嵌入式之路_2_没有嵌入式编程基础知识,谈何杀敌呢!
1 交叉编译器选项说明
白话文:
学过C语言的同学,那一定玩过Window下的Visual studio对吧!
build、编译按钮一点啥事也不用操心,系统自动完成。
其实这是Visual studio已经将各种编译工具的使用封装好了。
我们是要学习嵌入式,这类集成的工具让我们每个人都成了编程用户,而不是创造者。
那么以后我们需要直接使用编译工具,来进行嵌入式的开发。
首先需要掌握一些编译选项!!!!
PC上的编译工具链为gcc、ld、objcopy、objdump等,它们编译出来的程序在x86平台上运行。
那么要编译出能在ARM平台上运行的程序,必须使用交叉编译工具arm-linux-gcc、arm-linux-ld等。
编译全过程演示
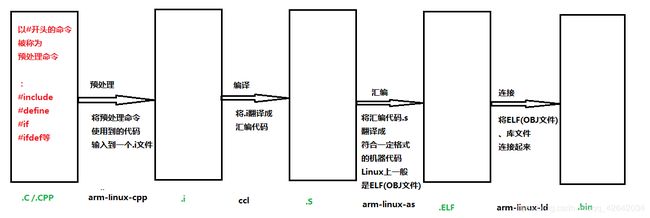
文件后缀名与编译器的默认动作对应表
| 后缀名 | 语言种类 | 后期操作 |
|---|---|---|
| .c | C源程序 | 预处理、编译、汇编 |
| .C | C++源程序 | 预处理、编译、汇编 |
| .cc | C++源程序 | 预处理、编译、汇编 |
| .cxx | C++源程序 | 预处理、编译、汇编 |
| .m | Objective-C源程序 | 预处理、编译、汇编 |
| .i | 预处理后的C文件 | 编译、汇编 |
| .ii | 预处理后的C++文件 | 编译、汇编 |
| .s | 汇编语言源程序 | 汇编 |
| .S | 汇编语言源程序 | 预处理、汇编 |
| .h | 预处理器文件 | 通常不出现在命令行上 |
其他的后缀名被传递给连接器(linker)
.o:目标文件(Object file,OBJ文件)
.a:归档库文件(Archive file)
在编译过程中,除非使用了“-c”,“-S”,“-E”选项,否则最后的步骤总是连接。
在连接阶段中,所有对应于源程序的.o文件、“-l”选项指定的库文件、无法识别的文件名(也就是外来的.o .a文件)按命令行的顺序传给连接器。
1.1 arm-linux-gcc选项
总体选项
- -c
预处理、编译和汇编源文件,但是不做连接,编译器根据源文件生成的OBJ文件。 - -S
编译后即停止,不进行汇编。 - -E
预处理后即停止,不进行编译 - -o file
指定输出文件为file。 - -v
显示制作GCC工具自身时的配置命令;同时显示编译器驱动程序、预处理器、编译器的版本号
警告选项
-Wall 选项基本打开了所有需要注意的警告信息,比如没有指定类型的声明、在声明前就使用的函数、局部变量除了声明就没有再使用等
调试选项
-g 这个你不需要知道太多,知道它产生调试信息就行了
优化选项
这个你暂时也不需要了解,在不会写规范程序前提下,不要使用,防止系统自动优化
连接器选项
下面的选项用于连接OBJ文件,输出可执行文件或库文件
-
-object-file-name
如果某些文件没有特别明确的后缀,GCC默认它们是OBJ文件或库文件。
如果GCC执行连接操作时,这些OBJ文件将成为连接器的输入文件 -
-llibrary
连接名为library的库文件
连接器在标准搜索目录中寻找这个库文件,库文件的真正名字是“liblibrary.a”。搜索目录除了一些系统标准目录外,还包括用户以“-L”选项指定的路径。一般来说用这个方法找到的文件是库文件——即有OBJ文件组成的归档文件(archive file)。
连接器处理归档文件的方法是:
扫描归档文件,寻找某些成员,这些成员的符号目前已被引用,不过还没有被定义。
但是,如果连接器找到普通的OBJ文件,而不是库文件,就把这个OBJ文件按平常的方式连接进来。指定“-l”选项和指定文件名的区别是,“-l”选项用“lib”和“.a”把library包裹起来,而且搜索一些目录
即使不明显地使用“-llibrary”选项,一些默认的库也被连接进去,可以使用“-v”选项看到这点 -
-nostartfiles
不连接系统标准启动文件,而标准库文件仍然正常使用 -
-notstdlib
不连接系统标准启动文件和标准库文件,只把指定的文件传递给连接器。
这个选项常用于编译内核、BootLoader等程序,它们不需要启动文件、标准库文件 -
-static
在支持动态连接(dynamic linking)的系统上阻止连接共享库 -
-shared
生成一个共享OBJ文件,它可以和其他OBJ文件连接产生可执行文件。只有部分系统支持该选项。 -
Xlinker option
把选项option传递给连接器。可以用来传递系统特定的连接选项,GCC无法识别这些选项。如果需要传递携带参数的选项,必须使用两次“Xlinker”,一次传递选项,另一次传递其参数。例如,如果传递“assert definitions”,要写成“-Xlinker -assert -Xlinker definitions” -
-Wl option
把选项option传递给连接器。如果option中含有逗号,就在逗号处分割成多个选项。连接器通常是通过gcc、arm-linux-gcc等命令简介启动的,要想它传入参数时,参数前面加上“-Wl” -
-u symbol
使连接器认为取消了symbol的符号定义,从而连接库模块以取得定义。可以使用多个“-u”选项,各自跟上不同的符号,使得连接器调入附加的库模块
目录选项
下列选项指定搜索路径,用于查找头文件、库文件或编译器的某些成员
-
-Idir
在头文件的搜索路径列表中添加dir目录
头文件的搜索方法为:如果以“#include <>”包含文件,则只在标准库目录开始搜索(包括使用-Idir选项定义的目录);如果以“#include”包含文件,则先从用户的工作目录开始搜索,再搜索标准库目录 -
-I-
任何在“-I-”前面用“-I”选项指定的搜索路径只适用于“#include “file””这种情况,它们不能用来搜索“#include ”包含的头文件。
如果用“-I”选项指定的搜索路径位于“-I-”选项后面,就可以在这些搜索路径中搜索所有的"#include"指令 -
-Ldir
在“-I”选项的搜索路径列表中添加dir目录
1.2 arm-linux-ld选项
- 1 直接指定代码段、数据段、bss段的起始位置
arm-linux-ld -Ttext 0x00000000 -g led.o -o led_elf
- 2 使用连接脚本设置地址
arm-linux-ld -Ttimer.lds -o timer_elf $^
它使用连接脚本timer.lds来设置可执行文件timer_elf的地址信息,timer.lds文件内容如下:
SECTIONS{
. = 0x30000000;
.text : {*(.text)}
.rodata ALIGN(4) : {*(.rodata)}
.data ALIGN(4) : {*(.data)}
.bss ALIGN(4) : {*(.bss) *(COMMON)}
}
解析timer.lds文件之前,先讲解连接脚本的格式。
连接脚本的命令是SECTIONS命令,它描述了输出文件的“映射图”:输出文件中各段、各文件怎么放置。
一个SECTONS命令内部可以包含一个或多个段,段(Section)是连接脚本的基本单元,它表示输入文件中的某部分怎么放置
完整的连接脚本格式如下,它的核心部分段(Sectoin):
SECTIONS{
...
secname start ALIGN(align) (NOLOAD) : AT(ldadr)
{contents} > region :phdr = fill
...
}
secname和content是必须的,前者用来命名这个段,后面用来确定代码中的什么部分放在这个段中。
start是这个段重定位地址,也称为运行地址。如果代码中有位置相关的指令,程序在运行时,这个段必须放在这个地址上。
ALIGN(align):虽然start指定了运行地址,但是仍可以使用BLOCK(align)来指定对齐的要求——这个对齐的地址才是真正的运行地址。
(NOLOAD):用来告诉加载器,在运行时不用加载这个段。显然,这个选项只有在有操作系统的情况下才有意义。
AT(ldaddr):指定这个段在编译出来的映像文件中的地址——加载地址(load address)。
如果不使用这个选项,则加载地址等于运行地址。通过这个选项,可以控制各段分别保存输出文件中的不同位置,便于把文件保存到单板上:A段放到A处,B段放到B处,运行前再把A、B段分别读出来组装成一个完整的执行程序
后面的3个选项>region :phdr =fill忽略!!!用不到
现在,是不是就可以明白前面的连接脚本timer.lds的含义了:
(1) 第2行表示设置“当前运行地址”为0x30000000。
(2) 第3行定义了一个名为“.text”的段,它的内容为“*(.text)”,表示所有的输入文件的代码段。这些代码段被集合在一起,起始运行地址为0x30000000。
(3) 第4行定义了一个名为“.rodata”的段,在输出文件timer_elf中,紧挨着“.text”段存放。
其中的“ALIGN(4)”表示起始运行地址为4字节对齐。假设前面“.text”段的地址范围是0x30000000 ~ 0x300003f1,则“.rodata”段的地址是4字节对齐后的0x300003f4。
(4) 第5、6行的含义与第4行类似
1.3 arm-linux-objcopy选项
arm-linux-objcopy被用来复制一个目标文件的内容到另一个文件中,可以使用不同于源文件的格式来输出目的文件,即可以进行格式转换。
-
input-file、outfile
参数intput-file和outfile分别表示输入目标文件(源目标文件)和输出目标文件(目的目标文件)。如果在命令行中没有明确的指定outfile,那么arm-linux-objcopy将创建一个临时文件来存放目标结果,然后使用input-file的名字来重命名这个临时文件(这个时候原来的input-file将被覆盖) -
-I bfdname或–input-target=bfdname
用来指明源文件的格式,bfdname是BFD库中描述的标准格式名。如果不指明源文件格式,arm-linux-objcopy会自己去分析源文件的格式,然后去和BFD中描述的各种格式比较,从而得知源文件的目标格式名 -
-O bfdname 或–output-target=bfdname
使用指定的格式来输出文件,bfdname是BFD库中描述的标准格式名 -
-F bfdname或–target=bfdname
同时指明源文件、目的文件的格式。将源目标文件中的内容复制到目的目标文件的过程中,只进行复制不做格式转换,源目标文件是什么格式,目的目标文件就是什么格式 -
-R sectionname 或–remove-section=sectionname
从输出文件中删掉所有名为sectionname的段, -
-S 或–strip-all
不从源文件中复制重定位信息和符号信息到目标文件中去 -
-g
不从源文件中复制调试符号到目标文件中去
在编译bootloader、内核时,常用arm-linux-objcopy命令将ELF格式的生成结果转换为二进制文件,比如:
arm-linux-objcopy -O binary -S elf_file bin_file
1.4 arm-linux-objdump选项
arm-linux-objdump用于显示二进制文件信息,常用来查看反汇编代码
-
-b bfdname 或–target==bfdname
指定目标码格式。这个不是必须的,arm-linux-objdump能自动识别许多格式。可以使用“arm-linux-objdump -i”命令查看支持的目标码格式列表 -
–disassemble或-d
反汇编可执行段(executable section) -
–disassemble-all或-D
与“-d”类似,反汇编所有段 -
-EB或-EL或–endian={big|little}
指定字节序 -
–file-headers或-f
显示文件的整体头部摘要信息。 -
–section-headers、–headers或-h
显示目标文件各个段的头部摘要信息 -
–info 或-i
显示支持的目标文件格式和CPU架构 -
–section=name或-j name
仅显示指定section的信息 -
–architecture=machine或-m machine
指定反汇编目标文件时使用的架构,当待反汇编文件本身没有描述架构信息的时候,这个选项很有用
在调试程序时,常用arm-linux-objdump命令来得到汇编代码。
(1)将ELF格式的文件转换为反汇编文件
arm-linux-objdump -D elf_file > dis_file
(2) 将二进制文件转换成反汇编文件
arm-linux-objdump -D -b binary -m arm bin_file > dis_file
1.5 汇编代码、机器码和存储器的关系以及数据的表示
即使使用C/C+或者其他高级语言编程,最后也会被编译工具转换为汇编代码,并最终作为机器码存储在内存、硬盘或者其他存储器上。在调试程序时,经常需要阅读它的汇编代码,以下面的汇编代码为列:
4bc : e3a0244e mov r2,#1308622848;0x4e000000
4c0 : e3a0344e mov r3,#1308622848;0x4e000000
4c4 : e5933000 ldr r3,[r3]
4bc、4c0、4c4是这些代码在的运行地址,就是说运行前,这些指令必须位于内存中的这些地址上;
e3a0244e、e3a0344e、e5933000是机器码。
运行地址、机器码都以十六进制表示。
CPU用到的、内存中保存的都是机器码
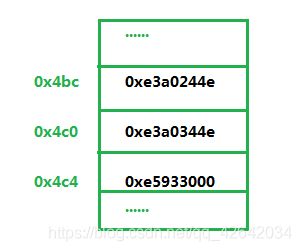
“mov r2,#1308622848、mov r3,#1308622848、 ldr r3,[r3]”是这几个机器码的汇编代码——所谓汇编代码仅仅是为了方便读、写而引入的,机器码和汇编代码之间也仅仅是简单的转换关系
参考CPU的数据手册可知,ARM的数据处理指令格式为:

以机器码0xe3a0344e为列:
(1) [31:28] = 0b1110,表示这条指令无条件执行
(2) [25] = 0b1,表示Operand2是一个立即数
(3) [24:21] = 0b1101,表示这是MOV指令,即Rd := Op2
(4) [20] = 0b0,表示这条指令执行时不影响状态位
(5) [15:12] = 0b0010,表示Rd就是r2
(6) [11:0] = 0x44e,这是一个立即数
立即数占据机器码的低12位表示:最低8位的值称为immed_8,高4位称为rotate_imm。
立即数的数值计算方法为:
=immed_8循环右移(2*rotate_imm)
对于“[11:0]=0x44e”,其中immed_8=0x4e、rotate_imm=0x4,所以此立即数等于0x4e000000。
综上所述,机器码0xe3a0244e的汇编代码为:
mov r2,#0x4e000000
即
mov r2,#1308622848
2 Makefile的简单详解
(学会以下几条就够了,后面有时间会给大家写一篇Makefile专题)
在Linux中使用make命令来编译程序,特别是大工程;而make命令所执行的动作依赖于Makefile文件。最简单的Makefile文件如下:
hello : hello.c
gcc -o hello hello.c
clean :
rm -f hello
2.1 Makefile规则
目标(target) ... : 依赖(prerequiries)...
命令(command)
目标(target)通常是要生成的文件名称,可以是可执行文件或OBJ文件,也可以是一个执行的动作的名称,诸如:“clean”
依赖是用来产生目标的原材料(比如源文件),一个目标经常有几个依赖
命令时生成目标时执行的动作,一个规则可以包含有几条命令,每个命令占一行
通常,如果一个依赖发生了变化,就需要规则调用命令以更新或创建目标。
但是,并非所有的目标都有依赖,例如,目标“clean”的作用是清除文件,它没有依赖
规则一般是用于解释怎样和何时重建目标。make首先调用命令处理依赖,进而才能创建或更新目标。当然,一个规则也可以是用于解释怎样和何时执行一个动作,即打印提示信息。
一个Makefile文件包含规则以外的其他文本,但一个简单的Makefile文件仅仅需要包含规则。
2.2 Makefile文件里的赋值方法
immediate = deferred
immediate ?= deferred
immediate := immediate
immediate += deferred or immediate
define immediate
deferred
endef
在GNU make中对变量的赋值有两种方式:
延时变量、立即变量
区别在于他们的定义方式和扩展时的方式不同,前者在这个变量使用时才扩展开,意即当真正使用时才确定;后者在定义时它的值就已经确定了。
使用“=”、“?=”定义或使用define指令定义的变量是延时变量
使用“:=”定义的变量是立即变量。
需要注意的是“?=”仅仅在变量还没有定义的情况下有效,即“?=”用来定义第一次出现的延时变量
对于附加操作符“+=”,右边变量如果在前面使用(:=)定义为立即变量则它也是立即变量,否则均为延时变量
2.3 Makefile常用函数
函数调用的格式如下:
$(function arguments)
这里“function”是函数名,“arguments”是该函数的参数。
参数和函数名之间用空格或Tab隔开,如果有多个参数,它们之间用逗号隔开。
内核的Makefile中用到大量的函数,现在介绍一些常用的。
字符串替换和分析函数
- $(subst from,to,text)
在文本“text”使用“to”替换每一处“from”
比如:
$(subst ee,EE,feet on the street)
结果为:“fEEt on the strEEt”
- $(patsubst pattern,replacement,text)
寻找“text”中符合格式“pattern”的字,用“replacement”替换它们。“pattern”和“replacement”中可以使用通配符。
比如:
$(patsubst %.c,%.o,x.c.c bar.c)
结果为:“x.c.o bar.o”
- $(strip sting)
去掉前导和结尾空格,并将中间的多个空格压缩为单个空格
比如:
$(strip a b c)
结果为:“a b c”
- $(findstring find,in)
在字符串“in”中搜寻“find”,如果找到,则返回值是是“find”,否则返回值是空
比如:
$(findstring a,a b c)
$(findstring a,b c)
将分别产生值“a”和“ ”。
- $(filter pattern…,text)
返回在“text”中由空格隔开且匹配格式“pattern…”的字,去除不符合格式“pattern…”的字。
比如:
$(filter %.c %.s,foo.c bar.c baz.s ugh.h)
结果为 “foo.c bar.c baz.s”
- $(filter-out pattern…,text)
返回在“text”中由空格隔开且不匹配格式“pattern”的字,去除符合格式“pattern…”的字。它是函数filter的反函数。
比如
$(filter-out %.c %.s,foo.c bar.c baz.s ugh.h)
结果为“ugh.h”
- $(sort list)
将“list”中的字按照字母顺序排序,并去掉重复的字。输出由单个空格隔开的字的列表。
比如:
$(sort foo bar lose
返回值是:bar foo lose
文件名函数
- $(dir names…)
抽取“names…”中每一个文件名的路径部分,文件名的路径部分包括从文件名的首字符到最后一个斜杠(含斜杆)之前的一切字符。
比如:
$(dir src/foo.c hacks)
结果为:“src/ ./”
- $(notdir names…)
抽取“names…”中每一个文件名中除路径部分外一切字符(真正的文件名)
比如:
$(notdir src/foo.c hacks)
结果为:“foo.c hacks”
- $(suffix names…)
抽取“names…”中每一个文件名的后缀
比如:
$(suffix src/foo.c src-1.0/bar.c hacks)
结果为:“.c .c”
- $(basename names…)
抽取“names…”中每一个文件名除后缀外一切字符
比如:
$(basename src/foo.c src-1.0/bar hacks)
结果为:“src/foo src-1.0/bar hacks”
- $(addsuffix suffix,names…)
参数“names…”是一系列的文件名,文件名之间用空格隔开;suffix是一个后缀名。将suffix的值附加在每一个独立文件名的后面,完成后将文件名串联起来,它们之间用单个空格隔开
比如:
$(addsuffix .c,foo bar)
结果为:“foo.c bar.c”
- $(addprefix,names…)
参数“names”是一系列的文件名,文件名之间用空格隔开;prefix是一个前缀名。将prefix的值附加在每一个独立文件名的前面,完成后将文件名串联起来,它们之间的关系用单个空格隔开
比如:
$(addprefix src/,foo bar)
结果为:“src/foo src/bar”
- $(wildcard pattern)
参数“pattern”是一个以文件名格式,包含有通配符(通配符和shell中的用法一样)。
函数wildcard的结果是一列和格式匹配且真实存在的文件名称,文件名之间用一个空格隔开
比如若当前目录下有文件1.c 2.c 1.h 2.h,则:
c_src := $(wildcard *.c)
结果为:“1.c 2.c”
其他函数
- $(foreach var,list,text)
前两个参数,“var”和“list”将首先扩展,最后一个参数“text”此时不扩展;接着,“list”扩展所得的每个字都赋给“var”变量;然后“text”引用该变量进行扩展,因此“text”每次的扩展都不相同
函数的结果是由空格隔开的“text”在“list”,就是说:“text”多次扩展的字串联起来,字与字之间有空格隔开,如此就产生了函数foreach的返回值
下面是一个简单的例子,将变量“files”的值设置为“dirs”中的所有目录下的所有文件的列表:
dirs := a b c d
files := $(foreach dir,$(dirs),$(wildcard $(dir)/*))
这里“text”是“$(wildcard $(dir)/*)”,它的扩展过程如下:
(1) 第一个赋给变量dir的值是“a”,扩展结果为“$(wildcard a/*)”;
(2) 第二个赋给变量dir的值是“b”,扩展结果为“$(wildcard b/*)”;
(3) 第二个赋给变量dir的值是“c”,扩展结果为“$(wildcard c/*)”;
(4) 如此继续扩展
这个例子和下面的例子有共同的结果
file := $(wildcard a/* b/* c/* d/*)
- $(if condition,then-part[,else-part])
首先把第一个参数“condition”的前导空格、结尾空格去掉,然后扩展。
如果扩展为非空字符串,则条件“condition”为真;如果扩展为空字符串,则条件“condition”为假。
如果条件“condition”为真,那么计算第二个参数“then-part”的值,并将该值作为整个函数if的值。
如果条件“condition”为假,并且第三个参数存在,则计算第三个参数“else-part”的值,并将该值作为整个函数if的值;如果第三个值不存在,函数if将什么也不计算,返回空值。 - $(origin variable)
变量“variable”是一个查询变量的名称,不是对该变量的引用。所以不能采用“$”和圆括号的格式书写该变量,当然,如果需要使用非常量的文件名,可以在文件名中使用变量变量引用
函数origin的结果是一个字符串,该字符串变量的定义如下
undefined :变量“variable”从来没有定义
default :变量“variable”是默认定义
environment:变量“variable”作为环境变量定义,选项“-e”没有打开
environment override:变量“variable”在Makefile中定义,选项“-e”已打开
file :变量“variable”在Makefile中定义
command line:变量“variable”在命令行中定义
override :变量“variable”在Makefile中用override指令定义
automatic :变量“variable”是自动变量
- $(shell command arguments)
函数shell是make与外部环境的通信工具。函数shell的执行结果和在控制台上执行“command arguments”的结果相似。不过如果“command arguments”的结果含有换行符(和回车符),则在函数shell的返回结果中将它们处理为单个空格,若返回结果最后是换行符(和回车符)则被去掉。
比如当前目录下有文件1.c 2.c 1.h 2.h,则:
c_src := $(shell ls *.c)
结果为 “1.c 2.c”
大家可以在阅读内核、BootLoader、应用程序的Makefile文件时作为手册来查询。
下面以options程序的Makefile作为例子进行演示,Makefile的内容如下:
src := $(shell ls *.c)
objs := $(patsubst %.c,%.o,$(src))
test:$(objs)
gcc -o $@ $^
%.o:%.c
gcc -c -o $@ $<
clean:
rm -f test *.o
上面Makefile中“$@”、“$^”、“$<”称为自动变量。“$@”表示规则的目标文件名;“$^”表示所有的依赖的名字,名字之间用空格隔开;“$<”表示第一个依赖的文件名。“%”是通配符,它和一个字符串中任意个数的字符相匹配。
optoins目录下所有的文件尾main.c Makefile sub.c sub.h,下面来一行行地分析。
(1) 第1行src变量的值为“main.c sub.c”
(2) 第2行objs变量的值为“main.o sub.o”,是src变量经过patsubst函数处理后得到的。
(3) 第4行实际上就是:
test:main.o sub.o
目标test的依赖项为main.o和sub.o。开始时这两个文件还没有生成,在执行生成test的命令之前先将main.o sub.o作为目标查找到合适的规则,以生成main.o sub.o
(4) 第7、8行就是:
main.o:main.c
gcc -c -o main.o main.c
sub.o:sub.c
gcc -c -o sub.o sub.c
这样,test的依赖main.o和sub.o就生成了。
(5) 第5行的命令在生成main.o sub.o后得以操作
在options目录下第一次执行make可以看到如下信息:
gcc -c -o main.o main.c
gcc -c -o sub.o sub.c
gcc -o test main.o sub.o
然后修改sub.c文件,再次执行make命令,可以看到如下信息:
gcc -c -o sub.o sub.c
gcc -o test main.o sub.o
可见,只编译了更新过的sub.c文件,对main.c文件不用再次编译,节省了编译时间
3 常用ARM汇编指令及ATPCS规则
3.1 汇编指令
- 相对跳转指令:b 、bl
这两条指令的不同之处在于bl指令除了跳转之外,还将返回地址(bl的下一条指令的地址)保存在lr寄存器中。
这两条指令的可跳转范围是当前指令的前后32MB
它们是位置无关的指令。
使用示例:
b fun1
......
fun1:
bl fun2
......
fun2:
......
- 数据传送指令mov,地址读取伪指令ldr
mov指令可以把一个寄存器的值赋给另一个寄存器,或者把一个常数赋给寄存器。列子如下:
mov r1,r2
mov r1,#4096
mov指令传送的常数必须能立即数来表示。
当不知道一个数能否用“立即数”来表示时,可以使用ldr命令来赋值。
ldr是伪指令,它不是真实存在的指令,编译器会把它扩展成真正的指令:如果该常数能用“立即数”来表示,则使用mov指令;否则编译时将该常数保存在某个位置,使用内存读取指令把它读出来。
例子如下:
ldr r1,=4097
ldr本意为“大范围的地址读取伪指令”,上面的例子使用它来将常数赋给寄存器r1。下面的例子是获得代码的绝对地址:
ldr r1,=label
label:
......
- 内存访问指令:ldr、str、ldm、stm
注意:ldr指令既可能是前面所述的大范围的地址读取伪指令,也可能是内存访问指令。当它的第二个参数面前有“=”时,表示伪指令,否则表示内存访问指令。
ldr指令从内存中读取数据到寄存器中,str指令把寄存器的值存储到内存中,它们操作的数据都是32位的。示例如下:
ldr r1,[r2,#4] /*将地址为r2+4的内存单元数据读取到r1中*/
ldr r1,[r2] /*将地址为r2的内存单元数据读取到r1中*/
ldr r1,[r2],#4 /*将地址为r2的内存单元数据读取到r1中,然后r2=r2+4*/
str r1,[r2,#4] /*将r1的数据保存到地址为r2+4的内存单元中*/
str r1,[r2] /*将r1的数据保存到地址为r2的内存单元中*/
str r1,[r2],#4 /*将r1的数据保存到地址为r2的内存单元中,然后r2=r2+4
ldm和stm属于批量内存访问指令,只用一条指令就可以读写多个数据。它们的格式如下:
ldm{cond}{!}{^}
stm{cond}{!}{^}
其中{cond}表示指令的执行条件,参考指令的条件码表:往后看!!!
<>addressing_mode表示地址变化模式,有以下4种方式
(1) ia(Increment After):事后递增方式
(2) ib(Increment Before):事先递增方式
(3) da(Decrement After) :事后递减方式
(4) db(Decrement Before):事先递减方式
<>rn中保存内存的地址,如果后面加上了感叹号,指令执行后,rn的值会更新,等于下一个单元的地址。
<>register list表示寄存器列表,对于ldm命令,从<>rn所对应的内存块中取出数据,写入这些寄存器;对于stm指令,把这些寄存器的值写入<>rn所在的内存块中。
{ ^ }有两种含义:如果<>register list中有pc寄存器,它表示指令执行后,spsr寄存器的值将自动复制到cpsr寄存器中——这常用于从中断处理函数中返回;如果<>register list中没有pc寄存器,{ ^ }表示操作的是用户模式下的寄存器,而不是当前特权模式下的寄存器。
指令中寄存器列表和内存单元的对应关系为:编号低的寄存器对应内存中的低地址单元,编号高的寄存器对应内存中的高地址单元
ldm和stm指令示例如下:
HandleIRQ: @中断入口函数
sub lr,lr,#4 @计算返回地址
stmdb sp!,{r0-r12,lr} @保存使用到的寄存器
@r0-r12,lr被保存在sp表示的内存中
@“!”使得指令执行后sp=sp-14*4
ldr lr,=int_return @设置调用IRQ_Handle函数后的返回地址
ldr pc,=IRQ_Handle @调用中断分发函数
int_return:
ldmia sp!,{r0-r12,pc}^ @中断返回,“^”表示将spsr的值复制到cpsr
@于是从irq模式返回被中断的工作模式
@“!”使得指令执行后sp=sp+14*4
- 加减指令:add、sub
例子如下:
add r1,r2,#1 /*表示r1=r2+1,即寄存器r1的值等于寄存器r2的值加上1*/
sub r1,r2,#1 /*表示r1=r2-1*/
- 程序状态寄存器的访问指令:msr、mrs
ARM处理器有一个程序状态处理器(cpsr),它用来控制处理器的工作模式、设置中断的总开关。示例如下:
msr cpsr,r0 /*复制r0到cpsr中*/
mrs r0,cpsr /*复制cpsr到r0中*/
- 其他伪指令
.extern main
.text
.global _start
_start:
“.extern”定义一个外部符号(可以是变量也可以是函数),上面的代码表示本文件中引用的main是一个外部函数。
“.text”表示下面的语句都属于代码段
“.global”将本文件中的某个程序标号定义为全局的,比如上面的代码表示_start是个全局函数
- 汇编指令的执行条件
大多数ARM指令都可以条件执行,即根据cpsr寄存器中的条件标志位决定是否执行该指令:如果条件不满足,该指令相当于一条nop指令
每条ARM指令包含4位的条件码域,这表明可以定义16个执行条件。可以将这些执行条件的助记符附加在汇编指令后,比如moveq、movgt后。
| 条件码(cond) | 助记符 | 含义 | cpsr中条件标志位 |
|---|---|---|---|
| 0000 | eq | 相等 | Z=1 |
| 0001 | ne | 不相等 | Z=0 |
| 0010 | cs/hs | 无符号数大于/等于 | C=1 |
| 0011 | cc/lo | 无符号数小于 | C=0 |
| 0100 | mi | 负数 | N=1 |
| 0101 | pl | 非负数 | N=0 |
| 0110 | vs | 上溢出 | V=1 |
| 0111 | vc | 没有上溢出 | V=0 |
| 1000 | hi | 无符号数大于 | C=1且Z=0 |
| 1001 | ls | 无符号数小于/等于 | C=0或Z=1 |
| 1010 | ge | 带符号数大于/等于 | N=1,V=1或N=0,V=0 |
| 1011 | lt | 带符号数小于 | N=1,V=0或N=0,V=1 |
| 1101 | le | 带符号数小于/等于 | Z=1或N!=V |
| 1110 | al | 无条件执行 | - |
| 1111 | nv | 从不执行 | - |
| 表中的cpsr条件标志位N | 、Z、C、V分别表示Negative、Zero、Carray、oVerflow。 |
影响条件标志位的因素比较多,比如比较命令cmp、cmn、teq及tst等
3.2 ARM-THUMB子程序调用规则ATPCS
为了使C语言程序和汇编程序之间能够互相调用,必须为子程序间的调用制定规则,在ARM处理器中,这个规则被称为ATPCS:ARM程序和Thumb程序中子程序调用规则。
基本的ATPCS规则包含寄存器使用规则、数据栈使用规则、参数传递规则
- 寄存器的使用规则
ARM处理器中有r0 ~ r15共16个寄存器,它们的用途有一些约定的习惯,并依据这些用途定义了别名
| 寄存器 | 别名 | 使用规则 |
|---|---|---|
| r15 | pc | 程序计数器 |
| 14 | lr | 连接寄存器 |
| r13 | sp | 数据栈指针 |
| r12 | ip | 子程序内部调用的scratch寄存器 |
| r11 | v8 | ARM状态局部变量寄存器8 |
| r10 | v7、sl | ARM状态局部变量寄存器7、在支持数据栈检查的ATPCS中为数据栈限制指针 |
| r9 | v6、sb | ARM状态局部变量寄存器6、在支持RWPI的ATPCS中为静态基址寄存器 |
| r8 | v5 | ARM状态局部变量寄存器5 |
| r7 | v5、wr | ARM状态局部变量寄存器4、Thumb状态工作寄存器 |
| r6 | v3 | ARM状态局部变量寄存器3 |
| r5 | v2 | ARM状态局部变量寄存器2 |
| r4 | v1 | ARM状态局部变量寄存器1 |
| r3 | a4 | 参数/结果/scratch寄存器4 |
| r2 | a3 | 参数/结果/scratch寄存器3 |
| r1 | a2 | 参数/结果/scratch寄存器2 |
| r0 | a1 | 参数/结果/scratch寄存器1 |
寄存器的使用规则总结如下:
(1) 子程序间通过寄存器r0 ~ r3来传递参数,这时可以使用它们的别名a1 ~ a4。被调用的子程序返回前无需恢复r0 ~ r3的内容
(2) 在子程序中,使用r4 ~ r11来保存局部变量,这时可以使用它们的别名v1 ~ v8。如果在子程序中使用了它们的某些寄存器,子程序进入时要保存这些寄存器的值,在返回前恢复它们;对于子程序中没有使用到的寄存器,则不必进行这些操作。在Thumb程序中,通常只能使用寄存器r4 ~ r7来保存局部变量。
(3) 寄存器r12用作子程序间scratch寄存器,别名ip
(4) 寄存器r13用作数据栈指针,别名为sp。在子程序中寄存器r13不能用作其他用途,它的值在进入、退出子程序时必须相等
(5) 寄存器r14称为连接寄存器,别名为lr。它用于保存子程序的返回地址。如果在子程序中保存了返回地址(比如讲lr值保存到数据栈中),r14可以用作其他用途
(6) 寄存器r15是程序计数器,别名为pc。它不能用作其他用途
-
数据栈使用规则
数据栈有两个增长方向:向内存地址小的方向增长,称为DESCENDING栈;向内存地址增加的方向增长时,称为ASCENDING栈。
所谓数据栈的增长就是移动指针。当栈指针指向栈顶元素(最后一个入栈的数据)时,称为FULL栈;当栈指针指向栈顶元素(最后一个入栈的数据)相邻的一个空的数据单元时,称为EMPTY栈。
综合这两个特点:数据栈可以分为以下4种
(1) FD:Full Descending,满递减
(2) ED:Empty Descending,空递减
(3) FA:Full Ascending,满递增
(4) EA:Empty Ascending,空递增
ATPCS规定数据栈为FD类型,并且对数据栈的操作是8字节对齐的。使用stmdb/ldmia批量内存访问指令来操作FD数据栈。
使用stmdb命令往数据栈中保存内容时,先递减sp指针,再保存数据,使用ldmia命令从数据栈中恢复数据时,先获得数据,再递增sp指针,sp指针总是指向栈顶元素,这刚好是FD栈的定义 -
参数传递规则
一般来说,当参数个数不超过4个时,使用r0 ~ r3 这4个寄存器来传递参数;如果参数个数超过4个,剩余的参数通过数据栈来传递。
对于一般的返回结果,通常使用a0 ~ a4来传递。
假设CopyCode2SDRAM函数是用C语言实现的,它的数据原型如下
int CopyCode2SDRAM(unsigned char *buf,unsigned long start_addr,int size)
在汇编代码中,使用下面的代码调用它,并判断返回值
ldr r0,=0x30000000 @1.目标地址 = 0x30000000,这是SDRAM的起始地址
mov r1,#0 @2.源地址 = 0
mov r2,#16*1024 @3.复制长度 = 16K
bl CopyCode2SDRAM @调用C函数CopyCode2SDRAM
cmp a0,#0 @判断函数返回值
......
第1行将r0设为0x30000000,则CopyCode2SDRAM函数执行时,它的第一个参数buf的指向的内存地址为0x30000000
第2行将r1设为0,CopyCode2SDRAM函数的第二个参数start_addr等于0
第3行将r2设为16*1024,CopyCode2SDRAM函数的第三个参数size等于16 * 1024
第5行判断返回值
4 几句话解决指针问题
白话文:
先看一张图:

再问大家几个问题!!!
(1) Linux系统有64位、32位之分,那么系统为每个数据类型分配的内存大小是否一样呢?
答:当然不一样嘛,寻址能力不一样对吧,2^64\32,那么为数据类型分配的大小如下:
| 32位 | 64位 |
|---|---|
| sizeof(char) = 1 | sizeof(char) = 1 |
| sizeof(int) = 4 | sizeof(int) = 1 |
| sizeof(char*) = 4 | sizeof(char*) = 8 |
| sizeof(char**) = 4 | sizeof(char**) = 8 |
(2) 变量和指针变量是不是都是变量?又有什么区别呢?
答:它们无非都是变量对不对,就两个代号是不是,每个代号在内存中都有自己的内存单元存放对吧!区别也只是变量所表示的内存区存放的是立即数,而指针变量表示的内存单元存放的是地址对吧!!
(3)立即数和地址有什么关系?
答:立即数不就123456789这些吗,地址不就0xffffffff这类的,一个以十进制表示,一个以十六进制表示,在二进制机器码中不还都是0b10101010.。。。,那么,说白了,变量和变量指针所代表的内存单元存放的不都是0b10101010一样一样的数字啊
(4)如何为指针变量的赋值,和解锁指针变量?
答:区别肯定是有的,char * pa=&a &获取变量a所代表的内存单元的地址,然后赋值给指针变量pa完事。 要想解锁指针,指针变量前面添加个※号就可以改变所指向变量a的内存单元存放的值
(5) 指针是如何访问内存块的呢?
答:我比较喜欢把指针比作一只注射器!针口的大小表示指针的数据类型大小,指向那块内存,就往哪里扎就对了,一扎一个洞,吸一口血(内存数据),想换个位置扎,就挪一个或多个针口大小的位置,继续扎(这不就是偏移量不),爱扎哪就扎哪是不,爱抽血还是注入血我说了算(内存的读取),真是霸气的小护士,指针就是这么简单啊!!
(6) 数据类型 函数 一切的一切,在我们眼里是什么?
答:全是内存块块,既然是内存块,是不是都可以请小护士来扎一扎(数据类型,函数等等,在企业中,一般会把一个模块抽象化成数据块,一个模块的添加,相当于注册一个模块ID),这里你会不会觉得,是不是就是做美容啊,修改内存块完事对吧!!!
还不理解,那就下去看一段代码!!!
#include
void test0()
{
char c;
char *pc;
/*第一步 : 所有变量都保存在内存中,我们打印一下变量的存储地址*/
printf("&c =%p\n",&c);
printf("&pc =%p\n",&pc);
/*第二步:所有变量都可以保存某些值,接着赋值并打印*/
c = 'A';
pc = &c;
printf("c =%c\n",c);
printf("pc =%p\n",pc);
/*第三步:使用指针:1)取值 2)移动指针*/
printf("*pc =%c\n",*pc);
printf("//=================\n");
}
void test1()
{
int ia;
int *pi;
char *pc;
/*第一步 : 所有变量都保存在内存中,我们打印一下变量的存储地址*/
printf("&ia =%p\n",&ia);
printf("&pi =%p\n",&pi);
printf("&pc =%p\n",&pc);
/*第二步:所有变量都可以保存某些值,接着赋值并打印*/
ia = 0x12345678;
pi = &ia;
pc = (char *)&ia;
printf("ia =0x%x\n",ia);
printf("pi =%p\n",pi);
printf("pc =%p\n",pc);
/*第三步:使用指针:1)取值 2)移动指针*/
printf("*pi =0x%x\n",*pi);
printf("pc =%p\t",pc); printf("*pc =0x%x\n",*pc); pc=pc+1;
printf("pc =%p\t",pc); printf("*pc =0x%x\n",*pc); pc=pc+1;
printf("pc =%p\t",pc); printf("*pc =0x%x\n",*pc); pc=pc+1;
printf("pc =%p\t",pc); printf("*pc =0x%x\n",*pc);
printf("//=================\n");
}
void test2()
{
char ca[3]={'A','B','C'};
char *pc;
/*第一步 : 所有变量都保存在内存中,我们打印一下变量的存储地址*/
printf("ca =%p\n",ca);
printf("&pc =%p\n",&pc);
/*第二步:所有变量都可以保存某些值,接着赋值并打印*/
//前面已经有ca[3]={'A','B','C'};
pc = ca;
printf("pc =%p\n",pc);
/*第三步:使用指针:1)取值 2)移动指针*/
printf("pc =%p\t",pc); printf("*pc =0x%x\n",*pc); pc=pc+1;
printf("pc =%p\t",pc); printf("*pc =0x%x\n",*pc); pc=pc+1;
printf("pc =%p\t",pc); printf("*pc =0x%x\n",*pc);
printf("//=================\n");
}
void test3()
{
int ia[3]={0x12345678,0x87654321,0x13572468};
int *pi;
/*第一步 : 所有变量都保存在内存中,我们打印一下变量的存储地址*/
printf("ia =%p\n",ia);
printf("&pi =%p\n",&pi);
/*第二步:所有变量都可以保存某些值,接着赋值并打印*/
//前面已经有ia[3]={0x12345678,0x87654321,0x13572468};
pi = ia;
printf("pi =%p\n",pi);
/*第三步:使用指针:1)取值 2)移动指针*/
printf("pi =%p\t",pi); printf("*pi =0x%x\n",*pi); pi=pi+1;
printf("pi =%p\t",pi); printf("*pi =0x%x\n",*pi); pi=pi+1;
printf("pi =%p\t",pi); printf("*pi =0x%x\n",*pi);
printf("//=================\n");
}
void test4()
{
char *pc="abc";
/*第一步 : 所有变量都保存在内存中,我们打印一下变量的存储地址*/
printf("&pc =%p\n",&pc);
/*第二步:所有变量都可以保存某些值,接着赋值并打印*/
//前面已经有pc="abc";
/*第三步:使用指针:1)取值 2)移动指针*/
printf("pc =%p\n", pc);
printf("*pc =%c\n",*pc);
printf("pc str=%s\n", pc);
}
int main(int argc,char **argv)
{
printf("sizeof(char )=%d\n",sizeof(char ));
printf("sizeof(int )=%d\n",sizeof(int ));
printf("sizeof(char *)=%d\n",sizeof(char *));
printf("sizeof(char **)=%d\n",sizeof(char **));
printf("//=================\n");
//test0();
//test1();
//test2();
//test3();
test4();
return 0;
}
5 几句话解决PC、虚拟机、单板三者之间的网络连接问题
**白话文:**之所以叫虚拟机,也就是说不是真实存在的电脑,只是虚拟了计算机系统的结构,虚拟网卡等等,所有的资源都是宿主机,那么要想虚拟机网络导通,至少的有一个虚拟网卡与宿主机的物理网卡桥接上,形成一条网路,无论是宽带还是无线,虚拟机与宿主pc机之前,只需要一种网络连通!关闭另外的网卡网络,只留下一条,这样pc机和虚拟机可以互相ping通,与开发板的ip设置为同一网段,即可三者相互ping通完事!!!
6 教你快速学会看芯片手册及原理图
**白话文:**快速有效的查看芯片手册的方法:既然都知道操作单板都是操作相应的寄存器,那么为什么不先去查阅总体的寄存器地址分配表呢!很多人都喜欢用到那个外设再去查看那块的寄存器相关,貌似都行得通,如果你想发展更长远,你不应该先总览芯片的寄存器地址吗????
不仅可以快速了解单板有哪些外设,每个外设有哪些寄存器来控制,在后续研发的时候不都会用到对吧!
之后的研发阶段中可以再一对一地去看对应的外设寄存器相关,如鱼得水!!!
原理图:根据芯片手册的寄存器标号在原理图中找到对应标号,最后找到对应芯片引脚标号完事
7 Linux比较重要的命令详解
**白话文:**一些平常编辑查找之类的命令咋们这里没必要了解太多,无非就是在纸上如何去画画,下面只讲解与编译内核相关的命令。
- tar命令
tar命令具有打包、解包、压缩、解压缩4种功能
常用的压缩、解压缩方式有两种:gzip、bzip2
一般而言,以“.gz”、“z”结果的文件是用gzip方式进行压缩的,以“.bz2”结尾的文件是bzip2方式进行压缩的,后缀名中有“tar”字样时表示这是一个文件包
tar命令有5个常用选项:
(1) “c”:表示创建,用来生成文件包
(2) “x”:表示提取,从文件包中提取文件
(3) “z”:使用gzip方式进行处理,它与“c”结合就表示压缩,与“x”结合就表示解压缩
(4) “j” :使用bzip2方式进行处理,它与“c”结合就表示压缩,与“x”结合就表示解压缩
(5) “f” :表示文件,后面接着一个文件名
以例子说明tar命令的使用方法
A:将某个目录dirA制作为压缩包
tar czf dirA.tar.gz dirA //将目录dirA压缩为文件包dirA.tar.gz,以gzip方式进行压缩
tar cjf dirA.tar.bz2 dirA //将模流dirA压缩为文件包dirA.tar.bz2,以bzip2方式进行压缩
B:将某个压缩包文件dirA.tar.gz解开
tar xzf dirA.tar.gz //在当前目录下解开dirA.tar.gz,先使用gzip方式解压缩,然后解包
tar xjf dirA.tar.bz2 //在当前目录下解开dirA.tar.bz2,先使用bzip2方式解压缩,然后解包
tar xzf dirA.tar.gz -c //将dirA.tar.gz解开到目录下
tar xjf dirA.tar.gz -c //将dirA.tar.bz2解开到目录下
- diff、patch命令
diff命令常用来比较文件、目录,也可以用来制作补丁文件。所谓“补丁文件”就是“修改后的文件”与“原始文件”的差别
常用的选项如下:
(1) “-u”:表示在比较结果中输出上下文中一些相同的行,这有利于人工定位
(2) “-r” :表示递归比较各个子目录下的文件
(3) “-N”:将不存在的文件当作空文件
(4) “-w”:忽略对空格的比较
(5) “-B”:忽略对空行的比较
例如:假设linux-2.6.22.6目录中是原始的内核,linux-2.6.22.6_ok目录中是修改过的内核,可以使用以下命令制作补丁文件linux-2.6.22.6_ok.diff(原始目录在前,修改过的目录在后)
diff -urNwB linux-2.6.22.6 linux-2.6.22.6_ok > linux-2.6.22.6_ok.diff
由于linux-2.6.22.6是标准的代码,可以从网上自由下载,要发布linux-2.6.22.6_ok中所作的修改时,只需要提供补丁文件linux-2.6.22.6_ok.diff(它通常是很小的)
patch命令被用来打补丁——就是依据补丁文件来修改原始文件。比如对于上面的例子,可以使用以下命令将补丁文件linux-2.6-22.6_ok.diff应用到linux-2.6.22.6上去。假设linux-2.6.22.6_ok.diff和linux-2.6.22.6位于同一目录下
cd linux-2.6.22.6
patch -p1 < ../linux-2.6.22.6_ok.diff
patch命令中最重要的选项是“-pn”:补丁文件中指明了要修改的文件的路径,“-pn”表示忽略路径中第n个斜杆之前的目录。假设linux-2.6.22.6_ok.diff中有如下几行:
diff -urNwB linux-2.6.22.6/A/B/C.h linux-2.6.22.6_ok/A/B/C.h
--- linux-2.6.22.6/A/B/C.h 2007-08-31 02:21:01.000000000 -0400
+++ linux-2.6.22.6_ok/A/B/C.h 2007-09-20 18:11:16.000000000 -0400
......
使用上述命令打补丁时,patch命令根据“linux-2.6.22.6/A/B/C.h”寻找源文件,“-p1”表示忽略第1个斜杆之前的目录,所以要修改的源文件是当前目录下的:A/B/C.h
//坚持到这一步,慢慢品尝,不懂的可以稍稍带过,下一文,咋们来玩俄罗斯方块!!!