Java使用freemarker导出带图片的word文档
1.用Microsoft Office Word打开word原件;
2.把需要动态修改的内容替换成${XX}的形式,如果有图片,尽量选择较小的图片几十K左右的小图片,并调整好位置,占位(小图片转换的base64数据少,便于修改);如下图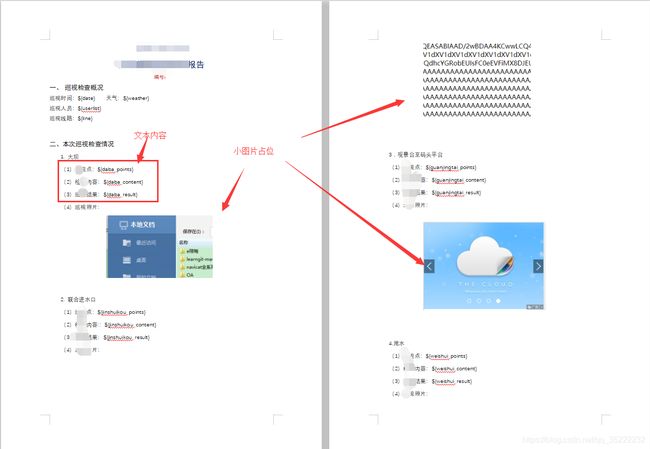
3.另存为,选择保存类型Word 2003 XML 文档(*.xml)【这里说一下为什么用Microsoft Office Word打开且要保存为Word 2003XML,本人亲测,用WPS找不到Word 2003XML选项,如果保存为Word XML,会有兼容问题,避免出现导出的word文档不能用Word 2003打开的问题】,保存的文件名不要是中文
4.用notepad++打开文件;
5. 将文档内容中需要动态修改内容的地方,换成freemarker的标识。其实就是Map
6.在加入了图片占位的地方,会看到一片base64编码后的代码,把base64替换成${image},也就是Map
代码如:
注意:“>${xx}<”这尖括号中间不能加任何其他的诸如空格,tab,换行等符号。
如果需要循环,则使用:<#list maps as map> maps是Map

7. 标识替换完之后,模板就弄完了,另存为.ftl后缀文件即可。注意:一定不要用word打开ftl模板文件,否则xml内容会发生变化,导致前面的工作白做了。把最开始得到的doc模板文件和ftl文件放在同一级目录下
8.代码部分
pom:
org.apache.poi
poi-scratchpad
3.8
org.jfree
jfreechart
1.0.19
org.freemarker
freemarker
2.3.23
工具类:
import freemarker.template.Configuration;
import freemarker.template.Template;
import freemarker.template.TemplateException;
import sun.misc.BASE64Decoder;
import sun.misc.BASE64Encoder;
import javax.servlet.http.HttpServletRequest;
import java.io.*;
import java.util.HashMap;
import java.util.Map;
public class DoOffice_word_freemarker {
private Configuration configuration = null;
public DoOffice_word_freemarker() {
configuration = new Configuration();
configuration.setDefaultEncoding("utf-8");
}
public void createDoc(HttpServletRequest request, Map dataMap, String fileName)
throws IOException {
// dataMap 要填入模本的数据文件
//模板地址
String tmpFile = request.getSession().getServletContext().getRealPath("/WEB-INF");
configuration.setDirectoryForTemplateLoading(new File(tmpFile));
Template t = configuration.getTemplate("template.ftl");
// 输出文档路径及名称
File outFile = new File(fileName);
Writer out = null;
FileOutputStream fos = null;
try {
fos = new FileOutputStream(outFile);
OutputStreamWriter oWriter = new OutputStreamWriter(fos, "UTF-8");
// 这个地方对流的编码不可或缺,使用main()单独调用时,应该可以,但是如果是web请求导出时导出后word文档就会打不开,并且包XML文件错误。主要是编码格式不正确,无法解析。
// out = new BufferedWriter(new OutputStreamWriter(new
// FileOutputStream(outFile)));
out = new BufferedWriter(oWriter);
} catch (FileNotFoundException e1) {
e1.printStackTrace();
}
try {
t.process(dataMap, out);
out.close();
fos.close();
} catch (TemplateException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
// System.out.println("---------------------------");
}
// 图片处理
public static String getImageStr() {
String imgFile = "f:/123.png";
InputStream is = null;
byte[] data = null;
try {
is = new FileInputStream(imgFile);
data = new byte[is.available()];
is.read(data);
is.close();
} catch (IOException e) {
e.printStackTrace();
}
BASE64Encoder encoder = new BASE64Encoder();
return encoder.encode(data);
}
public static boolean Base64ToImage(String imgStr,String imgFilePath) {
// 对字节数组字符串进行Base64解码并生成图片
BASE64Decoder decoder = new BASE64Decoder();
try {
// Base64解码
byte[] b = decoder.decodeBuffer(imgStr);
for (int i = 0; i < b.length; ++i) {
if (b[i] < 0) {// 调整异常数据
b[i] += 256;
}
}
OutputStream out = new FileOutputStream("f:/123.png");
out.write(b);
out.flush();
out.close();
return true;
} catch (Exception e) {
return false;
}
}
public static void main(String[] args) throws IOException {
Base64ToImage("","");
Map datas = new HashMap();
datas.put("bianhao", "1232");
datas.put("dushuyi", "1235");
datas.put("weizhi", "1423");
datas.put("tuzhi", "25123");
datas.put("kongshen", "1我23");
datas.put("ksshuiwei", "123");
datas.put("endshuiwei","请问123");
datas.put("kstime", "123");
datas.put("endtime", "1啊23");
datas.put("counttime", "123");
datas.put("result", "1夫人23");
datas.put("img", getImageStr().substring(22,getImageStr().length()));
Map dataMap = new HashMap();
dataMap.put("photo", getImageStr().substring(22,getImageStr().length()));
dataMap.put("name", "Blue");
dataMap.put("gender", "男");
dataMap.put("birth", "1992-2-2");
dataMap.put("grade", "1203班");
dataMap.put("major", "软件");
dataMap.put("Id", "201219010110");
dataMap.put("phone", "123456");
dataMap.put("roomId", "S-222");
dataMap.put("zhengzhi", "团员");
dataMap.put("IdCard", "411322199202022212");
dataMap.put("address", "河南省郑州市地球村");
dataMap.put("parent_phone1", "11111111");
dataMap.put("parent_phone2", "22222222");
dataMap.put("gold", "这里是目标,新学期新气象,好好学习,天天向上");
DoOffice_word_freemarker mdoc = new DoOffice_word_freemarker();
//mdoc.createDoc(datas, "d:/00.docx");
//System.out.println(getImageStr().substring(22,getImageStr().length()));
}
} 通过图片地址获取图片然后转换成base64格式:
public static String GetImageStrFromUrl(String imgURL) {
byte[] data = null;
try {
// 创建URL
URL url = new URL(imgURL);
// 创建链接
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
conn.setConnectTimeout(5 * 1000);
InputStream inStream = conn.getInputStream();
int count = conn.getContentLength();
data = new byte[count];
int readCount = 0;
while (readCount主业务代码:
/**
* WORD导出
*/
@RequestMapping(value = "/word", method= RequestMethod.GET)
@ResponseBody
public String word(HttpServletRequest request) throws Exception {
//模板地址(把最开始得到的doc模板文件和ftl文件放在同一级目录下)
String tmpFile = request.getSession().getServletContext().getRealPath("/WEB-INF/template.doc");
//导出文件保存地址/usr/apache-tomcat-7.0.69/webapps/template.doc
String expFile = "D:/"+ DateUtils.getToday() +".doc";
String daba_points = "JH-05";
String daba_content = "查xx。";
String daba_result = getResult("J1H-05");
String daba_images = FileUtil.GetImageStrFromUrl("图片地址");
Map datas = new HashMap();
datas.put("daba_points", daba_points);
datas.put("daba_content", daba_content);
datas.put("daba_result",daba_result);
datas.put("daba_images", daba_images);
DoOffice_word_freemarker mdoc = new DoOffice_word_freemarker();
mdoc.createDoc(request,datas, expFile);
return daba_images;
} 成果:
