libevent高性能网络库源码分析——Reactor模式(二)
-
-
- IO模型介绍
- Reactor模式
-
IO模型介绍
在介绍libevent的Reactor模式之前,首先介绍下IO模型的:
1、 同步阻塞IO(Blocking IO):
即传统的IO模型。当用户进程向系统发起read操作时,首先需要在内核中数据准备和内核态到用户进程的数据拷贝。当两个步骤都完成后,才会返回read结果状态,才能执行后续的数据处理操作。
{
read(socket, buffer);
process(buffer);
}2、 同步非阻塞IO(Non-blocking IO)
默认创建的socket都是阻塞的,非阻塞IO要求socket被设置为NONBLOCK。当用户进程向系统发起read操作时,立即返回,但此时并没有读取到数据。用户线程需要不断地发起read请求,并根据返回的结果是否完成状态,来确定是否完成read操作。
while(read(socket, buffer) == SUCCESS) {
process(buffer);
}在非阻塞式IO中,用户进程需要不断的主动询问数据准备好了没有,需要消耗过多的CPU 资源。
3、 IO多路复用(IO Multiplexing)
即经典的Reactor设计模式,有时也称为异步阻塞IO,Java中的Selector和Linux中的epoll都是这种模型。以下以select为例进行说明。使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额外操作,效率更差。但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个socket,然后不断地调用select读取被激活的socket,即可达到在同一个线程内同时处理多个IO请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
{
select(socket);
while(1) {
ready_sockets = select();
for(socket in ready_sockets) {
if(can_read(socket)) {
read(socket, buffer);
process(buffer);
}
}
}
}4、 异步IO(Asynchronous IO)
即Proactor设计模式,也称为异步非阻塞IO。用户进程发起read操作之后,立刻就可以开始去做其它的事。而内核在接收到asynchronous read之后,内核会进行数据准备和数据拷贝至用户内存,当这两个步骤都完成后,内核会给用户进程发送一个signal,通知read操作完成。这一过程不会对用户进程产生任何block。
相比于IO多路复用模型,异步IO并不十分常用,不少高性能并发服务程序使用IO多路复用模型+多线程任务处理的架构基本可以满足需求。况且目前操作系统对异步IO的支持并非特别完善,更多的是采用IO多路复用模型模拟异步IO的方式(IO事件触发时不直接通知用户线程,而是将数据读写完毕后放到用户指定的缓冲区中)
下面用一张图区别四种模型的区别:
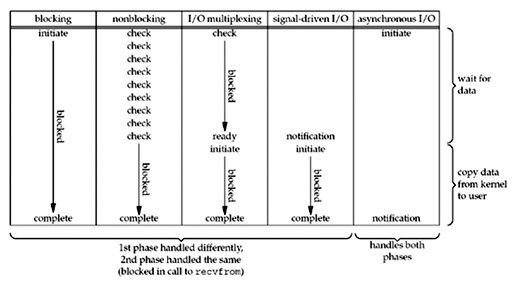
由上图可知,在non-blocking IO中,虽然进程大部分时间都不会被block,但是它仍然要求进程去主动的check,并且当数据准备完成以后,也需要进程主动将数据拷贝到用户内存。I/O multiplexing中虽然在数据准备阶段和数据拷贝阶段会被block,由于其基于事件通知的,避免了持续check数据是否。而asynchronous IO则完全不同。它就像是用户进程将整个IO操作交给了内核去完成,然后等待信号通知,用户进程不需要检查IO操作的状态,也不需要主动的去拷贝数据。
Reactor模式
优点如下:
Reactor 模式是编写高性能网络服务器的必备技术之一,它具有如下的优点:
- 响应快,不必为单个同步时间所阻塞,虽然 Reactor 本身依然是同步的;
- 编程相对简单,可以最大程度的避免复杂的多线程及同步问题,并且避免了多线程/
进程的切换开销; - 可扩展性,可以方便的通过增加 Reactor 实例个数来充分利用 CPU 资源;
- 可复用性, reactor 框架本身与具体事件处理逻辑无关,具有很高的复用性
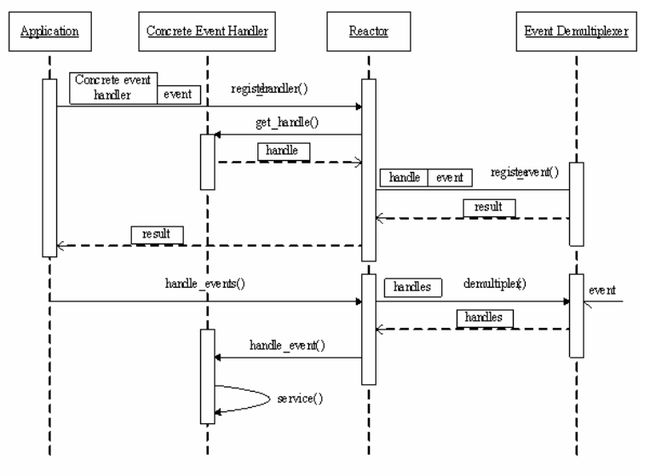
下图描述了Reactor模式的框架,主要包括:事件源、框架部分(Reactor)、事件多路分发机制(event demultiplexing)、事件处理程序(event handler)。

1、事件源:Linux 上是文件描述符, Windows 上就是 Socket 或者 Handle 了,这里统一称为“句柄集”;程序在指定的句柄上注册关心的事件,比如 I/O 事件。
在libevent中有三种类型的事件:定时器事件(time event)、信号事件(signal event)和I/O事件。
2、事件多路分发机制(event demultiplexing)
需要使用底层提供的多路复用机制,如evport, select , poll, epoll, kqueue, devpoll. 用户进程首先在event demultiplexing上注册事件,采用合适的多路复用机制检测事件,当事件发生时,event demultiplexing发出通知“在已经注册的事件集中,一个或多个事件已经就绪“,程序收到通知后对事件进行处理。
1)libevent中对多路复用机制进行了封装,使得根据操作系统,可以选择最高效的IO机制。
static const struct eventop *eventops[] = {
#ifdef _EVENT_HAVE_EVENT_PORTS
&evportops,
#endif
#ifdef _EVENT_HAVE_WORKING_KQUEUE
&kqops,
#endif
#ifdef _EVENT_HAVE_EPOLL
&epollops,
#endif
#ifdef _EVENT_HAVE_DEVPOLL
&devpollops,
#endif
#ifdef _EVENT_HAVE_POLL
&pollops,
#endif
#ifdef _EVENT_HAVE_SELECT
&selectops,
#endif
#ifdef WIN32
&win32ops,
#endif
NULL
};2)事件注册:
首先,对event进行初始化,并将event与event_base(可以理解为事件库)关联起来,如下:
event_new(struct event_base *base, evutil_socket_t fd, short events, void (*cb)(evutil_socket_t, short, void *), void *arg)其中cb表示事件处理函数,也即回调函数,需要用户实现。
然后,将事件添加到事件库,此时event的状态为pending:
int event_add(struct event *ev, const struct timeval *tv);
3)事件触发:
在事件加入event_base后,选择合适的多路复用机制遍历事件队列,将状态为激活(active)的事件插入到激活队列中,从高到低优先级遍历激活event优先级数组。对于激活的event,调用event_queue_remove将之从激活队列中删除掉。然后再对这个event调用其回调函数。
整个Reactor的流程如下:
本文参考:
1. 高性能IO模型浅析
2. IO - 同步,异步,阻塞,非阻塞 (亡羊补牢篇)
3. libevent源码深度剖析