java基础问题疑点总结
文章目录
- 1、static作用
- 2、final作用
- 3、overload与override的区别
- 4、组合与继承
- 5、clone的作用
- 6、前置++与后置++
- 7、内部类
- 8、二维数组表示
- 9、接口与抽象的对比(interface与abstract)
- 10、反射机制Class
- 11、函数调用方式
- 12、重载函数overload
- 13、构造函数与static
- 14、合并两个有序链表
- 15、逻辑推理-智力题
- 16、从100亿条记录的文本文件中取出重复数最多的前10条。
- 17、判断单列表是否有环
- 18、二叉树的多种遍历算法实现
- 19、有读和写两个线程和一个队列,读线程从队列中读数据,写线程往队列中写数据。
- 20、stack和heap
- 21、TCP的流量控制和拥塞控制机制
- 22、写一个函数,返回一个字符串字符串中只出现一次的第一个字符
- 23、求一个数组中第k大的数的位置
- 24、面向对象继承、多态问题,例如多态的实现机制
- 25、值传递与引用传递。
- 26、什么是不可变量?
- 27、==与equals的区别
- 28、创建空类时,哪些成员函数是系统默认的?
- 29、有10万个IP段,这些IP段之间都不重合,随便给定一个IP,求出属于哪个IP段。
- 30、网络编程(网络编程范式、非阻塞connect)。
- 31、TCP/IP
- 32、Linux的命令、原理以及底层实现。
- 33、Linux编程,包括所有互斥的方法、多线程编程,进程间通信。
- 34、一个一维数轴上有不同的线段,求重复最长的两个线段,例如,a:1~3, B:2~7, C:2~8,最长重复是b和c。
- 35、Java入口函数的特点。
- 36、内存溢出与内存泄漏的区别
- 37、利用互斥量和条件变量设计一个消息队列,具有以下功能:1.创建消息队列(消息中所含的元素);2.消息队列中插入消息;3.取出一个消息(阻塞方式);4.取出第一消息(非阻塞方式)。注意:互斥量、条件变量和队列由系统给定。
- 38、用非递归方法完成二叉树的遍历。
- 39、如何实现类似函数指针的功能
- 40、设计模式
- 41、排列组合问题
- 42、若有序表的关键字序列为(b,c,d,e,f,g, q,r,s,t),则在二分查找关键字b的过程中,先后进行比较的关键字依次是什么?
- 43、有一个虚拟存储系统,若进程在内存中占3页(开始时内存为空),若采用先进出(FIFO)页面淘汰算法,当执行如下访问序列后,1,2,3,4,5,1,2,5,1,2,3,4,5,会发生多少缺页?
- 44、有一个顺序栈S,元素s1,s2,s3,,s4,s5,s6一次进栈,若6个元素的出栈顺序为s2,s3,s4,s6,s5,s1,则顺序栈的容量容量至少应该有多少?
- 45、[0,2,1,4,3,9,5,8,6,7]是以数组形式存储的最小堆(一种经过排序的完全二叉树,其中任一非终端节点的数据值均小于或等于其左子节点和右子节点的值),删除堆顶元素0后的结果是多少?
- 46、某页式存储管理系统中,地址寄存器长度为24位,其中号占14位,则主存的分块大小是多少字节?
- 47、内存泄漏
- 48、各种排序算法使用与比较
- 49、默认初始化问题
- 50、String字符串的存储方式
- 51、面向对象与面向过程编程的区别
- 52、异常处理
- 53、垃圾回收器
- 54、多线程同步
- 55、数据库内连接与外连接的区别
- 56、设计模式
- 57、运算符优先级
- 58、byte的原码,反码,补码
- 59、error与Exception的区别
- 60、序列化和反序列化
- 61、finalize( )的功能?
- 62、volatile的作用?
- 63、strictfp的作用?
- 64、常见的字符编码方式
- 65、Java非阻塞IO(NIO)
- 66、Java容器
- 67、SQL数据库的操作
- 68、加var和不加var的变量
- 69、script里的$符号
- 70、JSP里的页面跳转
- 71、GET与POST
- 72、window.location
- 73、T和Class以及Class的理解
- 74、Linux常用命令
- 75、设计模式
- 76、HttpServletRequest
- 77、HttpServletResponse
- 78、索引
1、static作用
类变量。static类变量,必须声明在构造方法和语句块之外;被所有对象所共享,无论一个类创建了多少个对象,类只拥有类变量的一份拷贝;静态变量在程序开始时创建,在程序结束时销毁;可以用类名或者对象名访问类变量
类方法。static类方法,不能操作实例变量,因为实例变量还没有被被加载;
static代码块。在类被初次加载时,执行顺序:父类的static代码块,子类的static代码块,父类的成员变量,父类的构造函数,子类的成员变量,子类的构造函数
对象的初始化流程如下:
- 初始化父类的静态成员
- 初始化父类的静态代码块
- 初始化子类的静态成员
- 初始化子类的静态代码块
- 初始化父类的非静态成员
- 初始化父类的非静态代码块
- 初始化父类的构造方法
- 初始化子类的非静态成员
- 初始化子类的非静态代码块
- 初始化子类的构造方法
2、final作用
final 变量,初始化时就要被赋值,之后不可修改,称为常量
final 方法,不可被重写,只能被继承
final类,不能被继承(无extends,无子类),其成员方法都默认为final方法。
3、overload与override的区别
overload是重载,用于同一个类中,方法之间不互相覆盖。方法的名字是相同的,返回参数可以相同或者不同,传递参数个数或者参数类型不同
override是重写,子类重写父类的方法时使用,以隐藏父类的方法。方法名字、、返回类型、传递参数个数或者参数类型等都要相同。重写时,访问权限不能比父类中被重写的方法的访问权限更低(public>protected>友好成员>>private)。
4、组合与继承
组合(黑盒复用),指一个类A把的某个类B的对象b作为成员变量,A的对象委托对象b来实现B内的方法,B内的方法的细节对于A来说是未知的。
继承,格式“class 子类 extends 父类”,子类能调用父类的成员变量和成员方法,子类能重写父类的非final类成员方法 。
5、clone的作用
背景:java赋值是复制对象引用,如果我们想要得到一个对象的副本,也即他们的初始状态完全一样,但以后可以改变各自的状态,而互不影响,就需要用到java中对象的复制,如原生Prototype的clone( )方法。
Object类的protected Object clone( )方法,实现了对象中各个属性的复制,实体类使用克隆的前提是:
- 实现Cloneable接口,这是一个标记接口,自身没有任何方法。
- 覆盖clone( )方法,可见性提升为public,即public Object clone( )。
clone( )方法有浅复制和深复制 - 浅复制,即被复制对象的所有值属性都含有与原来对象的相同,而所有的对象引用属性仍然指向原来的对象。
- 深复制,即在浅复制基础上,所有引用其他对象的变量也进行clone( )操作,并指向被复制过的新对象。
6、前置++与后置++
a++,先返回一个临时变量,再使内存中的a变量自增
++a,先使a=a+1,再使用a
例如:a=4
- a+=a++; //9。(1)a++返回临时变量4,内存中a的值5;(2)a指向内存中值;(3)5+=4;(4)返回9
- a += ++a; //10。(1)++a直接对内存值+1,返回内存中a的值5 (2)a指向内存中的值 (3)5+=5 (4)返回10
7、内部类
格式如下:
class 内部类的外嵌类 {
……
class 内部类 {}
}
- 外嵌类能用内部类声明对象作为外嵌类的成员变量;
- 实例内部类供外嵌类使用;
- static内部类能供外嵌类和其他类使用,static内部类不能使用外嵌类的实例成员变量,内部类也不允许声明static变量和static方法;
- 实例内部类能使用外嵌类的成员变量和成员方法;
8、二维数组表示
数组声明,实际上是在栈内存中保存了数组的名称,接下来便是要在堆内存中配置数组所需的内存。其中“元素的个数”(数组的长度)是告诉编译器数组要存放多少个元素,而“new”则是命令编译器根据括号里的长度在堆内存中开辟空间。
动态初始化:声明与创建格式int [][] arr = new int [5][6],创建了一个5个length=6的一维数组。
静态初始化:int [][] array = {{3,-9,6},{8,0,1},{11,9,8}};

9、接口与抽象的对比(interface与abstract)
接口,格式如下
interface 接口名{
public static final 常量名;
public abstract 方法名();
}
类继承接口的声明方式“class 类名 implements 接口名1,接口名2{}”,且该类必须实现所继承接口的全部方法。
抽象方法,abstract 返回类型 方法名(),抽象方法只能申明,不允许实现。
抽象类,abstract 抽象类名{},抽象类中可以有也可以没有abstract方法,而非抽象类不允许有abstract方法
10、反射机制Class
https://www.cnblogs.com/whgk/p/6122036.html
java语言的反射机制:动态地获取信息以及动态地调用对象的方法。即在运行状态中,对任意类和对象,都能够获取到该类或对象的所有属性和方法(包括私有的方法和属性)。
使用反射机制的前提:获取到该类的字节码文件对象(.class), 每一个类对应着一个字节码文件也就对应着一个Class类型的对象,也就是字节码文件对象。通过字节码文件对象,能够通过该类中的方法获取到我们想要的所有信息(方法,属性,类名,父类名,实现的所有接口等等)。。
获取字节码文件对象的三种方式:
1、Class clazz1 = Class.forName(“全限定类名”);//通过Class类中的静态方法forName,直接获取到一个类的字节码文件对象。将类装入内存,并做类的静态初始化,返回Class的对象。
2、Class clazz2 = Person.class; // JVM将使用类装载器, 将类装入内存(前提是:类还没有装入内存),不做类的初始化工作,返回Class的对象
3、Class clazz3 = person.getClass();//通过类的实例获取该类的字节码文件对象。对类进行静态初始化、非静态初始化;返回引用运行时真正所指的对象(因为:子对象的引用可能会赋给父对象的引用变量中)所属的类的Class的对象
反射机制能实现什么功能?
- 通过字节码对象和该类的无参构造函数创建对象,例如:
User user = (User)classzz1.newInstance( );
new与newInstance的区别参见https://www.cnblogs.com/yunger/p/5793669.html
2)如果该类没有无参构造函数, 就只能先调用Class类的getConstructor(String.class,int.class)方法获取一个指定参数类型的构造函数,再调用Constructor类的newInstance(“张三”,20)方法创建对象,例如:
Constructor constructor = classzz1.getConstructor(int.class, String.class);
User user = (User)constructor.newInstance(12, “张三”); - 获取全部构造函数
Constructor [] con = classzz1.getConstructors( );
for(int i = 0; i < con.length; i++){//遍历全部构造函数
Class [] parameterTypes = con[i].getParameterTypes( );
System.out.print(“第” + i + “个构造函数的参数类型”);
for(int j = 0; j < parameterTypes.length; j++){
System.out.print(parameterTypes[j].getName( ) + “,”);
}
} - 获取成员变量。Class.getField(String变量名)方法可以获取类中可见的指定字段。私有变量可以用getDeclaredField(String 变量名)方法获取,调用setAccessible(true)设置访问权限, 通过set(obj, “李四”)方法可以设置指定对象上该字段的值,通过get(obj)可以获取指定对象中该字段的值,例如:
Field field = classzz1.getDeclaredField(“id”);
field.setAccessible(true);
field.set(user, 5);
field.get(user);- 获取成员方法。获取类中带String参数的方法Class.getMethod(String 方法名, String.class) 或者 Class.getDeclaredMethod(String 方法名,String.class)。如果为私有方法,则需要设置权限setAccessible(true),通过invoke(Object obj)调用该方法,例如:
Method method = classzz1.getDeclaredMthod(“eat”, int.class);//带int参数
method. setAccessible(true);
method.invoke(user, 15);//传递15给user对象中的该方法并调用
- 获取成员方法。获取类中带String参数的方法Class.getMethod(String 方法名, String.class) 或者 Class.getDeclaredMethod(String 方法名,String.class)。如果为私有方法,则需要设置权限setAccessible(true),通过invoke(Object obj)调用该方法,例如:
- 获得该类的所有接口。Class[] getInterfaces()用于确定此对象所表示的类或接口实现的接口,返回接口的字节码文件对象的数组。
- 获取指定资源的输入流InputStream getResourceAsStream(String name)
- 动态代理的概述和实现。动态代理:一种设计模式,你自己可以做这件事,但是觉得自己做非常麻烦或者不方便,所以就叫一个另一个人(代理)来帮你做这个事情,此即动态代理。比如,买火车票叫人代买。
反射机制的应用实例 - 利用反射在泛型为int的arryaList集合中存放一个String类型的对象。原理:集合中的泛型只在编译器有效,而到了运行期,泛型则会失效。
- 利用反射,简化编写Servlet的个数。背景:每当写一个功能时,就需要写一个对应的Servlet,导致最后Servlet有很多。
11、函数调用方式
普通函数,对象.函数名(参数…)
父类函数,super.函数名(参数…)
静态成员函数,类名或对象名.函数名(参数…)
对象所属类的函数,this.函数名(参数…)
参数的传值方式
- 值传递:在运行函数时,形参和实参在不同的内存位置之中,形参将实参的值复制一份。在函数运行结束时,形参被释放,实参的值不会发生改变。
- 地址传递:在运行函数时,传给形参的是实参的地址,那么形参被修改时,实参也会发生改变。
12、重载函数overload
见问题(3)
13、构造函数与static
用new创建对象时,会先调用父类的构造函数,再调用子类的构造函数。构造函数的函数名必须与类名相同;构造函数没有返回参数,如果不小心给构造函数前面添加了返回值类型,那么这将使这个构造函数变成一个普通的方法,在运行时将产生找不到构造方法的错误;
类初始化时构造函数调用顺序:参见(1)
首先加载类,遇到extends字样会停止加载当前类,加载父类,之后再继续加载。当把一个类完全加载后,这个类的静态成员(变量和函数)将被先加载。之后进行如下流程:
(1)初始化对象的存储空间为零或null值;
(2)调用父类构造函数;
(3)按顺序分别调用类成员变量和实例成员变量的初始化表达式;
(4)调用本身构造函数
对象的初始化流程如下:
11) 初始化父类的静态成员
12) 初始化父类的静态代码块
13) 初始化子类的静态成员
14) 初始化子类的静态代码块
15) 初始化父类的非静态成员
16) 初始化父类的非静态代码块
17) 初始化父类的构造方法
18) 初始化子类的非静态成员
19) 初始化子类的非静态代码块
20) 初始化子类的构造方法
14、合并两个有序链表
15、逻辑推理-智力题
16、从100亿条记录的文本文件中取出重复数最多的前10条。
17、判断单列表是否有环
18、二叉树的多种遍历算法实现
19、有读和写两个线程和一个队列,读线程从队列中读数据,写线程往队列中写数据。
20、stack和heap
栈stack,栈内存是指程序进入一个方法时,会为这个方法单独分配一块私属存储空间,用于存储这个方法内部的局部变量,当这个方法结束时,分配给这个方法的栈会释放,这个栈中的变量也将随之释放。
堆heap,一般用于存放不放在当前方法栈中的那些数据。例如,使用 new
创建的对象都放在堆里,所以它不会随方法的结束而消失。 方法中的局部变量使用 final修饰后,放在堆中,而不是栈中。
stack的空间由操作系统自动分配和释放,heap的空间是手动申请和释放的,heap常用new关键字来分配;stack空间有限,heap的空间是很大的自由区。
若只是声明一个对象,则先在栈内存中为其分配地址空间;
若再new一下,实例化它,则在堆内存中为其分配地址。
21、TCP的流量控制和拥塞控制机制
22、写一个函数,返回一个字符串字符串中只出现一次的第一个字符
23、求一个数组中第k大的数的位置
24、面向对象继承、多态问题,例如多态的实现机制
25、值传递与引用传递。
值传递。方法调用时,实际参数把它的值传递给对应的形式参数,函数接收的是原始值的一个copy,此时内存中存在两个相等的基本类型,即实际参数和形式参数,后面方法中的操作都是对形参这个值的修改,不影响实际参数的值。
引用传递。也称为传地址。方法调用时,实际参数的引用(地址,而不是参数的值)被传递给方法中相对应的形式参数,函数接收的是原始值的内存地址;
在方法执行中,形参和实参内容相同,指向同一块内存地址,方法执行中对引用的操作将会影响到实际对象。
26、什么是不可变量?
见问题(2)
27、==与equals的区别
对于基本数据类型(boolean, byte, short, int, long, float, double, char),==用于判断两个变量的值是否相同
Object类中定义了一个equals(Object obj)方法,对于一般的引用型变量,==和equals(…)都是用于判断两个两个对象的堆内存地址是否相同;
Object类中定义了一个equals(Object obj)方法,但是在一些类库中这个方法被重写了,如String、Integer、Date,这些类的equals(…)用来比较两个对象的值是否相同,==用于判断两个两个对象的堆内存地址是否相同。
28、创建空类时,哪些成员函数是系统默认的?
C++创建空类时,默认的成员函数:构造函数、拷贝构造函数、析构函数、赋值操作符重载、取地址操作符重载、const修饰的取地址操作符重载
29、有10万个IP段,这些IP段之间都不重合,随便给定一个IP,求出属于哪个IP段。
30、网络编程(网络编程范式、非阻塞connect)。
31、TCP/IP
TCP/IP协议,Transmission Contral Protocol / Internert Protocol,是面向连接的可靠协议,能重传丢包,顺序控制次序混乱的分包,TCP通过检验、序列号、确认应答、重发控制、连接管理以及窗口控制等机制实现可靠性传输。
参考网址:https://www.cnblogs.com/steven520213/p/8005258.html
TCP建立连接要进行3次握手
1 ) 主机A向主机B 发送一个有同步序列号SYN的标志位 的数据段给主机B ,向主机B 请求建立连接。告诉主机B 两件事:我想要和你通信;你可以用这个序列号作为起始数据段来回应我。
2 ) 主机B 收到主机A的请求后,发送一个带有确认应答(ACK)和同步序列号(SYN)标志位的数据段响应主机A。告诉主机A两件事:我已经收到你的请求了;你要用序列号作为起始数据段来回应我
3 ) 主机A收到这个数据段后,再发送一个确认应答(ACK),确认已收到主机B 的数据段:“我已收到回复,我现在要开始传输实际数据了”
3次握手的特点: 没有应用层的数据;SYN这个标志位只有在TCP建立连接时才会被置1;握手完成后SYN标志位被置0。
TCP断开连接要进行4次
1 ) 当主机A完成数据传输后,将控制位FIN置1,发送FIN提出停止TCP连接的请求;
2 ) 主机B收到FIN后对其作出响应,确认这一方向上的TCP连接将关闭,将ACK置1;
3 ) 由B 端再提出反方向的关闭请求,将FIN置1,发送FIN提出停止TCP连接的请求;
4 ) 主机A对主机B的请求进行确认,将ACK置1,双方向的关闭结束。
由TCP的三次握手和四次断开可以看出,TCP使用面向连接的通信方式,大大提高了数据通信的可靠性,使发送数据端和接收端在数据正式传输前就有了交互,为数据正式传输打下了可靠的基础。
TCP/IP的五层协议
应用层
传输控制层
网络层
数据链路层
物理层
32、Linux的命令、原理以及底层实现。
33、Linux编程,包括所有互斥的方法、多线程编程,进程间通信。
34、一个一维数轴上有不同的线段,求重复最长的两个线段,例如,a:1~3, B:2~7, C:2~8,最长重复是b和c。
35、Java入口函数的特点。
main 方法可以省略 public ? static ? 返回值可以是 int ? 形参可以省略吗? 可以在main 中调用 main 方法吗?
Java规定了main( )方法必须是公共的,以便于外部程序对主方法的访问,因为程序都是从main( )方法起始的,并且main()方法也必须是静态的。
- mian()为public的原因。因为在运行程序时,jvm要调用main方法,而JVM与main方法所在的包是不同的,所以jvm要调用main方法时,main方法就必须声明为public;否则jvm就不能找到和调用main方法。
- 用static的原因。 因为用static修饰的方法或变量是在编译时运行或分配永久空间的,main用static修饰后,程序就能自动找到程序的main的入口。如果不用static,JVM就只能创造一个实例去调用main方法,但是jvm并不知道如何去创造一个实例,而要创造一个实例时,必须要在main方法里头使用new这个关键字,但此时jvm无法调用main方法,所以就无法创造一个实例去调用main方法,所以main方法必须声明为static。
- 用void的原因。第一,main方法根本就不需要返回值。第二,如果返回了值,也不能看到,此时jvm也不知道拿这个返回值来干什么,所以就用void。
- String[]是字符串数组,arguments被拿来储存命令行的参数,虽然在main里我们可能不会使用到这个参数,但是它是必须的。参数args的主要作用是为程序使用者在命令行状态下与程序交互提供了一种手段。此外在其他类中直接使用main()函数,并传递参数也是可行的。
36、内存溢出与内存泄漏的区别
最典型的内存泄漏:https://blog.csdn.net/m0_38110132/article/details/81986334

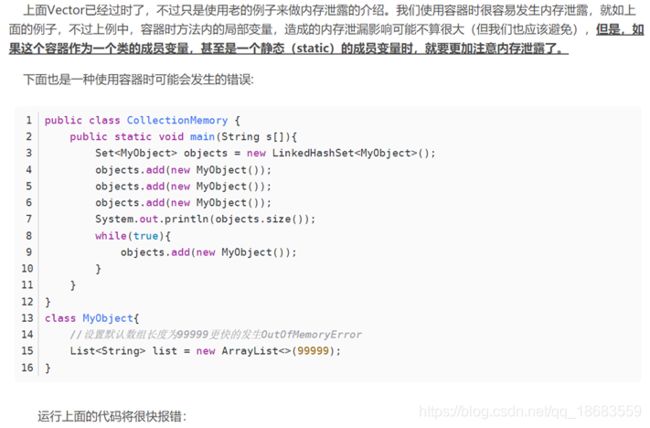
内存溢出out of memory,即程序在申请内存时,没有足够的栈/堆/永久保存区内存空间供其使用。上溢:栈满时再做进栈产生的空间溢出。下溢:栈空时再做退栈产生的空间溢出。分类:永久保存区溢出、堆溢出、栈溢出
内存泄漏memory leak,是指无用对象(不再使用的对象)持续占有内存或无用对象的内存得不到及时释放。内存泄露堆积严重时,迟早会耗光内存导致内存溢出。内存泄漏是堆中的存在但无用可达的对象,GC无法回收。分类:常发性内存泄漏、偶发性内存泄漏、一次性内存泄漏、隐式内存泄漏。
Java的一个重要特性就是通过垃圾收集器(GC)自动管理内存的回收,而不需要程序员自己来释放内存。理论上Java中所有不会再被利用的对象所占用的内存,都可以被GC回收,但是Java也存在内存泄露
gc清理时的引用计数方式:当引用连接至新对象时,引用计数+1;当某个引用离开作用域或被设置为null时,引用计数-1,GC发现这个计数为0时,就回收其占用的内存。这个开销会在引用程序的整个生命周期发生,并且不能处理循环引用的情况。所以这种方式只是用来说明GC的工作方式,而不会被任何一种Java虚拟机应用。
多数GC采用一种自适应的清理方式(加上其他附加的用于提升速度的技术),主要依据是找出任何“活”的对象,然后采用“自适应的、分代的、停止-复制、标记-清理”式的垃圾回收器。具体不介绍太多,这不是本文重点。
内存泄漏例子:对象都是有生命周期的,有的长,有的短,如果长生命周期的对象持有短生命周期的引用,就很可能会出现内存泄露。我们举一个简单的例子:
public class Simple {
Object object;
public void method1(){
object = new Object();
//…其他代码
}
}
这里的object实例,其实我们期望它只作用于method1()方法中,且其他地方不会再用到它,但是,当method1()方法执行完成后,object对象所分配的内存不会马上被认为是可以被释放的对象,只有在Simple类创建的对象被释放后才会被释放,严格的说,这就是一种内存泄露。解决方法就是将object作为method1()方法中的局部变量。当然,如果一定要这么写,可以改为这样:
public class Simple {
Object object;
public void method1(){
object = new Object();
//…其他代码
object = null;
}
}
这样,之前“new Object()”分配的内存,就可以被GC回收。
• 在堆中的分配的内存,在没有将其释放掉的时候,就将所有能访问这块内存的方式都删掉(如指针重新赋值),这是针对c++等语言的,Java中的GC会帮我们处理这种情况,所以我们无需关心。
• 在内存对象明明已经不需要的时候,还仍然保留着这块内存和它的访问方式(引用),这是所有语言都有可能会出现的内存泄漏方式。编程时如果不小心,我们很容易发生这种情况,如果不太严重,可能就只是短暂的内存泄露。
内存泄露的根本原因?长生命周期的对象持有短生命周期对象的引用就很可能发生内存泄露,尽管短生命周期对象已经不再需要,但是因为长生命周期对象持有它的引用而导致不能被回收,这就是java中内存泄露的发生场景。
引起内存溢出的原因有很多种,列举几种常见的:
1.内存中加载的数据量过于庞大,比如一次从数据库取出过多数据;
2.集合类中有对对象的引用,使用完后未清空,使得JVM不能回收;
3.代码中存在死循环或循环产生过多重复的对象实体;
4.使用的第三方软件中的BUG;
5.启动参数内存值设定的过小
内存溢出的解决方案:
第一步,修改JVM启动参数,直接增加内存。(-Xms,-Xmx参数一定不要忘记加。)
第二步,检查错误日志,查看“OutOfMemory”错误前是否有其它异常或错误。
第三步,对代码进行走查和分析,找出可能发生内存溢出的位置。
第四步,使用内存查看工具动态查看内存使用情况
重点排查以下几点:
1.检查对数据库查询中,是否有一次获得全部数据的查询。一般来说,如果一次取十万条记录到内存,就可能引起内存溢出。这个问题比较隐蔽,在上线前,数据库中数据较少,不容易出问题,上线后,数据库中数据多了,一次查询就有可能引起内存溢出。因此对于数据库查询尽量采用分页的方式查询。
2.检查代码中是否有死循环或递归调用。
3.检查是否有大循环重复产生新对象实体。
4.检查List、MAP等集合对象是否有使用完后,未清除的问题。List、MAP等集合对象会始终存有对对象的引用,使得这些对象不能被GC回收。
37、利用互斥量和条件变量设计一个消息队列,具有以下功能:1.创建消息队列(消息中所含的元素);2.消息队列中插入消息;3.取出一个消息(阻塞方式);4.取出第一消息(非阻塞方式)。注意:互斥量、条件变量和队列由系统给定。
38、用非递归方法完成二叉树的遍历。
39、如何实现类似函数指针的功能
用接口实现函数指针功能https://blog.csdn.net/u012441545/article/details/55805995
函数指针,即函数回调。
Java中用接口实现函数指针具体方法----接口回调:先定义一个接口,并在接口中声明要调用的方法,然后用一个类继承该接口并实现方法,最后把这个类的对象作为参数传递给调用程序,调用程序通过这个参数调用指定函数,从而实现回调函数功能。
为什么要接口回调?符合策略设计模式。
例如:
public class FunctionPointerTest {
public static void main(String... args){
Player[] players = new Player[5];
for(int i = 0;i<players.length;i++){
players[i] = new Player();
}
pressButton(players,new StopButton());
pressButton(players,new StartButton());
}
public static void pressButton(Player[] players,PlayerButton button){
for(int i=0;i<players.length;i++){
button.buttonPressed(players[i]); //通过button参数调用类所实现的接口中的方法
}
}
}
class Player {
public void start(){
System.out.println("start");
}
public void stop(){
System.out.println("stop");
}
}
//在接口中定义按钮按键方法
interface PlayerButton {
public void buttonPressed(Player player);
}
//在类中实现接口中的方法
class StopButton implements PlayerButton{
@Override
public void buttonPressed(Player player) {
player.stop();
}
}
class StartButton implements PlayerButton{
//在类中实现接口中的方法
@Override
public void buttonPressed(Player player) {
player.start();
}
}
40、设计模式
41、排列组合问题
全排列:A(n,n)=n! 如,n个人都排队。第一个位置可以选n个,第二位置可以选n-1个,以此类推得: A(n,n)=n*(n-1)…321= n!
部分排列:A(n,m)=n!/(n-m)! 如,n个人选m个出来排队,第一个位置可以选n个,…,最后一个可以选n-m+1个,以此类推得:A(n,m)=n*(n-1)…(n-m+1)=n!/(n-m)!。
组合:C(n,m)=n!/(m!(n-m)!) n个人选m个人出来。因为不在乎顺序,所以按排列算的话,每个组合被选到之后还要排列,是被算了m!遍的。即C(n,m)m!=A(n,m)
例子,我们从n个不同的数里选出m个数组成一个排列,第一个位子上的数有n种取法,第二个位子上的有n-1种,第三个位子上有n-2种。。。共有n(n-1)…*(n-m+1)种
然而,我们对于顺序没有要求,假设取出了m个数,第一个位子上有m种放法,第二个位子上有m-1种。。。所以我们刚才得到的组合公式中除了一个m!
理解排列组合,参考:https://blog.csdn.net/qq_36808030/article/details/75045129?utm_source=blogxgwz0
-
从n个中选出m个并排序:
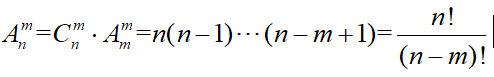
-
从n个中选出m个不需要要排序:
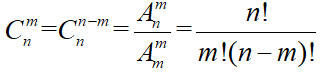
几种常用的解题方法和策略:特殊元素(位置)的“优先安排法”、 总体淘汰法、合理分类与准确分步、相邻问题用捆绑法、不相邻问题用“插空法”、 顺序固定用“除法”、 分排问题用“直排法”、 逐个试验法、构造模型“隔板法”、 排除法、逐步探索法、一一对应法。
参考https://www.sohu.com/a/167868817_740020
42、若有序表的关键字序列为(b,c,d,e,f,g, q,r,s,t),则在二分查找关键字b的过程中,先后进行比较的关键字依次是什么?
43、有一个虚拟存储系统,若进程在内存中占3页(开始时内存为空),若采用先进出(FIFO)页面淘汰算法,当执行如下访问序列后,1,2,3,4,5,1,2,5,1,2,3,4,5,会发生多少缺页?
44、有一个顺序栈S,元素s1,s2,s3,s4,s5,s6一次进栈,若6个元素的出栈顺序为s2,s3,s4,s6,s5,s1,则顺序栈的容量容量至少应该有多少?
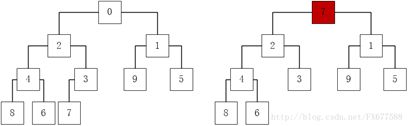
45、[0,2,1,4,3,9,5,8,6,7]是以数组形式存储的最小堆(一种经过排序的完全二叉树,其中任一非终端节点的数据值均小于或等于其左子节点和右子节点的值),删除堆顶元素0后的结果是多少?
过程如下(从左至右):
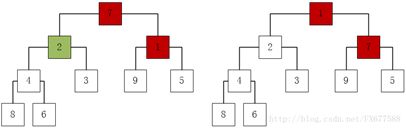
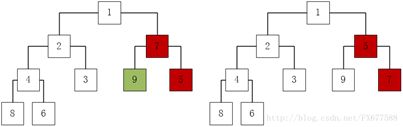
46、某页式存储管理系统中,地址寄存器长度为24位,其中号占14位,则主存的分块大小是多少字节?
47、内存泄漏
见题目(36)
48、各种排序算法使用与比较
49、默认初始化问题
对象的初始化流程如下:
21) 初始化父类的静态成员
22) 初始化父类的静态代码块
23) 初始化子类的静态成员
24) 初始化子类的静态代码块
25) 初始化父类的非静态成员
26) 初始化父类的非静态代码块
27) 初始化父类的构造方法
28) 初始化子类的非静态成员
29) 初始化子类的非静态代码块
30) 初始化子类的构造方法
成员初始化。当创建一个类时,类的每个基本类型数据成员保证都有一个初始值,如int,char等数据类型的初值为0,boolean的初值为false。当在类中定义一个对象引用时,如果不进行初始化,此引用会得到初值null。
变量的存储位置
- 静态成员存储在永久代/永久区中;
- 非静态局部变量存储在栈中;
- 方法中的 final局部变量存储在堆中;
- new创建的引用型变量存储在堆中;
- new创建的String型变量会在堆中生成字符串对象,再把堆中的字符串对象的地址赋值给String引用型变量。
50、String字符串的存储方式
String类,是final变量。String对象一旦被创建就是固定不变的了,对String对象的任何改变都不影响到原对象,相关的任何修改操作都会生成新的对象。
字符串常量池。jdk1.6下字符串常量池是在永久区中,是与堆完全独立的两个空间。
- 用“String a = “Hello””创建字符串常量时,JVM会首先检查字符串常量池,如果常量池中有该字符串对象“Hello”,就直接返回常量池中的实例引用给栈中的a变量。如果常量池中不存在,就会实例化该字符串并且将其放到常量池中。由于String字符串的不可变性我们可以十分肯定常量池中一定不存在两个相同的字符串。
- 用“String str3=new String(“aaa”); String str4=new String(“aaa”);” 创建字符串常量时,JVM首先在字符串池中查找有没有"aaa"这个字符串对象,如果没有,则首先在字符串池中创建一个"aaa"字符串对象,再在堆中创建一个"aaa"字符串对象,然后将堆中这个"aaa"字符串对象的地址返回赋给栈中的引用型变量str3,这样str3指向了堆中创建的这个"aaa"字符串对象。如果有,则不在池中再去创建"aaa"这个对象了,直接在堆中创建一个"aaa"字符串对象,然后将堆中的这个"aaa"对象的地址返回赋给栈中的引用型变量str3,这样,str3就指向了堆中创建的这个"aaa"字符串对象。当执行String str4=new String(“aaa”)时, 直接在堆中用new创建一个"aaa"字符串对象,也即是说引用str3和str4指向的是两个不同的对象,因此System.out.println(str3 == str4)输出:false。
单独使用"“引号创建的字符串都是常量,编译期就已经确定存储到String Pool中;使用new String(”")创建的对象会存储到heap中,是运行期新创建的;
String、StringBuffer、StringBuilder的区别 - 可变与不可变:String是不可变字符串对象,StringBuilder和StringBuffer是可变字符串对象(其内部的字符数组长度可变)。
- 是否多线程安全:String中的对象是不可变的,也就可以理解为常量,显然线程安全。StringBuffer 与 StringBuilder 中的方法和功能完全是等价的,只是StringBuffer 中的方法大都采用了synchronized 关键字修饰,因此是线程安全的。而 StringBuilder 没有synchronized修饰,是非线程安全的。
- String、StringBuilder、StringBuffer三者的执行效率:StringBuilder > StringBuffer > String 当然这个是相对的,不一定在所有情况下都是这样。比如String str = “hello”+ "world"的效率就比 StringBuilder st = new StringBuilder().append(“hello”).append(“world”)要高。
- 当String类型对字符串修改时,其实际过程是首先创建一个StringBuffer,其次调用StringBuffer的append()方法,最后调用StringBuffer的toString( )方法把结果返回。
因此,当字符串相加操作或者改动较少时,使用 String str="hello"这种形式;当字符串相加操作较多时,使用StringBuilder;如果采用了多线程,则使用StringBuffer。
51、面向对象与面向过程编程的区别
面向过程思想强调的是过程(动作),“打开冰箱–存储大象–关上冰箱”。面向过程就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了。
面向对象思想强调的是对象(实体),“冰箱打开–冰箱存储大象–冰箱关上” 。面向对象是把构成问题的事务分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描叙某个事物在整个解决问题的步骤中的行为。
面向过程优点:性能比面向对象高,因为类调用时需要实例化,开销比较大,比较消耗资源,比如单片机、嵌入式开发、Linux/Unix等一般采用面向过程开发,性能是最重要的因素。
面向过程缺点:没有面向对象易维护、易复用、易扩展
面向对象优点:易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统更加灵活、更加易于维护
面向对象缺点:性能比面向过程低
52、异常处理
Exception,容易发生异常的程序放在try-catch-finally块中处理,格式:“try{}catch(异常参数){}finally{}”。Java允许throw一个Exception的子类实例表示异常发生。Java允许继承Excetion自定义一个异常类,并在函数中声明要产生的异常“public void 函数名(…) throws 异常类名{…}”。一般在try{}中打开资源或者建立连接,要记得在finally{}中释放资源,以免内存泄漏。
Java异常的顶层类是Throwable类,子类有Error类和Exception类
53、垃圾回收器
GC (Garbage Collection),是一种守护线程Daemon Thread。GC回收什么对象?当一个对象通过一系列根对象(比如:静态属性引用的常量)都不可达时就会被回收。简而言之,当一个对象的所有引用都为null。循环依赖不算做引用,如果对象A有一个指向对象B的引用,对象B也有一个指向对象A的引用,除此之外,它们没有其他引用,那么对象A和对象B都、需要被回收。
年轻代,所有新生成的对象首先都是放在年轻代的。年轻代的目标就是尽可能快速的收集掉那些生命周期短的对象。年轻代分三个区。一个Eden区,两个 Survivor区(一般而言)。大部分对象在Eden区中生成。当Eden区满时,还存活的对象将被复制到Survivor区(两个中的一个),当这个 Survivor区满时,此区的存活对象将被复制到另外一个Survivor区,当这个Survivor去也满了的时候,从第一个Survivor区复制过来的并且此时还存活的对象,将被复制“年老区(Tenured)”
年老代,在年轻代中经历了N次垃圾回收后仍然存活的对象,就会被放到年老代中。因此,可以认为年老代中存放的都是一些生命周期较长的对象。
持久代,用于存放静态文件,如今Java类、方法等。持久代对垃圾回收没有显著影响,但是有些应用可能动态生成或者调用一些class,例如Hibernate 等,在这种时候需要设置一个比较大的持久代空间来存放这些运行过程中新增的类。持久代大小通过-XX:MaxPermSize=进行设置。
参考网址 https://www.cnblogs.com/williamjie/p/9497906.html
GC算法分类
(1)标记清除算法。分为标记和清除两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。该算法的缺点是效率不高并且会产生不连续的内存碎片。
(2)复制算法。把内存空间划为两个区域,每次只使用其中一个区域。垃圾回收时,遍历当前使用区域,把正在使用中的对象复制到另外一个区域中。次算法每次只处理正在使用中的对象,因此复制成本比较小,同时复制过去以后还能进行相应的内存整理,不会出现“碎片”问题。优点:实现简单,运行高效。缺点:会浪费一定的内存。一般新生代采用这种算法。
(3)标记整理算法。标记阶段与标记清除算法一样。但后续并不是直接对可回收的对象进行清理,而是让所有存活对象都想一端移动,然后清理。优点是不会造成内存碎片。
GC调优
做GC的调优很大程度上依赖于对系统的分析,系统拥有怎样的对象以及他们的平均生命周期。如果一个应用大多是短生命周期的对象,就要确保Eden区足够大,这样可以减少Minor GC的次数。可以通过-XX:NewRatio来控制新生代和老年代的比例,比如-XX:NewRatio=3代表新生代和老年代的比例为1:3。注意,扩大新生代的大小会减少老年代的大小,这会导致Major GC执行的更频繁,而Major GC可能会造成用户线程的停顿从而降低系统吞吐量。
Full GC和并发垃圾回收
并发垃圾回收器的内存回收过程是与用户线程一起并发执行的。并发垃圾回收器可以在用户线程运行的情况下完成大部分的回收工作,所以应用停顿时间很短。但由于并发垃圾回收时用户线程还在运行,所以会有新的垃圾不断产生。作为担保,如果在老年代内存都被占用之前,并发垃圾回收器还没结束工作,那么应用会暂停,在所有用户线程停止的情况下完成回收。即Full GC。
54、多线程同步
多线程同步的适用场景:当一个线程操作某个变量时,不希望其他线程来操作该变量时使用同步机制。
synchronized同步机制,格式“public synchronized void 方法名(…){ }”。当某线程操作该方法时,相当于给该方法上了同步锁,不允许其他线程操作该方法,直到该线程执行完该同步方法。但是,可以用wait( )使该线程让出CPU使用权并且释放同步锁,此时其他的线程是可以使用同步方法的。
synchronized是Java中的关键字,是一种同步锁。它修饰的对象有以下几种:
- 修饰一个代码块,称为同步语句块,其作用范围是{}内的代码,作用对象是调用这个代码块的对象;
- 修饰一个方法,称为同步方法,其作用范围是整个方法,作用对象是调用这个方法的对象;
- 修改一个静态的方法,其作用范围是整个静态方法,作用对象是这个类的所有对象;
- 修改一个类,其作用范围是synchronized后面括号括起来的部分,作用的对象是这个类的所有对象。
死锁。例如,创建两个字符串a和b,再创建两个线程A和B,让每个线程都用synchronized锁住字符串(A先锁a,再去锁b;B先锁b,再锁a),如果A锁住a,B锁住b;那么,A就没办法锁住b(因为b被B锁住了),B也没办法锁住a(因为a被A锁住了),这时就陷入了死锁。
死锁的后果。JVM解决死锁问题方面并没有数据库这么强大,当一组Java线程发生死锁时,这两个线程就永远不能再使用了,并且由于两个线程分别持有了两个锁,那么这两段同步代码/代码块也无法再运行了----除非终止并重启应用。
避免死锁的方法。 - 每次至多只获得一个锁。当然,此情况在多线程下并不现实。
- 调整申请锁的范围
- 设计时考虑清楚锁的顺序,尽量减少嵌在的加锁交互数量。
- 既然死锁的产生是两个线程无限等待对方持有的锁,那么只要等待时间有个上限不就好了。当然synchronized不具备这个功能,但是我们可以使用Lock类中的tryLock方法去尝试获取锁,这个方法可以指定一个超时时限,在等待超过该时限之后变回返回一个失败信息
55、数据库内连接与外连接的区别
56、设计模式
57、运算符优先级
口诀:单目乘除为关系,逻辑三目后赋值。
单目:单目运算符+(正)–(负) ++ – 等
乘除:算数单目运算符* / % + -
为:位移单目运算符<< >>
关系:关系单目运算符> < >= <= == !=
逻辑:逻辑单目运算符&^ | && ||
三目:三目单目运算符A > B ? X : Y
后:无意义,仅仅为了凑字数
赋值:赋值=

58、byte的原码,反码,补码
byte是一个字节保存的,有8个位,即8个0、1。8位的第一个位是符号位,也就是说0000 0001是数字1的原码 。1000 0001代表的就是-1的原码。
一个数为正,则它的原码、反码、补码相同
一个数为负,符号位为1,其余各位是对原码取反,然后整个数加1,计算机中的负数是用补码表示的。
负数从补码求原码的过程与从原码求补码过程相同,先取反,再+1
- 1的原码为 1000 0001
- 1的反码为 1111 1110
- 1的补码为 1111 1111 (即:反码+ 1)
0的原码为 0000 0000
0的反码为 1111 1111(正零和负零的反码相同)
0的补码为 10000 0000(反码+1,去掉超出的1,零的补码=原码)
-128的原码 1000 0000
-128的反码 1111 1111
-128的补码 (1)1000 0000(去掉超出的1,补码=原码)
59、error与Exception的区别
Error类和Exception类都继承自Throwable类。
Exception:
- 可以是可被控制(checked) 或不可控制的(unchecked)。
- 表示一个由程序员导致的错误。
- 应该在应用程序级被处理。
Error:
- 总是不可控制的(unchecked)。
- 经常用来用于表示系统错误或低层资源的错误。
- 如何可能的话,应该在系统级被捕捉。
好的编程习惯
- 尽量不要捕获类似 Exception 这样的通用异常,而是应该捕获特定异常,这是因为在日常的开发和合作中,我们读代码的机会往往超过写代码。
- 不要生吞(swallow)异常。即,千万不要假设某段代码可能不会发生,或者感觉忽略异常是无所谓的。
- 尽量不要一个大的 try 包住整段的代码。
60、序列化和反序列化
概念:
- 对象的序列化:把对象转换为字节序列的过程。
- 对象的反序列化:把字节序列恢复为对象的过程。
适用场景:在对对象流进行读写和通信操作时引发的问题。
对象的序列化的两种用途: - 把对象的字节序列永久地保存到硬盘上,通常存在文件或者数据库中。在很多应用中,需要对某些对象进行序列化,让它们离开内存空间,入住物理硬盘以便长期保存。比如最常见的是Web服务器中的Session对象,当有 10万用户并发访问,就有可能出现10万个Session对象,内存可能吃不消,于是Web容器就会把一些seesion先序列化到硬盘中,等要用了,再把保存在硬盘中的对象还原到内存中。
- 在网络上传送对象的字节序列。当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把这个Java对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为Java对象。
JDK类库中的序列化API - java.io.ObjectOutputStream代表对象输出流(用于发送),它的writeObject(Object obj)方法可对参数指定的obj对象进行序列化,把得到的字节序列写到一个目标输出流中。
- java.io.ObjectInputStream代表对象输入流(用于接收),它的readObject()方法从一个源输入流中读取字节序列,再把它们反序列化为一个对象,并将其返回。
前提:只有实现了Serializable和Externalizable接口的类的对象才能被序列化。Externalizable接口继承自 Serializable接口,实现Externalizable接口的类完全由自身来控制序列化的行为,而仅实现Serializable接口的类可以采用默认的序列化方式 。
static和transient类型的数据不能被序列化。
如果一个类能被序列化,那么子类也能被序列化。
对象序列化包括如下步骤:
1)创建一个对象输出流,用于包装其他类型的目标输出流,如文件输出流;
2)通过对象输出流的writeObject(Object obj)方法对对象进行序列化。
例如:ObjectOutputStream oo = new ObjectOutputStream(new FileOutputStream(
new File(“E:/Person.txt”)));
oo.writeObject(person);
System.out.println(“Person对象序列化成功!”);
oo.close();
对象反序列化的步骤如下:
1) 创建一个对象输入流,它可以包装其他类型的源输入流,如文件输入流;
2)通过对象输入流的readObject()方法读取对象。
例如: ObjectInputStream ois = new ObjectInputStream(new FileInputStream(
new File(“E:/Person.txt”)));
Person person = (Person) ois.readObject();
System.out.println(“Person对象反序列化成功!”);
ois.close();
注意,尽量为待序列化或者反序列化的对象设置序列化ID标号值,比如
private static final long serialVersionUID = -5182532647273106745L;
这是因为serialVersionUID的取值是Java运行时环境根据类的内部细节自动生成的。如果对类的源代码作了修改,再重新编译,新生成的类文件的serialVersionUID的取值有可能也会发生变化。为了提高serialVersionUID的独立性和确定性,强烈建议在一个可序列化类中显示的定义serialVersionUID,为它赋予明确的值。
显式地定义serialVersionUID有两种用途:
- 在某些场合,希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有相同的serialVersionUID;
- 在某些场合,不希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有不同的serialVersionUID。
61、finalize( )的功能?
finalize是Object类的方法,一旦垃圾回收器准备好释放对象占用的空间,会首先调用被回收对象的finalize( )方法,并且在下一次GC动作发生时,才会真正回收对象占用的内存。可以重写此方法来实现对其他资源的回收,例如关闭文件等。
62、volatile的作用?
背景:当读取一个没有被volatile修饰的变量时,线程会先把变量读取到一个缓存中,当以后再读取变量值时,直接从缓存中取值,当变量值变化时,缓存值也变化。
而被volatile修饰的变量,系统每次使用它时都是直接从其内存中提取,不会利用缓存,所以所有线程在同一时刻所看到该变量的值都是相同的。
缺点:volatile不能保证操作的原子性,使用时会阻止编译器对代码的优化,降低执行效率,无法替代sychronized同步。
63、strictfp的作用?
背景:JVM执行浮点数运算时,在不同平台上的计算结果不精确,可能导致意想不到的错误。
strictfp,即strict float point,指精确浮点,用于确保浮点数运算的精确性。
strictfp可以修饰类、接口、方法,声明范围内的float变量都是被strictfp修饰,编译器和JVM会完全按照IEEE二进制浮点数算数标准(IEEE754)来执行。
64、常见的字符编码方式
常见的编码格式有ASCII、ISO-8859-1、GB2312、GBK、GB18030、UNICODE、UTF-8、UTF-16等,其中GB2312、GBK、GB18030、UTF-8、UTF-16都可以用来表示中文。
ASCII编码,American Standard Code for Information Interchange,用来表示英文,它使用1个字节表示,其中第一位规定为0,其他7位存储数据,一共可以表示128个字符。
ISO-8859-1,一种拓展的ASCII编码,用于表示更多的欧洲文字,用8个位存储数据,一共可以表示256个字符
GBK/GB2312/GB18030,用于表示汉字。GBK/GB2312表示简体中文,GB18030表示繁体中文。
Unicode编码,包含世界上所有的字符,是一个字符集。
UTF-8,是Unicode字符的实现方式之一,它使用1-4个字符表示一个符号,根据不同的符号而变化字节长度。
UTF-16,是UNICODE的具体实现,16即16位,定义了UNICODE字符在计算机中的存储方式,使用两个字节来表示任何字符,这样使得操作字符串非常高效,这也是java把UTF-16作为字符在内存中存储的格式的重要原因。
String.getBytes(String decode)方法会根据指定的decode编码返回某字符串在该编码下的byte数组表示,例如:
- byte[] b_gbk = “深”.getBytes(“GBK”); //b_gbk的长度为2
- byte[] b_utf8 = “深”.getBytes(“UTF-8”); //b_utf8的长度为3
- byte[] b_iso88591 = “深”.getBytes(“ISO8859-1”);// b_iso88591的长度为1
- byte[] b_unicode = “深”.getBytes(“unicode”); //b_unicode长度为4
通过new String(byte[], decode)的方式来还原这个“深”字时,这个new String(byte[], decode)实际是使用decode指定的编码来将byte[]解析成字符串
- String s_gbk = new String(b_gbk,“GBK”);
- String s_utf8 = new String(b_utf8,“UTF-8”);
- String s_iso88591 = new String(b_iso88591,“ISO8859-1”);
- String s_unicode = new String(b_unicode, “unicode”);
有时,为了让中文字符适应某些特殊要求(如http header头要求其内容必须为iso8859-1编码),可能会通过将中文字符按照字节方式来编码的情况,如
String s_iso88591 = new String(“深”.getBytes(“UTF-8”),“ISO8859-1”)。再将这些字符传递到目的地后,目的地程序再通过相反的方式String s_utf8 = new String(s_iso88591.getBytes(“ISO8859-1”),“UTF-8”)来得到正确的中文汉字“深”。这样就既保证了遵守协议规定、也支持中文。
65、Java非阻塞IO(NIO)
非阻塞IO,Nonblocking IO(NIO),参考网址:
https://blog.csdn.net/u011381576/article/details/79876754#
背景1:如果客户端还没对服务器发起连接请求,那么accpt()就会阻塞(阻塞指的是暂停一个线程的执行以等待某个条件的发生)。如果连接成功,数据还没准备好时,对read的调用也会阻塞。当要处理多个连接时,就需要采用多线程方式,每个线程拥有自己的栈空间,而且由于阻塞会导致大量线程进行上下切换,导致运行效率低下。为解决此问题,引入了NIO。
NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取。而不是保持线程阻塞,所以该线程可以继续做其他的事情,直至数据变得可以读取。 非阻塞写也是如此:一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。 线程通常将NIO的空闲时间用于在其它通道上执行IO操作,所以NIO的一个单独线程可以管理多个输入和输出通道(channel)。
NIO主要的三大核心部分:Channel(通道),Buffer(缓冲区), Selector。
在处理大量并发请求时,使用NIO比使用Socket效率高很多。
66、Java容器
(其中,淡绿色的是接口,红色的是常用的类。)
参考https://www.cnblogs.com/LipeiNet/p/5888513.html
Java容器类类库,用于保存对象,分为2个概念。
- Collection,一个独立元素的序列,这些元素都服从一条或多条规则。其中List必须按照插入的顺序保存元素、Set不能有重复的元素、Queue按照排队规则来确定对象的产生顺序(通常也是和插入顺序相同)
- Map,一组成对的值键对对象,允许用键来查找值。ArrayList允许我们用数字来查找值,它是将数字和对象联系在一起。而Map允许我们使用一个对象来查找某个对象,它也被称为关联数组。或者叫做字典。
List,有ArrayList、ListedList。 - ArrayList其实就是采用的是数组(默认是长度为10的数组)。所有ArrayList在读取的时候是具有和数组一样的效率,它的时间复杂度为1。优点在于随机访问元素快,但是在中间插入和移除比较慢。
- ListedList采用的是链式存储。链式存储就会定一个节点Node。包括三部分前驱节点、后继节点以及data值。所以存储的时候它的物理地址不一定是连续的。
Set,一个集合,特点是不可以有重复的对象,所以Set最常用的就是测试归属性,很容易的询问出某个对象是否存在Set中。Set是具有和Collection完全一样的接口,没有额外的功能,只是表现的行为不同。 - HashSet,查询速度比较快,但是存储的元素是随机的并没有排序。
- TreeSet,将元素存储在红-黑树结构中,所以存储的结果是有顺序的(如果想要自己存储的集合有顺序,就选择TreeSet)。
Queue,Queue是队列,队列是典型的先进先出的容器,就是从容器的一端放入元素,从另一端取出,并且元素放入容器的顺序和取出的顺序是相同的。LinkedList提供了对Queue的实现,LinkedList向上转型为Queue。
Map,Map在实际开发中使用非常广,特别是HashMap。通过创建一个对象保存一个对象中某些元素的值是件麻烦的事,这时我们就可以用上map了,HashMap采用散列函数所以查询效率比较高。如果需要一个有序的Map,我们就可以考虑使用TreeMap。这里主要介绍一下HashMap的方法,注意HashMap的键可以是null,而且键值不可以重复,如果重复了以后就会覆盖第一个键值。
Iterator和Foreach。
foreach语法主要作用于数组,但是它也可以应用于所有的Collection对象。Collection之所以能够使用foreach是由于继承了Iterator这个接口。foreach循环最终是转换成 for (Iterator it=iterator;iterators.hasNext();)只不过jdk帮我们隐藏我们无法查看。
Collections和Arrays。2个常用的函数Collections.addAll和Arrays.asList
67、SQL数据库的操作
SQL操作包括:定义与建立(create,drop,alter),查询(select)、插入(insert)、删除(delete)、修改(update),数据控制(grant,revoke)
创建table或view(表和视图的操作相同)。
Create 源.table 表名(
字段1 字段1数据类型, 字段2 字段2数据类型, ……);
查询。
select 源.table1.*, 源.table2.字段1, 源.table2.字段2
from 源.table1, 源.table2
where (源.table1.字段1 = 源.table2.字段1) and (源.table2.字段1 > 1)
group by 源.table2.字段1
having 源.table2.字段1 < 4
order by 源.table2.字段1 ASC
外连接,即把悬浮元组也保留在结果中。
select 表1., select表2.
from 表1 left outer join 表2 on (表1.学号 = 表2.学号)
SQL→视图→基本表→存储文件。视图是虚表,数据库中只存放视图的定义而不存放视图对应的数据,这些数据仍存放在导出视图的基本表中。
68、加var和不加var的变量
- 使用var声明变量,在方法内部是局部变量,在方法外部是全局变量;
- 没有使用var声明的变量,在方法内部或外部都是全局变量,但如果是在方法内部声明,在方法外部使用之前需要先调用方法,告知系统声明了全局变量后方可在方法外部使用。
- 在函数作用域内,var定义的变量是局部变量,不加var定义的就成了全局变量。
- 在function内部, 加var的是局部变量, 不加var的则是全局变量;
- 在function外部,不管有没有使用var声明变量,都是全局变量,在function外部,var关键字一般可以省略,但是为了书写规范和维护方便以及可读性好,我个人不建议省略var关键字!
69、script里的$符号
-
$( )方法,是在DOM中频繁使用的 document.getElementById() 方法的简写,就像这个DOM方法一样,这个方法返回参数传入的id的那个元素。可以传入多个id作为参数然后 $() 返回一个带有所有要求的元素的一个 Array 对象。
例1:var divs = KaTeX parse error: Expected 'EOF', got '#' at position 3: ('#̲myDiv, #myOther…(“input[name=‘username’]”) -
$F()函数,能用于返回任何表单输入控件的值,比如text box,drop-down list。
例如:alert( $F(’#userName’) ); -
$A()函数,能把它接收到的单个参数转换成一个Array对象。
-
( f u n c t i o n ( ) , 是 (function( ){ },是 (function(),是(document).ready(function(){ … })的简写,相当于window.onload = function(){ },用来在DOM加载完成之后执行一系列预先定义好的函数。
-
(function(){}),表示一个匿名函数。function(arg){…}定义了一个参数为arg的匿名函数,然后使用(function(arg){…})(param)来调用这个匿名函数。其中param是传入这个匿名函数的参数。
-
, 是 e l 表 达 式 , 它 会 从 p a g e , r e q u e s t , s e s s i o n , a p p l i c a t i o n 中 取 值 。 比 如 : { },是el表达式,它会从page,request,session,application中取值。比如: ,是el表达式,它会从page,request,session,application中取值。比如:{name},就是从以上4个对象中去找名为name的值。如果是在转发到这个页面之前,在request中setAttribute(“name”,“测试”),那么${name} 就会被“测试”这个信息给替换。
补充:DOM?
即 Document Object Model,它允许脚本(js)控制Web页面、窗口和文档。
DOM的妙处在于:它能够在所有浏览器上提供一种一致的方式,通过代码访问HTML的结构和内容。
1、在浏览器加载一个页面时,浏览器会解析HTML,并创建文档的一个内部模型,其中包含HTML标记的所有元素,自上而下解析,遇到JavaScript浏览器会检查它的正确性,然后执行代码。
2、JavaScript继续执行,使用DOM检查页面、完成修改、从页面接受事件,或者要求浏览器从Web服务器获取其它数据。
注:document是一个反映HTML的对象,通过调用document的方法改变DOM的状态,也就是改变HTML页面
3、JavaScript修改了DOM时,浏览器会随着动态更新页面。
DOM就是一张映射表啦,记录着一堆用代码操控document时的规章制度,直白点说,就是js操作html时的API
70、JSP里的页面跳转
- 里的跳转,location.href默认使用的是GET提交方式如下
location.href=“login_if.jsp?username=”+username+"&password="+password+"";
2) html中的页面跳转,标签默认使用的也是GET提交方式,如下
澳洲进口牛奶
71、GET与POST
Get是向服务器发索取数据的一种请求(比如,从数据库中查询),而Post是向服务器提交数据的一种请求(比如,修改数据库),在FORM(表单)中,Method默认为"GET",实质上,GET和POST只是发送机制不同,并不是一个取一个发!
POST的安全性要比GET的安全性高,因为通过GET提交数据,用户名和密码将明文出现在URL上。具体的说:(1)登录页面有可能被浏览器缓存,(2)其他人查看浏览器的历史纪录,那么别人就可以拿到你的账号和密码,此外,使用GET提交数据还可能会造成Cross-site request forgery攻击。
1). GET请求的数据会附在URL之后(就是把数据放置在HTTP协议头中),以?分割URL和传输数据,参数之间以&相连,如:login.action?name=hyddd& verify=%E4%BD%A0%E5%A5%BD。如果数据是英文字母/数字,原样发送。如果是空格,转换为+,如果是中文/其他字符,则直接把字符串用BASE64加密,得出如:%E4%BD%A0%E5%A5%BD,其中%XX中的XX为该符号以16进制表示的ASCII。
2) POST把提交的数据则放置在是HTTP包的包体中。
客户端使用get请求时,服务器端使用Request.QueryString( )来获取参数;
客户端使用post请求时,服务器端使用Request.Form( )来获取参数。
(1)若符合下列任一情况,则用POST方法:
- 请求的结果有持续性的副作用,例如,数据库内添加新的数据行。
- 若使用GET方法,则表单上收集的数据可能让URL过长。
- 要传送的数据不是采用7位的ASCII编码。
(2)若符合下列任一情况,则用GET方法:
- 请求结果无持续性的副作用。
- 收集的数据及HTML表单内的输入字段名称的总长不超过1024个字符。
- 请求是为了查找资源,HTML表单数据仅用来帮助搜索。
72、window.location
Javascript对当前页的操作:
- 获取当前页的URLwindow.location.href
- 拿端口window.location.port
- 拿协议window.location.protocol,
- 拿url问号后面的部分window.location.search
(当然也可以利用它们来改相应的值。)
例如:var url=window.location.href;
alert(“protocol:”+window.location.protocol+",port:"+window.location.port);
73、T和Class以及Class的理解
Class s,s既是对象也是类,作为对象它是Class类型的,但作为类我们无法确认s是什么类,有可能是A,或是B。所以通过s.newInstance()获取的对象是Object类型的;但是有时我们已经可以确定s对应的是什么类了,我们不想让s.newInstance()返回Object类型的对象,而是返回具体的类型,比如:我知道s对应的类就是Student,那么s.newInstance()返回的是Student类型的对象,而不是Object类型的。但是默认情况下返回是Object类型的,那么如何实现例子中的预期效果呢,很简单通过传递泛型参数来指定,例如:Class s,那么T就是s对应的类,所以s.newInstance()返回的是T类型的对象,至于泛型T对应的是哪个类,由我们自己指定,如果传的是A,那么返回的就是A类对象,如果传的是B,那么返回的是B类对象。
T bean ;
Class bean;
Class bean;
单独的T 代表一个类型, Class和Class代表这个类型所对应的类
Class在实例化的时候,T要替换成具体类
Class它是个通配泛型,?可以代表任何类型
JDK中,普通的Class.newInstance()方法的定义返回Object,要将该返回类型强制转换为另一种类型;
但是使用泛型的Class,Class.newInstance()方法具有一个特定的返回类型;
74、Linux常用命令
常用:
- pwd 获取当前路径
- cd 跳转到目录
- su -u 切换到管理员
- ls ls 列举目录
文件操作命令: - touch + 文件名 文件不存在就创建这个文件;文件存在就刷新它的最后修改时间
- tail -f file 实时显示文件尾部(很重要的命令)
- rm -rf 删除
- vi 修改,编辑一个文本
文件夹 - mkdir 创建
- rm -rf 删除
- mv 目标目录/文件 目的地路径 将目标文件/目录剪切到目的地路径
- cp -r 目标目录 目的地路径 将目标目录拷贝一份到目的地路径中
权限信息 - 对于文件: r:可读, w:可写, x:可执行
- 对于目录:r:是否可浏览, w:是否可以创建或删除目,x:是否可以进入
重启:reboot
立即关机(并发送广播):
sudo shutdown -h now : 立即关机(需要输入管理员密码),其中sudo选项 :为当前操作赋予管理员( root )权限
在屏幕上打印hello: echo “hello”
75、设计模式
学习设计模式的推荐网站https://blog.csdn.net/carson_ho/article/details/54910518
模板方法设计模式(Template Method)
一个很好的例子https://www.cnblogs.com/stonefeng/p/5743673.html
#设置项目服务器端口
#连接数据库相关配置:url, username, password, driver
#?useUnicode=true&characterEncoding=utf8&useSSL=false
#扫描到类/mapper.xml
#mybatis.typeAliasesPackage=com.example.demo1.model
#mybatis.mapper-locations=classpath*:mapper/**/*.xml
76、HttpServletRequest
HttpServletRequest对象代表客户端的请求,当客户端通过HTTP协议访问服务器时,HTTP请求头中的所有信息都封装在这个对象中,通过这个对象提供的方法,可以获得客户端请求的所有信息。
参考网址:https://www.cnblogs.com/xdp-gacl/p/3798347.html
1、获得客户机信息
getRequestURL方法返回客户端发出请求时的完整URL。
getRequestURI方法返回请求行中的资源名部分。
getQueryString 方法返回请求行中的参数部分。
getPathInfo方法返回请求URL中的额外路径信息。额外路径信息是请求URL中的位于Servlet的路径之后和查询参数之前的内容,它以“/”开头。
getRemoteAddr方法返回发出请求的客户机的IP地址。
getRemoteHost方法返回发出请求的客户机的完整主机名。
getRemotePort方法返回客户机所使用的网络端口号。
getLocalAddr方法返回WEB服务器的IP地址。
getLocalName方法返回WEB服务器的主机名。
例如:
public class RequestDemo01 extends HttpServlet {
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
/**
* 1.获得客户机信息
*/
String requestUrl = request.getRequestURL().toString();//得到请求的URL地址
String requestUri = request.getRequestURI();//得到请求的资源
String queryString = request.getQueryString();//得到请求的URL地址中附带的参数
String remoteAddr = request.getRemoteAddr();//得到来访者的IP地址
String remoteHost = request.getRemoteHost();
int remotePort = request.getRemotePort();
String remoteUser = request.getRemoteUser();
String method = request.getMethod();//得到请求URL地址时使用的方法
String pathInfo = request.getPathInfo();
String localAddr = request.getLocalAddr();//获取WEB服务器的IP地址
String localName = request.getLocalName();//获取WEB服务器的主机名
response.setCharacterEncoding("UTF-8");//设置将字符以"UTF-8"编码输出到客户端浏览器
//通过设置响应头控制浏览器以UTF-8的编码显示数据,如果不加这句话,那么浏览器显示的将是乱码
response.setHeader("content-type", "text/html;charset=UTF-8");
PrintWriter out = response.getWriter();
out.write("获取到的客户机信息如下:");
2、获得客户机请求头
getHeader(string name)方法:String
getHeaders(String name)方法:Enumeration
getHeaderNames()方法
3、获得客户机请求参数(客户端提交的数据)
getParameter(String)方法(常用)
getParameterValues(String name)方法(常用)
getParameterNames()方法(不常用)
getParameterMap()方法(编写框架时常用)
77、HttpServletResponse
https://www.cnblogs.com/xdp-gacl/p/3789624.html
78、索引
1、索引底层数据结构B+树详解
2、索引为什么不用红黑树与Hash
3、如何建立高性能索引
4、BAT面试关于索引都问些什么