PCI/PCI Express体系结构
PCI总线定义了两类配置请求,Type0和Type1配置请求。
HOST主桥或者PCI桥使用Type0配置请求,访问与桥直接相连的PCI设备(桥),而使用Type1配置请求,必须至少与穿越一个PCI桥,从而访问没有与其直接相连的PCI设备(桥),从软件的角度来看,Host主桥通过PCI设备的Bus号来决定用Type0 还是Type1,如果Bus=0,主桥将产生Type0的配置请求,因为与主桥直接相连的所有PCI设备的Bus号都为0,大于0时,Host主桥将产生Type1配置请求,因为过桥(总线)才能使用Type1配置请求。
在PCI总线中,只有PCI桥能够接受Type1配置请求,Type1配置请求不能直接发向最终的PCI agent设备,而只能由PCI桥将其转换为Type1继续发向其他PCI桥,或者转换为Type0配置请求并发向最终的PCIagent设备。
当以下两种请求之一满足时,Host主桥或者PCI桥将生产Type0配置头,并将其发送到指定PCI总线上。
1. CONFIG_ADDRESS寄存器的Bus字段为0,CPU访问COFFIG_DATA寄存器时,HOST主桥直接向PCI总线0发出Type0配置请求
2.当PCI桥收到Type1配置头时,检查Type1配置头的Bus字段,如果这个Bus号与PCI桥的SecondaryBusNumber相同(设备在当前总线上),则将这个Type1的配置请求转换为Type0.
PCI设备的IDSEL信号与PCI总线的AD[31:0]信号的链接关系决定了该设备再这条PCI总线的设备号。再配置读写周期中,AD【10:0】已经被Function和Register使用,因此PCI设备的IDSEL只能与AD【31:11】信号连接。,因此一条PCI总线上最多只能连接21个PCI设备。
PCI规范没有对HOST主桥的设计进行约束,HOST主桥是用来隔离PCI地址空间和存储器地址空间的。PCI总线使用单端并行数据线,采用ID译码进行配置信息传递,采用译码进行数据传递。
PCIe总线概述
PCIe总线的switch中,每一个端口都与一个虚拟PCI桥对应,switch使用这个虚拟PCI桥管理其下PCI总线子树的地址空间。
Address Spaces, Transaction Types, and Usage
Transactions form the basis for information transfer between a Requester and Completer. Four address spaces are defined within the PCI Express architecture, and different Transaction types are defined, each with its own unique intended usage, as shown in Table 2-1.
在地址周期中,C/BE[3:0]信号表示PCI 总线的命令。而在数据周期,C/BE[3:0]引脚输出字节选通信号,其中C/BE3、C/BE2、C/BE1 和C/BE0 与数据的字节3、2、1 和0 对应。使用这组信号可以对PCI 设备进行单个字节、字和双字访问。PCI 总线通过C/BE[3:0]#信号定义了多个总线事务,这些总线事务如表1-2 所示。
IO READ HOST 对PCI 设备的IO地址空间进行读操作
IO WRITE HOST s对PCI总线的IO空间进行写操作
Memory Read HOST 对PCI 设备的memory 空间进行读操作, pci 设备也可以用transaction 读取 CPU的 memory 空间
Memory Write HOST 使用该transcation 对 PCI 设备的memory空间进行写操作, PCI 设备也可使用该transcation 向 CPU的memory 空间进行写 操作
Configuration Read HOST 对 PCI设备的CS空间 进行读操作, 这个transaction只能有 RC发出, PCI 桥可以转发这个transaction
Configuration Write HOST 对PCI设备的配置空间进行写操作
Question:
很显然 MEM read/write 都是双向的, PCI设备读写CPU mem空间, CPU也可以读写PCI的mem空间
配置读操作只能又HOST发出,HOST读 配置空间。
那么其它的呢???都是Host对 PCI 设备的 IO space 的读写吗?????
再来看看PCIE规范上写的
Posted 和Non-Posted 传送方式
PCI 总线规定了两类数据传送方式,分别是Posted 和Non-Posted 数据传送方式。
其中Posted 总线事务指PCI 主设备向PCI 目标设备进行数据传递时,当数据到达PCI 桥后,即由PCI 桥接管来自上游总线的总线事务,并将其转发到下游总线。采用这种数据传送方式,在数据还没有到达最终的目的地之前,PCI 总线就可以结束当前总线事务,从而在一定程度上解决了PCI 总线的拥塞。
而Non-Posted 总线事务是指PCI 主设备向PCI 目标设备进行数据传递时,数据必须到达最终目的地之后,才能结束当前总线事务的一种数据传递方式。
显然采用Posted 传送方式,当这个Posted 总线事务通过某条PCI 总线后,就可以释放PCI 总线的资源;而采用Non-Posted 传送方式,PCI 总线在没有结束当前总线事务时必须等待。这种等待将严重阻塞当前PCI 总线上的其他数据传送
PCI 总线规定只有存储器写请求(包括存储器写并无效请求)可以采用Posted 总线事务,而存储器读请求、I/O 读写请求、配置读写请求只能采用Non-Posted 总线事
HOST 处理器访问PCI设备过程
HOST对PCI agent的数据访问主要包括2部分:
CPU向PCI agent发起的 mem/io 读写请求
CPU 对 PCI agent的配置读写
在PCI 总线中,存储器读写事务的实现。
首先HOST处理器在初始化时,需要将PCI 设备使用的BAR 空间映射到“存储器域”的存储器地址空间。之后处理器通过存储器读写指令访问“存储器域”的存储器地址空间,HOST 主桥将“存储器域”的读写请求翻译为PCI 总线的存储器读写总线事务之后,再发送给目标设备。
值得注意的是,存储器域和PCI 总线域的概念,PCI 设备能够直接使用的地址为PCI 总线域的地址,在PCI 总线事务中出现的地址也为PCI 总线域的地址;而处理器能够直接使用的地址为存储器域的地址
HOST 处理器访问PCI 设备I/O 地址空间的过程。有些处理器,如x86 处理器,具有独立的I/O 地址空间。x86 处理器可以将PCI 设备使用的I/O 地址映射到存储器域的I/O 地址空间中,之后处理器可以使用IN,OUT 等指令对存储器域的I/O 地址进行访问,然后通过HOST 主桥将存储器域的I/O 地址转换为PCI 总线域的I/O 地址,最后使用PCI 总线的I/O 总线事务对PCI 设备的I/O 地址进行读写访问。在x86 处理器中,存储器域的I/O地址与PCI 总线域的I/O 地址相同。
对于有些没有独立I/O 地址空间的处理器,如PowerPC 处理器,需要在HOST 主桥初始化时,将PCI 设备使用的I/O 地址空间映射为处理器的存储器地址空间。PowerPC 处理器对这段“存储器域”的存储器空间进行读写访问时,HOST 主桥将存储器域的这段存储器地址转换为PCI总线域的I/O 地址,然后通过PCI 总线的I/O 总线事务对PCI 设备的I/O 地址进行读写操作。
PCI设备读写CPU memory space
PCI设备与CPU memory space直接进行数据交换的过程是DMA。 PCI设备DMA时,使用的 目的地址 是 PCI总线filed的物理地址,而不是CPU memory space的物理地址, 因为PCI 设备并不能识别 CPU memory的物理地址, PCI设备只能识别PCI 总线space的物理地址,这在任何情况下都是成立的。
HOST 主桥负责完成 PCI总线地址和 CPU memory总线的地址转换翻译, 只有将CPU 的 memory space地址空间映射 mapping 到PCI总线后,PCI设备才能对这段 CPU 地址空间的 memory space进行 DMA 操作, PCI设备不能直接访问 没有经过host 主桥映射过的 CPU memory空间。
许多CPU允许 PCI 设备访问 所有 CPU memory 的地址空间,但是有些CPU可以设置PCI设备所能访问的CPU memory 的地址空间,从而对CPU 的memory地址空间进行保护,如PowerPC,Host主桥可以使用Inbound寄存器组,设置PCI设备能访问的CPU memory的地址范围和属性。只有在Inbound寄存器组映射过的CPU memory空间地址范围内的才能被PCI设备访问。
Anyway, 由于存在HOST主桥映射的关系, CPU memory地址空间实际上具有“两层”地址意义:
一个是 在 CPU 地址空间中的地址, 当CPU访问这段地址是,它代表的就是CPU地址
另一个是PCI总线域的PCI总线地址,当PCI设备访问这段内存时, 它代表的就是PCI总线地址。
流程: PCI设备永远只能访问PCI地址空间,因此它先访问到的一定是PCI域地址,然后这个地址会被Inbound映射到CPU memory地址空间,一般是1:1,这要以后实际上等于 PCI设备访问到了CPU的memory地址空间域了,但是实际上不是,只是一种映射~!。
今天又在此读了一遍 PCIe的书,感觉这次对映射关系有了新的恕不认识,现在记录下来一些心得:
首先搞清方向,是从哪里到哪里
CPU 到 PCI 设备 方向的叫 oubbound
PCI设备到 CPU方向的 叫 inbound
这两个方向都可以实现 各种总线transcation, 配置空间的访问只能是outbound方向的
outbound方向是 把PCI设备映射到CPU的地址空间中去,这里所指的PCI设备实际上是PCI的BAR地址空间,其实也就是PCI设备的寄存器, 终极目的是PCI设备的寄存器映射到CPU地址空间上,让CPU直接访问,但是实际上中间还是有一层转换, Eg: CPU PMW(post memory write) 到PCI设备, 首先把数据写入寄存器,然后TLP带地址是CPU地址,这个地址被outbound寄存器映射到PCI地址空间上,接着一层一层下发认领,查找,找到最终要写的设备后写入, Mw是post,到达第一级bridge时就返回,其它的必须带着最终数据返回.
inbound 方向是从 PCI设备到CPU的,可以发起各种总线transcation, 这个方向一般都是DMA read/write操作. 这个目的主要是指定把那些CPU memory地址空间指定给PCI设备使用和访问.
Eg: NIC设备, 就是把PCI设备上的SRAM里的数据DMA到CPU memory地址空间上,这个过程全部是DMA实现, Eg: PCI PMW到CPU memory, mw操作需要指定一个目的地址, 这个地址一定是PCI总线空间的,当这个地址达到HOST主桥时将被inbound 翻译成 CPU地址空间地址,最终把数据写入memory,读也是一样,只是会把数据带回来.
IO READ HOST 对PCI 设备的IO地址空间进行读操作
IO WRITE HOST s对PCI总线的IO空间进行写操作
Memory Read HOST 对PCI 设备的memory 空间进行读操作, pci 设备也可以用transaction 读取 CPU的 memory 空间
Memory Write HOST 使用该transcation 对 PCI 设备的memory空间进行写操作, PCI 设备也可使用该transcation 向 CPU的memory 空间进行写 操作
Configuration Read HOST 对 PCI设备的CS空间 进行读操作, 这个transaction只能有 RC发出, PCI 桥可以转发这个transaction
Configuration Write HOST 对PCI设备的配置空间进行写操作
Question:
很显然 MEM read/write 都是双向的, PCI设备读写CPU mem空间, CPU也可以读写PCI的mem空间
配置读操作只能又HOST发出,HOST读 配置空间。
那么其它的呢???都是Host对 PCI 设备的 IO space 的读写吗?????
再来看看PCIE规范上写的
Posted 和Non-Posted 传送方式
PCI 总线规定了两类数据传送方式,分别是Posted 和Non-Posted 数据传送方式。
其中Posted 总线事务指PCI 主设备向PCI 目标设备进行数据传递时,当数据到达PCI 桥后,即由PCI 桥接管来自上游总线的总线事务,并将其转发到下游总线。采用这种数据传送方式,在数据还没有到达最终的目的地之前,PCI 总线就可以结束当前总线事务,从而在一定程度上解决了PCI 总线的拥塞。
而Non-Posted 总线事务是指PCI 主设备向PCI 目标设备进行数据传递时,数据必须到达最终目的地之后,才能结束当前总线事务的一种数据传递方式。
显然采用Posted 传送方式,当这个Posted 总线事务通过某条PCI 总线后,就可以释放PCI 总线的资源;而采用Non-Posted 传送方式,PCI 总线在没有结束当前总线事务时必须等待。这种等待将严重阻塞当前PCI 总线上的其他数据传送
PCI 总线规定只有存储器写请求(包括存储器写并无效请求)可以采用Posted 总线事务,而存储器读请求、I/O 读写请求、配置读写请求只能采用Non-Posted 总线事
HOST 处理器访问PCI设备过程
HOST对PCI agent的数据访问主要包括2部分:
CPU向PCI agent发起的 mem/io 读写请求
CPU 对 PCI agent的配置读写
在PCI 总线中,存储器读写事务的实现。
首先HOST处理器在初始化时,需要将PCI 设备使用的BAR 空间映射到“存储器域”的存储器地址空间。之后处理器通过存储器读写指令访问“存储器域”的存储器地址空间,HOST 主桥将“存储器域”的读写请求翻译为PCI 总线的存储器读写总线事务之后,再发送给目标设备。
值得注意的是,存储器域和PCI 总线域的概念,PCI 设备能够直接使用的地址为PCI 总线域的地址,在PCI 总线事务中出现的地址也为PCI 总线域的地址;而处理器能够直接使用的地址为存储器域的地址
HOST 处理器访问PCI 设备I/O 地址空间的过程。有些处理器,如x86 处理器,具有独立的I/O 地址空间。x86 处理器可以将PCI 设备使用的I/O 地址映射到存储器域的I/O 地址空间中,之后处理器可以使用IN,OUT 等指令对存储器域的I/O 地址进行访问,然后通过HOST 主桥将存储器域的I/O 地址转换为PCI 总线域的I/O 地址,最后使用PCI 总线的I/O 总线事务对PCI 设备的I/O 地址进行读写访问。在x86 处理器中,存储器域的I/O地址与PCI 总线域的I/O 地址相同。
对于有些没有独立I/O 地址空间的处理器,如PowerPC 处理器,需要在HOST 主桥初始化时,将PCI 设备使用的I/O 地址空间映射为处理器的存储器地址空间。PowerPC 处理器对这段“存储器域”的存储器空间进行读写访问时,HOST 主桥将存储器域的这段存储器地址转换为PCI总线域的I/O 地址,然后通过PCI 总线的I/O 总线事务对PCI 设备的I/O 地址进行读写操作。
PCI设备读写CPU memory space
PCI设备与CPU memory space直接进行数据交换的过程是DMA。 PCI设备DMA时,使用的 目的地址 是 PCI总线filed的物理地址,而不是CPU memory space的物理地址, 因为PCI 设备并不能识别 CPU memory的物理地址, PCI设备只能识别PCI 总线space的物理地址,这在任何情况下都是成立的。
HOST 主桥负责完成 PCI总线地址和 CPU memory总线的地址转换翻译, 只有将CPU 的 memory space地址空间映射 mapping 到PCI总线后,PCI设备才能对这段 CPU 地址空间的 memory space进行 DMA 操作, PCI设备不能直接访问 没有经过host 主桥映射过的 CPU memory空间。
许多CPU允许 PCI 设备访问 所有 CPU memory 的地址空间,但是有些CPU可以设置PCI设备所能访问的CPU memory 的地址空间,从而对CPU 的memory地址空间进行保护,如PowerPC,Host主桥可以使用Inbound寄存器组,设置PCI设备能访问的CPU memory的地址范围和属性。只有在Inbound寄存器组映射过的CPU memory空间地址范围内的才能被PCI设备访问。
Anyway, 由于存在HOST主桥映射的关系, CPU memory地址空间实际上具有“两层”地址意义:
一个是 在 CPU 地址空间中的地址, 当CPU访问这段地址是,它代表的就是CPU地址
另一个是PCI总线域的PCI总线地址,当PCI设备访问这段内存时, 它代表的就是PCI总线地址。
流程: PCI设备永远只能访问PCI地址空间,因此它先访问到的一定是PCI域地址,然后这个地址会被Inbound映射到CPU memory地址空间,一般是1:1,这要以后实际上等于 PCI设备访问到了CPU的memory地址空间域了,但是实际上不是,只是一种映射~!。
今天又在此读了一遍 PCIe的书,感觉这次对映射关系有了新的恕不认识,现在记录下来一些心得:
首先搞清方向,是从哪里到哪里
CPU 到 PCI 设备 方向的叫 oubbound
PCI设备到 CPU方向的 叫 inbound
这两个方向都可以实现 各种总线transcation, 配置空间的访问只能是outbound方向的
outbound方向是 把PCI设备映射到CPU的地址空间中去,这里所指的PCI设备实际上是PCI的BAR地址空间,其实也就是PCI设备的寄存器, 终极目的是PCI设备的寄存器映射到CPU地址空间上,让CPU直接访问,但是实际上中间还是有一层转换, Eg: CPU PMW(post memory write) 到PCI设备, 首先把数据写入寄存器,然后TLP带地址是CPU地址,这个地址被outbound寄存器映射到PCI地址空间上,接着一层一层下发认领,查找,找到最终要写的设备后写入, Mw是post,到达第一级bridge时就返回,其它的必须带着最终数据返回.
inbound 方向是从 PCI设备到CPU的,可以发起各种总线transcation, 这个方向一般都是DMA read/write操作. 这个目的主要是指定把那些CPU memory地址空间指定给PCI设备使用和访问.
Eg: NIC设备, 就是把PCI设备上的SRAM里的数据DMA到CPU memory地址空间上,这个过程全部是DMA实现, Eg: PCI PMW到CPU memory, mw操作需要指定一个目的地址, 这个地址一定是PCI总线空间的,当这个地址达到HOST主桥时将被inbound 翻译成 CPU地址空间地址,最终把数据写入memory,读也是一样,只是会把数据带回来.
PCI-E之MSI和MSI-X中断机制
PCI总线中,INTx中断是必须的,MSI是可选。
PCI-e总线中,MSI或者MSI-X必须支持而可以不支持INTx中断,但是pcie总线中可能出现pci设备,pci设备不支持MSI,因此还得保留INTx中断。
在PCI-E总线中,MSI和MSI-X中断机制本质是memory write transaction(存储器写请求)向处理器提交中断。如PowperPC,MSI和MSI-X中断先提交到EPIC中断控制器的Shared Message Signaled Interrupt,在由EPIC提交给core。
INTx是电平出发方式,有极性,有电平。MSI与MSI-X机制是边沿出发,这两种中断触发方式不同。与INTx中断相比,MSI可以更合理的处理PCIe总线的"序", 当设备向内存写入数据,然后发起引脚中断时,有可能在CPU收到中断时,数据还未到达内存(在PCI-PCI桥后的设备更有可能如此)。为了保证数据已达 内存,中断处理程序必须轮询产生该中断的设备的一个寄存器,PCI事务保序规则会确保所有数据到达内存后,寄存器才会返回值。使用MSI时,产生中断的写不能越过数据写,因而避免了这个问题。当中断产生时,驱动可以确信所有数据已经到达内存。

6.7. Capabilities List
This optional data structure is indicated in the PCI Status Register by setting the Capabilities List bit (bit 4) to
indicate that the Capabilities Pointer is located at offset 34h. This register points to the first item in the list of capabilities.
Each capability in the list consists of an 8-bit ID field assigned by the PCI SIG,an 8 bit pointer in configuration space to the next capability, and some number of additional
registers immediately following the pointer to implement that capability. Each capability must be DWORD aligned. The bottom two bits of all pointers (including the initial pointer
at 34h) are reserved and must be implemented as 00b although software must mask them to allow for future uses of these bits. A pointer value of 00h is used to indicate the last
capability in the list. Figure 6-10 shows how this list is constructed.


/* Capabilities List Implemented: Get first capability ID */
VXB_PCI_CFG_READ(busCtrlID, &phard, 0x34, 1, &devCapID); /* capability pointer @0x34 */
/* Longword Align */
devCapID = devCapID & (UINT8)(~0x03);
while (devCapID)
{
printf("Capabilities - ");
VXB_PCI_CFG_READ(busCtrlID, &phard, devCapID, 1, &cap_id);/* 第一个字节save ID */
VXB_PCI_CFG_READ(busCtrlID, &phard, devCapID+1, 1, &cap_id_next); /* 第二个字节save下一个Cap的地址 */
/* longword align */
cap_id_next = cap_id_next & (UINT8)(~0x03);
/* Enhancement: Dump specific capabilities regs */
if (cap_id == 0xff)
/* Get Out - something is wrong */
break;
devCapID = cap_id_next;
}Capability IDs

MSI Capability Structure
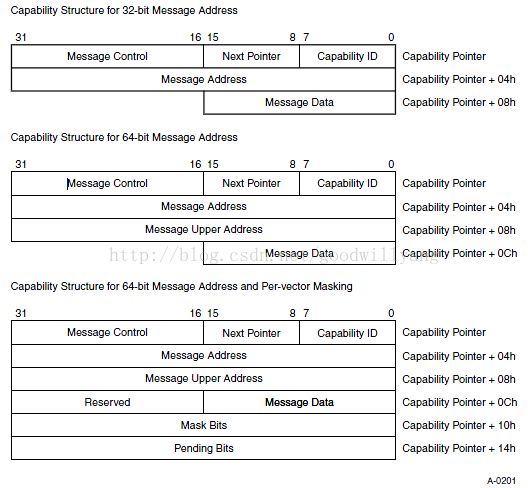
MSI-X Capability & Table Structures
the MSI-X capability structure contains a BAR Indicator register (BIR) and Table Offset register. The separate MSI-X Table structure typically contains multiple entries,
each consisting of a Message Address field and Message Data field, and thus capable of specifying a unique vector. The MSI-X Table is mapped by the Base Address register
indicated by the BIR, which refers to one of the function’s Base Address registers located beginning at 10h in Configuration Space.

Generating Messages
To send a message, a function does a DWORD memory write to the appropriate message address with the appropriate message data.
For MSI, the DWORD that is written is made up of the value in the MSI Message Data register in the lower two bytes and zeroes in the upper two bytes.
For MSI-X, the MSI-X Table contains at least one entry for every allocated vector, and the 32-bit Message Data field value from a selected table entry is used in the message without
any modification to the low-order bits by the function.
PowperPC MSI处理流程
PCIe 设备申请MSI中断成功后,挂接设备ISR并且enable,当PCIe 通过 memory write 产生一个MSI msg,MSI Message address由inbound映射到CPU地址空间,正好是对应EPIC的MSIIR寄存器地址,因此产生Share MSI中断,CPU被中断后,读取ACK获取中断向量号执行对应的ISR,在再Share MSI的ISR中再来查找看是哪个MSI中断产生(powerpc一个bank 支持8*32个MSI中断),最后在调挂在这个MSI中断向量上的ISR执行。