尝试连接一个本地的hive。测试代码如下。
from impala.dbapi import connect
from impala.util import as_pandas
conn = connect(host='192.168.111.87', port=10000, auth_mechanism='PLAIN', user='root', password='3.1415926', database='zjsm')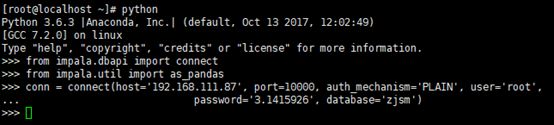
3.3、谷歌浏览器以及对应的驱动安装:chromedriver.exe
安装谷歌浏览器,这里使用文件夹里提供的版本google-chrome-stable_current_x86_64.rpm,只需要将该软件包上传到服务器然后使用如下命令安装:yum localinstall google-chrome-stable_current_x86_64.rpm。
将文件夹里提供的chromedriver上传到服务器,可以放到用户目录下,比如/root/anaconda3目录,然后设置权限,输入命令:chmod 777 chromedriver。
可以将search_url,即https://so.youku.com/search_video/q_少帅放到浏览器搜索,查看是不是少帅,然后将代码最终输出的https://list.youku.com/show/id_z2a6634cea23d11e5b692.html连接使用浏览器测试是不是期望的结果。测试代码如下。
from selenium import webdriver
from bs4 import BeautifulSoup
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
driver = webdriver.Chrome(executable_path="/root/chromedriver",chrome_options=options)
search_url='https://so.youku.com/search_video/q_少帅'
driver.get(search_url)
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
url=soup.select('.row-ellipsis a')[0].get('href')
print(url)#得到:https://list.youku.com/show/id_z2a6634cea23d11e5b692.html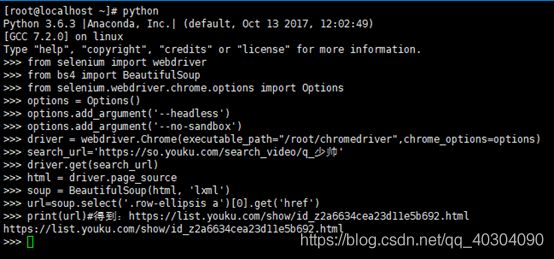
文章未经博主同意,禁止转载!
