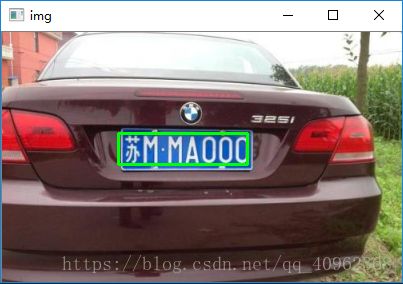
python+OpenCV图像处理(十二)车牌定位中对图像的形态学组合操作处理
车牌定位中对图像的形态学组合操作处理
所谓的车牌定位,其中最关键的部分就是对图片的处理,参数的设置,并使之拥有泛化能力。
首先传入图片,在进行大规模的图片处理时,因为无法确定图片的尺寸,所以需要将原始图片进行等比例的缩放。
orgimg = cv2.imread('chepai3.jpg')
# 压缩图像
img = cv2.resize(orgimg, (400, int(400 * img.shape[0] / img.shape[1])))对图像的操作是在灰度图上进行的,所以将图像转为灰度图
# 灰度图
grayimg = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cv2.imshow('grayimg', grayimg)
对灰度图图像像素进行拉伸,使图片的像素值拉伸到整个像素空间,提高图像像素的对比度
# 像素拉伸
def stretch(img):
max_ = float(img.max())
min_ = float(img.min())
for i in range(img.shape[0]):
for j in range(img.shape[1]):
img[i, j] = (255 / (max_ - min_)) * img[i, j] - (255 * min_) / (max_ - min_)
return img
stretchedimg = stretch(grayimg)
cv2.imshow('stretchedimg', stretchedimg)
开运算是指图像先进行腐蚀再膨胀的运算,所以对图像进行开运算可以去除图像中的一些噪声
# 先定义一个元素结构
r = 16
h = w = r * 2 + 1
kernel = np.zeros((h, w), dtype=np.uint8)
cv2.circle(kernel, (r, r), r, 1, -1)
# 开运算
openingimg = cv2.morphologyEx(stretchedimg, cv2.MORPH_OPEN, kernel)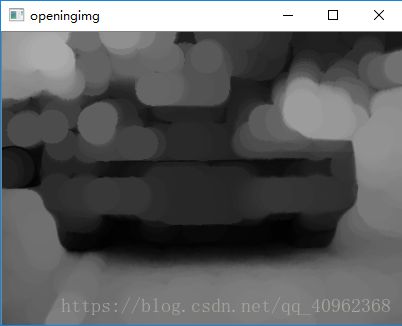
然后,获取两个图像之间的差分图,OpenCV中提供了一个函数cv2.absdiff(),这个函数可以把两幅图的差的绝对值输出到另一幅图上面来,利用这种办法可以去除图片中的大面积噪声。
# 获取差分图
strtimg = cv2.absdiff(stretchedimg, openingimg)边缘检测的目的是标识数字图像中亮度变化明显的点,所以,利用边缘检测可提高对图像有效信息的感知能力
# 在对图像进行边缘检测之前,,先对图像进行二值化
binary_img = dobinaryzation(strtimg)
# 使用Canny函数做边缘检测
cannyimg = cv2.Canny(binary_img, binary_img.shape[0], binary_img.shape[1])
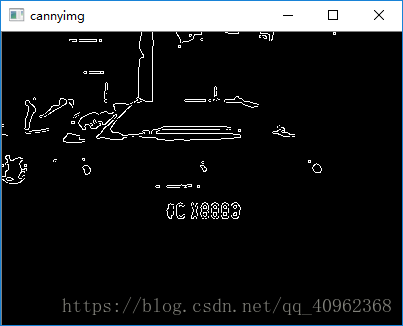
最后,再经过一系列的形态学组合操作,使图像能够满足定位的需要
# 进行闭运算
kernel = np.ones((5, 19), np.uint8)
closing_img = cv2.morphologyEx(cannyimg, cv2.MORPH_CLOSE, kernel)
# 进行开运算
opening_img = cv2.morphologyEx(closing_img, cv2.MORPH_OPEN, kernel)
# 再次进行开运算
kernel = np.ones((11, 5), np.uint8)
opening_img = cv2.morphologyEx(opening_img, cv2.MORPH_OPEN, kernel)
# 膨胀
kernel_2 = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
kernel_dilated = cv2.dilate(opening_img, kernel_2)
形态学组合操作的目的是去除图像中小区域噪声,保留大块的区域,从而定位车牌。
最终通过轮廓检测确定图像处理后的区域,并找出轮廓的左上点和右下点,来计算它的面积和长宽比,最后根据面积和图像背景颜色,来判断出车牌的区域,并画出矩形框。
这是最终的处理结果: