论文阅读:Task-Free Continual Learning
Task-Free Continual Learning
来自CVPR2019,比利时鲁汶大学 。
当前continual learning常假设,一次一个任务,所有当前数据可用,之前数据不可用。这个硬任务边界条件现实不常满足。
本文提出的系统学习流数据,分布不断变化,不同任务间没有区分。本文方法基于Memory Aware Synapses,提供了以下协议将其转化为online的:
- 何时 更新重要权重
- 更新时 用哪个数据
- 如何在更新时 累积权重重要性
该模型在以下任务上的实验结果展现了有效性:(自)监督人脸识别 ,避免冲撞的机器人。
1.Introduction
机器学习训练与测试阶段是界限分明的,假设了一个静态的世界,其中数据分布不会改变。这种强划分有助于开发算法,但也加上了限制。
受生物系统启发,IL(也可以叫CL、LL)关注打破训练和测试之间的屏障。这个系统累积知识,准确率和适用范围随时间增加。现实中,数据可能因存储和隐私原因不能保留,而只用后来的数据会引入偏差(遗忘)。
像那种一个个依次任务数据可用的学习,本文称作task-based sequential learning,本文目标在于克服这种对硬任务边界的需求。我们探索task-based方法如何普遍地转化为online方法——一个决定何时巩固知识的协议;难样本buffer——从强化学习的experience replay获得启发,一个小得多的replay buffers。
task-based方法一般学习分类任务,为新类在输出层加分类头。与之相反,我们的方法固定输出:人脸识别中我们通过嵌入识别;机器人中,不是输出标签变化,而是环境变化。此两种任务,数据以流来处理,不是i.i.d,有样本不均衡问题。
本文贡献:1.第一个扩展task-based to在线持续学习;2.protocols to integrate an importance weight regularizer, MAS;3.在数据分布变化的场景中证明我们方法的有效性。
2.Related work
Online Learning
传统离线学习要全部数据可用,online方法用stream of data instances学习。
首先是线性模型,kernel学习将其扩展到非线性,然后是神经网络,度量学习。
应用上Pernici的方法和我们第一个应用场景接近:temporal consistency,Detector and descriptor,memory of detected faces。不同的是,我们从弱得多的预训练模型开始,并随时间更新模型。
Continual Learning
Hsu把持续学习的场景分为:incremental task learning ,incremental domain learning, incremental class learning。他认为后两者重要。迄今为止大部分方法的设置都基于task-based sequential learning。
- 正则化方法:EWC,Synaptic Intelligence,Memory Aware Synapses(MAS,同作者..)。
虽然Synaptic intelligence是在线计算权重重要性的,但更新仍在任务结束,因此也是依赖任务边界的。
Incremental Moment Matching基于相似的思想,存储不同模型以完成不同任务,仅在最后合并。尚不清楚如何将其扩展到在线。 - 动态可扩展网络:Lifelong learning with dynamically expandable networks.,利用新旧任务相似性选择可重用神经元,并添加新神经元学习新知识(和CPG思想类似)
- 数据驱动:lwf,encoder based lifelong learning。知识蒸馏损失,不清楚如何应用到未知任务标识的情况。
- episodic memory:iCaR,GEM...,DRL:replay buffer,但是有1M之多,这里我们只用100。
DRL有技术名为“prioritized sweeping”,排除掉buffer里的简单样本,而非老样本。
3.Method
taskbased训练可分为多个阶段,In between the training phases, when training has stabilized, the continual learning method updates its meta-knowledge on how to avoid forgetting previous tasks.
我们研究决定MAS,其特性:1.固定存储需求:只存储每个参数的重要性 2.task agnostic:可用于任何任务,特别地,可以输出一个嵌入 3.快:惩罚梯度只是每个参数的变化乘其重要性 4.顶级性能:比其他正则化方法好。
为将MAS应用到在线CL,我们要确定:1.何时 更新重要权重 2.更新时用 哪个 数据 3.如何 在更新步中累积权重重要性。
- setup
假设一个无限的数据流,和一个由少量连续样本生成的监督或自监督的信号。在每个时间步s,系统接收一部分来自分布 的连续样本及其标签。分布会随时间变化为
的连续样本及其标签。分布会随时间变化为 ,系统不知道变化何时发生。目标在于连续地学习并且更新函数
,系统不知道变化何时发生。目标在于连续地学习并且更新函数 以最小化新旧样本的预测错误,或者说持续地积累知识。
以最小化新旧样本的预测错误,或者说持续地积累知识。
系统输入为模型with参数θ,根据难样本buffer B和收到的样本更新
学习目标:
由于强non-i.i.d条件,和非常少的样本。这个系统很容易遗忘。
- MAS(Memory Aware Synapses)
传统MAS中,每个学习阶段过后,计算参数对以前学习任务的重要性。重要性
 由学习好的函数对参数变化的敏感性计算。
由学习好的函数对参数变化的敏感性计算。
然后每次更新重要参数的惩罚: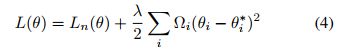
每个任务后新算的 累积。
累积。 - When to update importance weights
损失减少,意味着模型学到了新知识。损失平稳时,学习是稳定的,也是更新重要性权重的时机
当学习新的,不同的样本时,模型会被鼓励保存这些知识。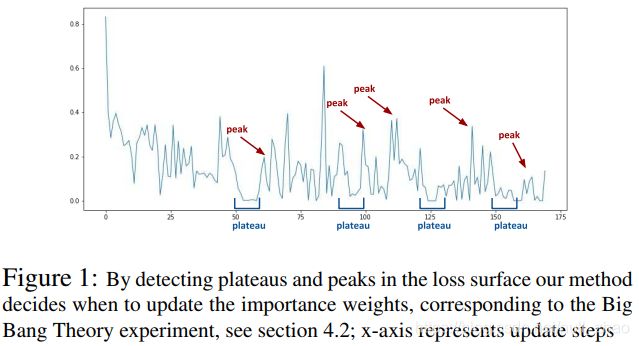
- Detecting plateaus in the loss surface
我们用滑动窗口探测平原,当mean和variance都低于阈值时,触发重要性权重更新。
当窗口损失均值高于前一个平原的窗口损失正态分布的85%时,说明检测到峰。
- A small buffer with hard samples
为稳定在线学习,设置少量难样本的缓冲区。在每次新来的样本和缓冲区样本中,留下损失最大的。
还可通过对新样本和难样本平均来得到更好的梯度。(?)
- Accumulating importance weights
单纯累加导致梯度爆炸。我们维持一个重要性权重的cumulative moving average。也可以部署一个衰减因子以在长期替换旧知识。更新重要性权重后,模型继续学习过程过程,同时惩罚为迄今为止对重要参数的更改。
最终学习目标:
4.Experiment
5.思考
依据loss波动来确定模型状态确实是很有意思的想法。