多线程并发原子性,可见性,有序性分析
目录
1.什么是多线程并发?
2.机器内存分配及线程对内存操作(操作示例)
2.1机器内存分配
2.2线程对内存操作
3.解决多线程并发问题
多线程的三个特性:
a.原子性
是指一个操作是不可中断,即使多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程干扰;简单看几个例子:
1)int x=10; 2)int y=x; 3)x++; 4.x=x+1;
这上面四个语句,区分哪些是原子操作,哪些非原子操作?
1)第一句,直接把10赋值给x的工作内存,这个操作是不可再分的,并且很直接,这就是原子操作;
2)第二句,先读取x的值,然后将x的值写入到y的工作内存,这个可分割,并且不直接,这就不是原子操作 ;
3)第三句,其实和第四句一样都是执行x+1;先读取x的值,然后进行+1操作,才会将新值写入x的工作内存;
所以可以看出来,所谓的原子操作,原子性就是直接对一个变量进行操作,中间没有别的操作(实际指的是操作不可分割性);
b.可见性
是指当线程1修改某一个共享变量的值,线程1修改完成以后,线程2能够立即知道修改完成后共享变量的值,那么说明是可见的;可见性就是说线程之间操作共享变量时,彼此之间都知道;
c.有序性
有序性就是指执行代码是有序去执行,线程1先执行,完了之后线程2再去执行;
1.什么是多线程并发?
在Android或者Java开发中,遇到多线程并发问题的时候次数比较多,多线程并发是指多条线程共同访问同一个数据源时,往往不能得到预期结果;产生无法获取预期结果的原因是什么?其实就是该共同访问数据源对多线程没有可见性,这些线程不能有序性的去操作共同的数据源,还不是原子操作,所以导致预期结果不一样;
2.机器内存分配及线程对内存操作(操作示例)
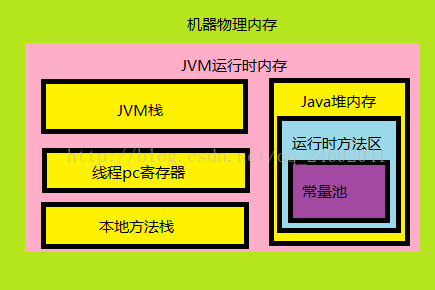
2.1机器内存分配
2.2线程对内存操作
在“机器内存分配”图可以看到JVM栈也就是Java虚拟机栈,每个线程启动都会有一个线程栈,线程栈保存了线程运行时的变量信息,当线程访问某个值的时候先通过这个值的引用在堆内存中找到这个值,然后load到线程本地内存中,创建一个变量副本,然后就跟这个值本身没有任何关系了,而是对副本进行操作,在一个时刻(线程结束之前)将修改好的值写入到堆内存中,如下图:
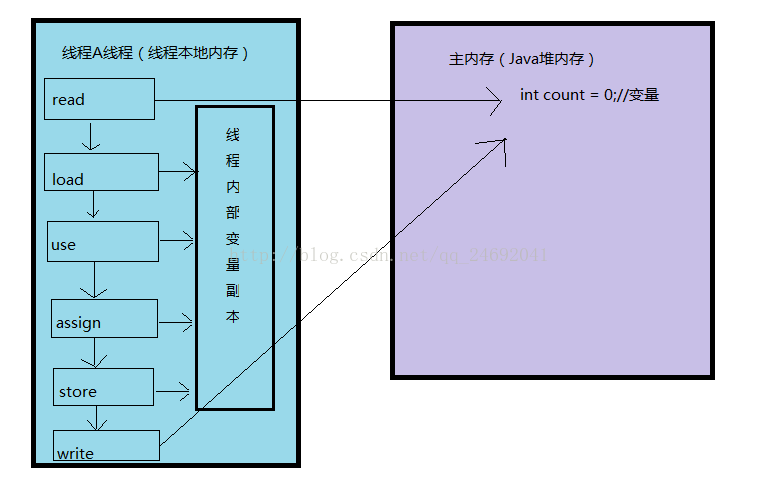
示例如下:
定一个1000个线程同时执行,将共享变量执行+1操作,然后看效果:
/**
* 多线程测试
*/
public class ManyThreadTest {
public static void main(String[] args){
for (int i=0; i<1000; i++){
new Thread(){
@Override
public void run() {
addOne();
}
}.start();
}
}
public static int count = 0;
public static void addOne(){
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
count++;
System.out.print("addOne count :" + count + "\n");
}
}输出结果部分截图:

定义共享变量count=0,同时启动1000个线程,每次执行+1操作,预期结果count=1000;我们通过日志查看实际结果count并没有计算出正确的结果,那是为什么呢?实际例如线程1执行+1操作,会去堆(主)内存中获取count值0,取过来之后会在自己线程栈创建一个副本 ,操作的是这个副本执行+1操作,直到最后操作完成才会去更新堆内存中的count,操作结果count为1;这时如果线程1还没操作完成,这是线程2执行+1操作,会去堆(主)内存中获取count值0,取过来之后会在自己线程栈创建一个副本 ,操作的是这个副本执行+1操作,操作结果count为1;这是线程1和线程2都操作完成,线程1和线程2的count副本都是1,线程1和线程2分别会将count副本值写入堆内存中,最后堆内存中count值为1;实际我们预期的结果堆内存count为2;我们调试代码发现执行完1000个线程以后count值不是1000,输出日志发现count值不是固定的,会发现count输出值还可以重复例如980,并且杂论无章;
根据上面的解释和代码运行的效果,可以得出一个结论,线程并发导致得不到我们预期的结果的主要原因,因为每个线程不能确定谁先执行,也不能确定是什么时候执行,并且他们操作的变量还不是直接操作的堆内存中的同一个值进行原子操作,而是操作内部的副本,操作完成之后再去改变堆内存中得到值;
上面我们引入了原子性,可见性,有序性;
3.解决多线程并发问题
通过1000个多线程并发操作count变量,会发现并发导致哪些问题?也分析多线程并发为什么会导致这个结果?那如何去解决呢?要解决并发问题,就要解决原子操作,可见性,有序性问题;
可见性:可见性意思就是说所有访问volatile修饰的变量的线程都能知道该变量的改变;
Java提供volatile修饰,volatile相当于一个轻量级synchronized修饰符,volatile保证变量的可见性;也即是说不允许线程将volatile修饰的变量缓存到线程栈中,每一次取值必须在Java堆中取到数据。但是这样并不能保证线程安全,因为只是解决了可见性,并没有解决原子性。比如说线程1取到count的值是0,正在进行+1操作,但是还没操作完,这时候线程1还是没有将count值改为1,这时候线程2去取count这个值了,这时候他取到的值还是0,并不是1;
另外synchronized和Lock也能保证可见性,因为共享代码块被锁起来,如果我们释放锁的时候,是在将线程栈中副本值写入堆内存中之后,那就能保证每一个线程拿到的值是最新的,这种一般我们用的比较多;
另外volatile使用有一定的限定条件:
1)对该变量的写操作不依赖于该变量的当前值;
2)该变量没有包含在具有其他变量的可变式中;
原子性:上面已经说了什么是原子操作,原子性,并且知道线程操作共享数据是一组操作合在一块,并不是原子操作,你那么怎么保证一组操作是原子操作呢?那还是用到synchronized或者Lock,将共享代码上锁,必须等到副本的值写入到堆内存之后才能释放锁给下一个线程使用;
有序性:synchronized和Lock的正确使用能到达互斥效果,能保证同一时间只能有一个线程或者可以控制有几个线程在访问共享代码块,从而到达有序性;
更改代码保证原子性,可见性,有序性:
通过Lock或者synchronized实现解决原子性,可见性,有序性相关问题;
public class Application {
private static ReentrantLock lock = new ReentrantLock();
private static Semaphore semaphore = new Semaphore(10);
public static int count = 0;
public static void main(String[] args) {
// System.out.println("启动SpringBoot");
for(int i=0; i<1000; i++) {
new Thread() {
public void run() {
addOne();
}
}.start();
}
}
public static void addOne() {
try {
semaphore.acquire();
lock.lock();
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
count++;
System.out.println("ThreadName = "+Thread.currentThread().getName()+"; count = "+count);
lock.unlock();
semaphore.release();
} catch (InterruptedException e1) {
e1.printStackTrace();
}
}
// public synchronized static void addOne() {
// try {
// try {
// Thread.sleep(1);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
// count++;
//
// System.out.println("ThreadName = "+Thread.currentThread().getName()+"; count = "+count);
// } catch (InterruptedException e1) {
// e1.printStackTrace();
// }
// }
}输出结果日志:

可以看到输出日志线程可以有序执行,预期结果输出为1000,没有出现杂论无章的情况;
Semaphore介绍:
Semaphore(信号量)是用来控制同时访问特定资源的线程数量,它通过协调各个线程,以保证合理的使用公共资源。很多年以来,我都觉得从字面上很难理解Semaphore所表达的含义,只能把它比作是控制流量的红绿灯,比如XX马路要限制流量,只允许同时有一百辆车在这条路上行使,其他的都必须在路口等待,所以前一百辆车会看到绿灯,可以开进这条马路,后面的车会看到红灯,不能驶入XX马路,但是如果前一百辆中有五辆车已经离开了XX马路,那么后面就允许有5辆车驶入马路,这个例子里说的车就是线程,驶入马路就表示线程在执行,离开马路就表示线程执行完成,看见红灯就表示线程被阻塞,不能执行。
在代码中,虽然有1000个线程在执行,但是只允许10个并发的执行。Semaphore的构造方法Semaphore(int permits) 接受一个整型的数字,表示可用的许可证数量。Semaphore(10)表示允许10个线程获取许可证,也就是最大并发数是10。Semaphore的用法也很简单,首先线程使用Semaphore的acquire()获取一个许可证,使用完之后调用release()归还许可证。还可以用tryAcquire()方法尝试获取许可证。
Semaphore应用场景:
Semaphore可以用于做流量控制,特别公用资源有限的应用场景,比如数据库连接。假如有一个需求,要读取几万个文件的数据,因为都是IO密集型任务,我们可以启动几十个线程并发的读取,但是如果读到内存后,还需要存储到数据库中,而数据库的连接数只有10个,这时我们必须控制只有十个线程同时获取数据库连接保存数据,否则会报错无法获取数据库连接。这个时候,我们就可以使用Semaphore来做流控;
参考:
https://blog.csdn.net/qq_24692041/article/details/60756077
http://ifeve.com/concurrency-semaphore/