strom学习(二)——storm源码解析与wordcount案例解析
笔者是一个痴迷于挖掘数据中的价值的学习人,希望在平日的工作学习中,挖掘数据的价值,找寻数据的秘密,笔者认为,数据的价值不仅仅只体现在企业中,个人也可以体会到数据的魅力,用技术力量探索行为密码,让大数据助跑每一个人,欢迎直筒们关注我的公众号,大家一起讨论数据中的那些有趣的事情。
我的公众号为:livandata

1、Storm源码下载及目录熟悉
1.1、在Storm官方网站上寻找源码地址
http://storm.apache.org/downloads.html

1.2、点击文字标签进入github
点击Apache/storm文字标签,进入github
https://github.com/apache/storm
1.3、拷贝storm源码地址
在网页右侧,拷贝storm源码地址

1.4、使用Subversion客户端下载
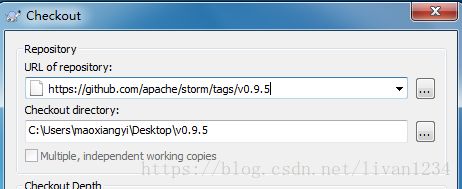
https://github.com/apache/storm/tags/v0.9.5
1.5、Storm源码目录分析(重要)

扩展包中的三个项目,使storm能与hbase、hdfs、kafka交互

2、Storm单词技术案例(重点掌握)
2.1、功能说明
设计一个topology,来实现对文档里面的单词出现的频率进行统计。
整个topology分为三个部分:
- RandomSentenceSpout:数据源,在已知的英文句子中,随机发送一条句子出去。
- SplitSentenceBolt:负责将单行文本记录(句子)切分成单词
- WordCountBolt:负责对单词的频率进行累加
2.2、项目主要流程

对应的解释为:
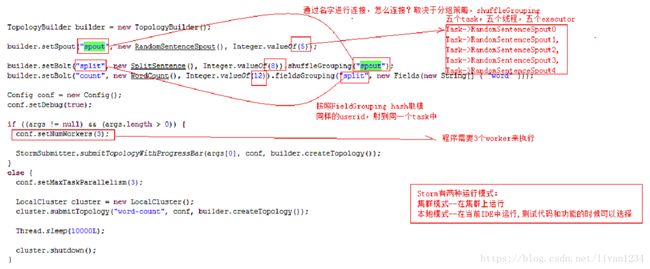
1)TopologyBuilder builder = new TopologyBuilder();创建一个Topology;
2)// 设置并发的数量
builder.setSpout("spout", new RandomSentenceSpout(), 5);
builder.setBolt("split", new SplitSentence(), 8).shuffleGrouping("spout");
builder.setBolt("count", new WordCount(), 12).fieldsGrouping("split", new Fields("word"));
在现有的topology中加入spout、split与count,这三个值主要用作UI中的三个值,做并发的设置:
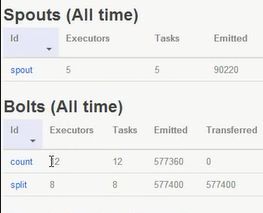
上面的两个spout是通过名称连接:其中的5表示有5个task,8和12分别表示8个和12个task;
split也是连在一起的(按照fieldgrouping连接,hash取模,同样的userid,发射到同一个task中);
conf.setNumWorkers(3);表示上面的25个task运行在三个worker上。
Storm一般有两种类型:
- 集群模式在集群上运行;
- 本地模式在当前的IDE中运行,测试代码和功能的时候可以选择。
通过查看源码可以发现:
if (args != null && args.length > 0) :则使用集群模式;
else:则使用本地模式。
2.3、RandomSentenceSpout的实现及生命周期

2.4、SplitSentenceBolt的实现及生命周期

2.5、WordCountBolt的实现及生命周期

Storm的wordcounter的案例:

Storm的流程:
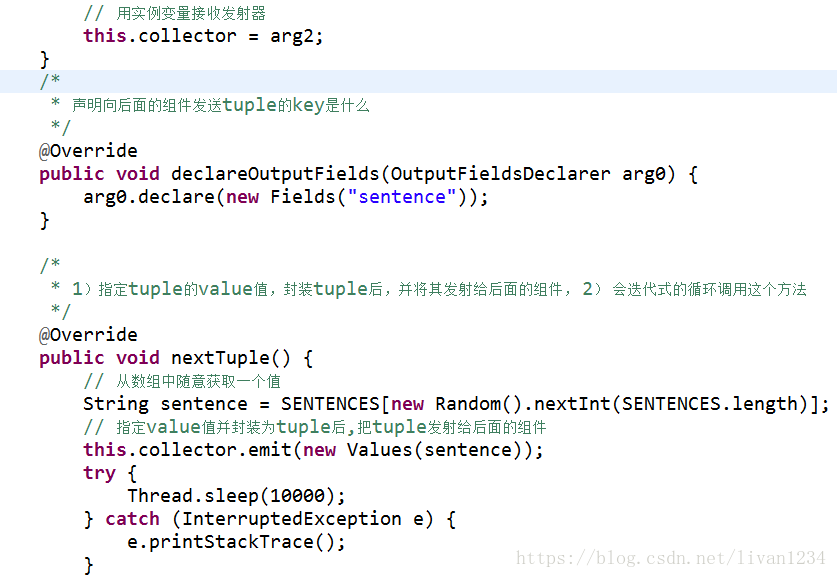
Spout读取数据,然后splitBolt获取到line,切成一个个单词,输出新的tuple,这个tuple中有切割的单词word,将这些单词发射到多个wordcountBolt中,各个wordcountBolt对单词进行计数。
splitBolt获取到line:
在源码中这一功能主要是在wordcountTopology中实现:在nextTuple中将sentence发射给splitsentenceBolt,在splitsentenceBolt中有execute方法:

然后将数据发送给wordcountBolt,再进行计数运算。
3、Wordcount的案例代码为:

对应各个节点的代码为:
(一):

(二):
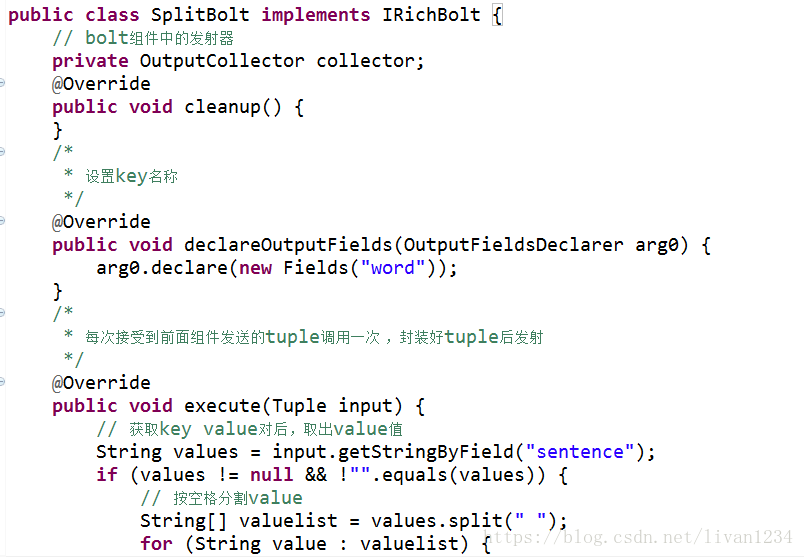

(三):


(四):

(五):
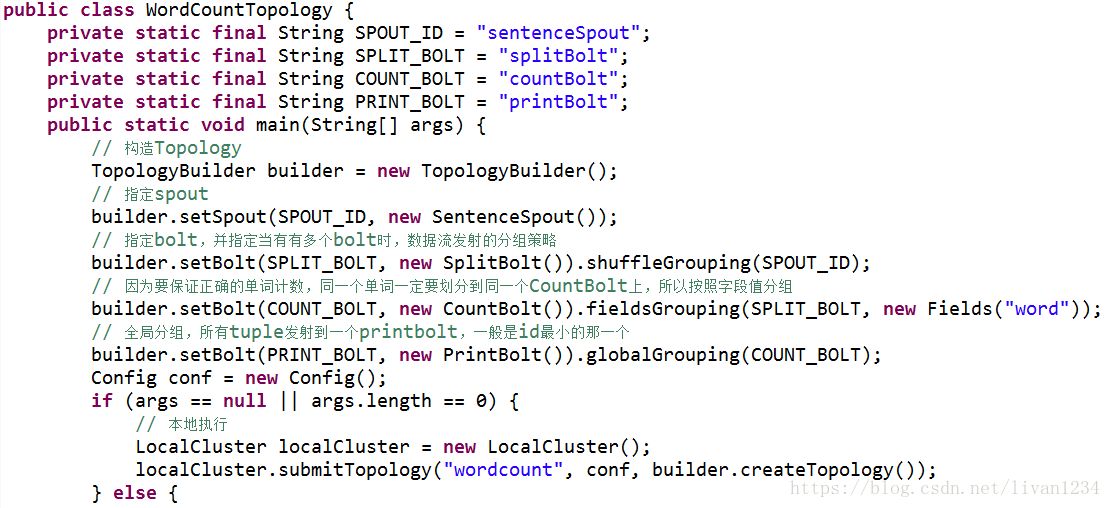

本地测试为:

storm集群部署:
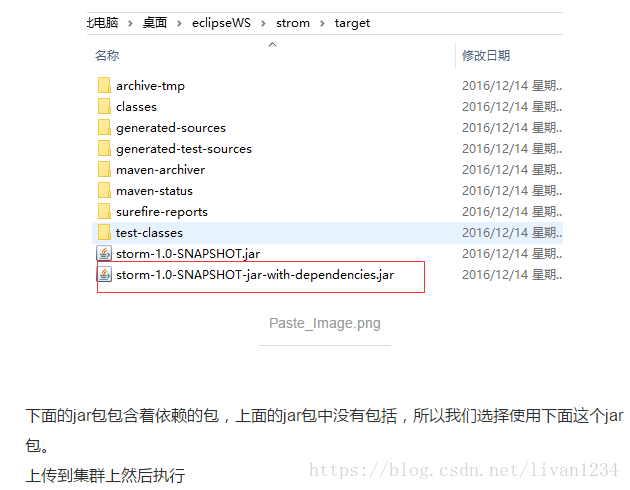
$ bin/storm jar storm-1.0-SNAPSHOT-jar-with-dependencies.jar strom.strom.WordCountTopology wordcount
在UI中的显示:
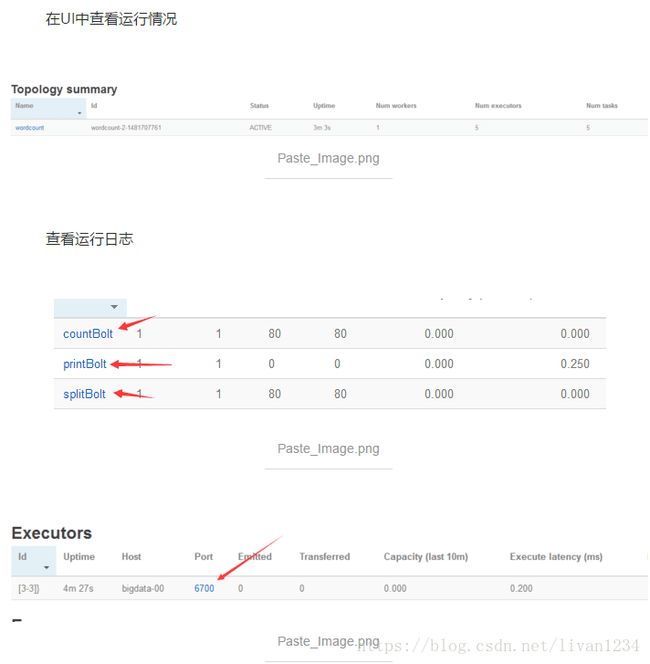
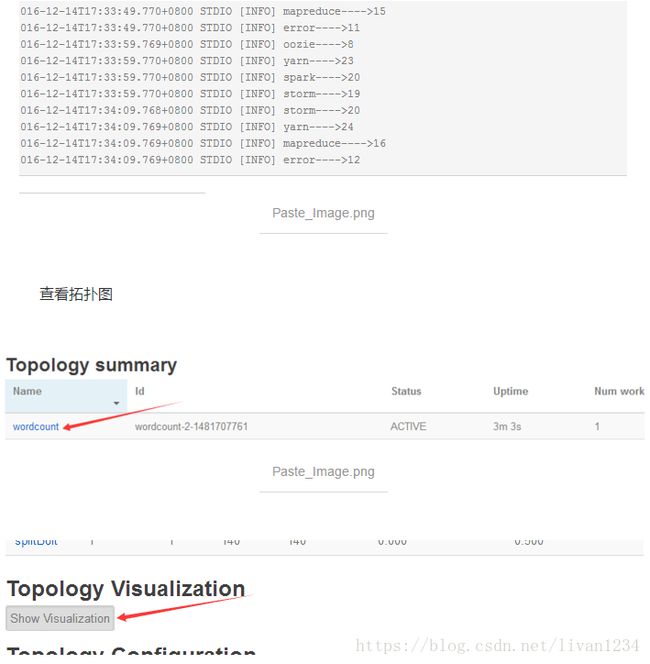

以上案例引用自:https://www.jianshu.com/p/c6c038ac5d35
4、Stream Grouping详解
Storm里面有7种类型的stream grouping
- Shuffle Grouping: 随机分组, 随机派发stream里面的tuple,保证每个bolt接收到的tuple数目大致相同。
- Fields Grouping:按字段分组,比如按userid来分组,具有同样userid的tuple会被分到相同的Bolts里的一个task,而不同的userid则会被分配到不同的bolts里的task。
- All Grouping:广播发送,对于每一个tuple,所有的bolts都会收到。
- Global Grouping:全局分组, 这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
- Non Grouping:不分组,这stream grouping个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果, 有一点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行。
- Direct Grouping: 直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)。
- Local or shuffle grouping:如果目标bolt有一个或者多个task在同一个工作进程中,tuple将会被随机发生给这些tasks。否则,和普通的Shuffle Grouping行为一致。
补充:
1、shufflegrouping与fieldgrouping的不同:

Shuffle:随机分,则task会随机的给到下面的bolt;
Field:按照相同字段分,则key为word的tuple中,相同value的task会分到同一个bolt;
2、storm的可靠性机制:
storm中运行会形成基于tuple的tuple树,这个tuple树是在spout和bolt拓扑之间运行的:

在这个拓扑图以及tuple树种,storm的运行非常稳健,主要依赖于两个方面:
1)nimbus与supervisor的数据存储在zookeeper和硬盘中,任何一个组件出现问题,不会影响数据;
2)拓扑图中使用了acker机制:
当Spout发射完某个MessageId对应的源Tuple之后,它会告诉Acker自己发射的RootId以及生成的那些源Tuple的Id。而当Bolt处理完一个输入Tuple并产生出新的Tuple时,也会告知Acker自己处理的输入Tuple的Id以及新生成的那些Tuple的Id。Acker只需要对这些Id进行异或运算,就能判断出该RootId对应的消息单元是否成功处理完成了,当发现整体的tuple树全部执行完了,则返回tuple执行完的指令,调用ack;如果整体的tuple树不能执行完成,则返回fail,这个tuple树会被返回到队列中,等待线程,重新执行。
acker的数据主要分三部分:spout-root-id(用来记录原始tuple的id,ack每次调用都会根据这个id来遍历tuple树),tuple-id(用来标记当下的task),ack val(用来标识tuple树是否完全执行完成,如果完全执行完成则ack val=0)。
ack val的值主要是通过对tuple的id进行异或操作实现的:
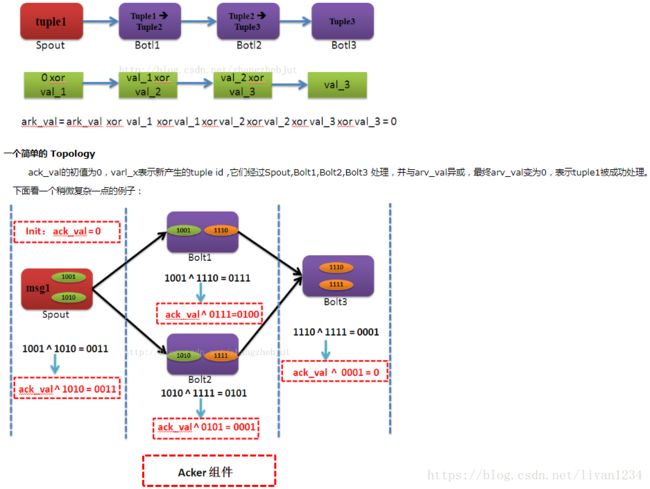
上面即为tupleid的异或操作:
ack val = 1001^1010^1001^1110^1010^1111^1110^1111=0
由公式可以发现,每个id被运行两次,当缺少某一个id时,上面的运算便不可能得到0.
具体的细节可以参考以下文章,写的非常详细:
https://www.cnblogs.com/hd3013779515/p/6971875.html